


- 文\李承叡│台灣大學生態學與演化生物學研究所&植物科學研究所
好奇過餐桌上的苦瓜是哪來的嗎?你知道除了苦瓜排骨湯常用的白玉苦瓜和常拿來炒鹹蛋的綠苦瓜,還有各式不同大小、顏色、及形狀的苦瓜嗎?要破解這些問題,許多珍貴的遺傳資源平時就儲藏在農作物種原中心,等著我們去挖掘!
台灣大學的李承叡老師團隊近期和日本研究者以及亞蔬–世界蔬菜中心合作,一同破解了苦瓜的基因體序列,並利用種原中心的收藏,揭開苦瓜不為人知的歷史!
從基因體序列分析發現,苦瓜野生祖先與栽培品系大約在六千年前分家,表示栽培用苦瓜大概在那個時候開始被馴化。栽培品系又可分為南亞(印度、孟加拉)與東南亞(包含東亞苦瓜)兩大群,前者含有較多的遺傳多樣性,顯示印度次大陸是苦瓜的馴化起源中心。大約在八百年前,東南亞族群又從南亞分化出來。

苦瓜的馴化:一個非典型的故事
野生植物很難被人類直接利用(=不好吃)。廣義來說,馴化指的是人類主動從野生物種的多樣性中挑選出人們喜好的性狀,進而將這些品系形塑成便於人類利用的樣子。
經過農夫們數千年的篩選,農作物最後常會擁有與野生祖先型完全不同的樣貌。最有名的例子是玉米與它的祖先大芻草 (teosinte) :相較於玉米,大芻草植株的分枝多、每一果穗上的果粒少、果粒堅硬,與今日皮薄多汁的玉米差異非常大。
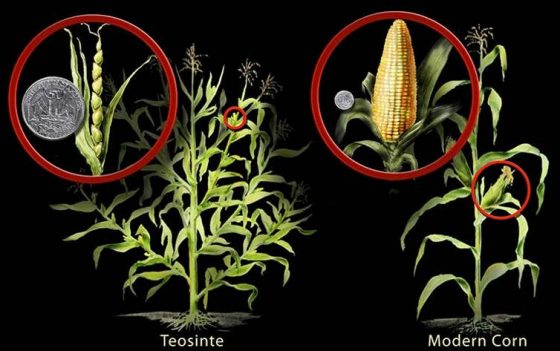
相較於野生苦瓜(果實頂多五公分長、重十多公克),大家熟悉的白玉苦瓜(屬於東南亞族群)果實可以超過二十公分、重達數百公克。這之間的差異當然是由長年強烈又具有單一方向性(增加果實大小)的人為選擇造成的。
但苦瓜的故事其實頗為複雜!除了白玉苦瓜,世上有許多不同的栽培苦瓜品系:果實從小到大、顏色從深綠到白、果皮從光滑到充滿稜脊。再加上遺傳資訊細究下來,有些品系的遺傳背景屬於栽培族群,但果實外貌像野生的。甚至有些人會把野生苦瓜直接拿來栽培,因為喜歡它的強烈苦味。
所以當我們把視野放寬,看到各種連續性的變異之後,所謂野生 vs. 栽培品系的概念在苦瓜身上似乎就變得比較模糊了。

苦瓜這樣多變化的差異很可能跟人們的不同喜好有關:相較於東南亞,南亞的人偏好較小(雖然還是比野生品系大)、苦味較強的苦瓜。在農作物馴化的過程中,人擇引導作物改變的方向。當人們對作物的偏好不一致、沒有強烈又單一方向的選擇的時候,各式栽培品系就會被人們的不同喜好形塑地更多樣了。
以後當你想問「為什麼不把苦瓜育種成完全不苦」的時候,別忘記了,其實有不少人是因為它的苦味才去吃它的喔!
為什麼性狀可以這麼多變?「遺傳架構」的排列組合
大家一定都對國中學過的孟德爾遺傳定律很熟悉:單一基因控制單一性狀的類別性差異。類別性就是非 A 即 B 的基因表現,比如,一個基因的突變就能把髮色從黑變褐。
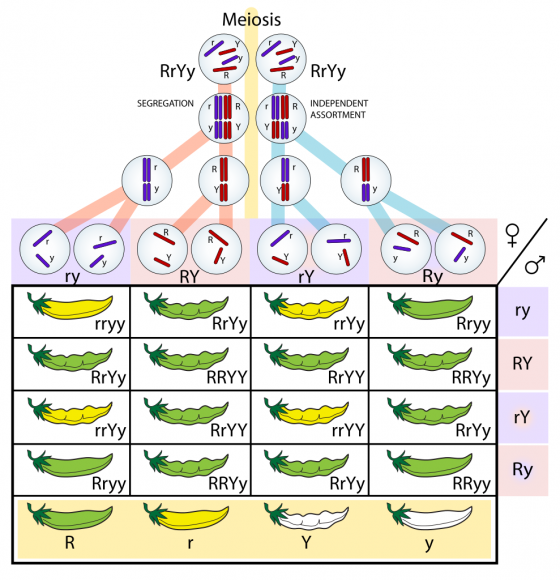
但其實這在自然界中只是特例,自然界絕大部分的性狀都是數量性、連續性,比如我們的身高和體重;而不是類別性的。許多數量性狀是由多個基因一起控制:有的基因影響較大,有的影響較小。一個性狀到底由多少基因控制,每個基因又有多大的影響?這就是每個性狀不同的遺傳架構 (genetic architecture) 。
那麼玉米與大芻草的例子,是因為科學家們只看到了連續性差異的兩個極端嗎?
許多經典的馴化性狀都是類別性的,比如從大芻草的植株多側芽到玉米的單一主莖;或是野生水稻成熟後會落粒,而栽培水稻品系不會。這些類別性的外表差異通常是典型的孟德爾性狀,而且科學家們也已經找出控制這些性狀的單一突變。所以這些農作物馴化的典型例子,並不是因為科學家們只關注連續性差異的兩個極端,而是因為這些性狀本身的遺傳架構就偏向孟德爾遺傳。
實際的研究討論中,性狀本身是屬於哪種遺傳架構,是屬於數量性、連續性的變化,亦或是類別性的差異,以及人們實際上的偏好是否明確,都對作物馴化最後的表現有很大的影響。
你說的苦瓜,是怎麼樣的苦瓜?
因此在苦瓜這個非典型的馴化的例子中,事情並沒有我們想像的那麼簡單!如前所述,不同地區的人們可能會有不同的食用偏好,這也造成不同基因型會在不同的地區被選拔下來。
從果實型態來說,東南亞的栽培族群型態比起野生或南亞栽培族群更加極端(果實更大、顏色更淺、表面更光滑)。透過基因體資訊,我們也發現東南亞栽培族群在與南亞族群分開後,近一千年內受到強大的人為選擇壓力。
南亞栽培族群雖然早在數千年前就與野生祖先型分家,我們卻無法從基因體資訊偵測到針對性狀的強烈人擇,這可能也跟當地人們並不特別偏好又大又白的苦瓜有關,而苦瓜果實大小是個多基因遺傳的性狀。
有趣的是,我們發現在東南亞族群受到強烈人擇篩選的幾乎都是對性狀影響較小的基因。換言之,在未來有可能透過進一步的育種,篩選出對性狀影響較大的這些基因!
演化基因體學 + 農作物種原多樣性,蹦出育種新滋味
筆者之前的研究為演化基因體學,利用基因體資訊重建族群過去的歷史,並找出影響物種演化的重要基因。目前與各國農作物種原中心合作,希望探究亞洲農作物的馴化歷史以及對獨特環境的適應性。最後更希望能從研究農作物種原多樣性的過程中,找到育種改良的契機。
筆者最後要感謝科技部年輕學者養成計劃(哥倫布計畫)的大力支援,讓筆者團隊得以利用跨領域的知識展開新的研究方向。
論文原文請見:Long-read bitter gourd (Momordica charantia) genome and the genomic architecture of domestication







































{kind=link}