


- 文/張智皓
「在演算法的年代,人類從未如此刻這般的重要。」——弗萊(Hannah Fry)
圖靈(Alan Turing)在 1936 年提出圖靈機(Turing Machine)的基本構想,人類文明揭開了電腦時代的序幕,並在很短時間內為人類生活帶來了劇烈的變化。上一次有這樣的景況,大概是 17 世紀末蒸汽機的發明,帶領人類文明進入工業時代。

這兩個時代有類似之處。蒸汽機讓人開始擔心自己被機械取代:生產模式改變,人力不再重要,生產機器和失業人口大量出現。然而,這種困境並沒有維持太久。新技術讓人失業,也拓展了人的想像力,讓各種新興行業與技術應運而生。這些行業和技術促進產業轉型,反而提高了人力需求,讓人類文明變得更加繁盛。此時,我們知道人類變得比以前更重要。
電腦,或者我們說,演算法,就像是現代的蒸氣機,同樣大幅地改變人類生活模式。在本書中,倫敦大學學院(UCL)先進空間分析中心(CASA)的數學家漢娜弗萊從權力、資料、司法、醫療、車輛、犯罪與藝術這七個面向出發,告訴我們演算法已經如何深入我們日常生活中,為我們帶來前所未見的巨大貢獻,並展現出取代人類的企圖心。

更重要的是,弗萊也透過她細膩的觀察,提醒我們:就如同蒸汽機時代的人類沒有被取代一樣,在演算法時代,人類也只會比以前更重要。
人機合作,讓人類的棋藝再創高峰
讓我們從書中一個輕鬆的例子開始。弗萊告訴我們,在 1997 年,西洋棋世界冠軍卡斯帕洛夫(Gary Kasporov)被 IBM 設計的「深藍」擊敗後,他並沒有因此排斥電腦,反之,他創辦了人類與電腦合作的棋賽。卡斯帕洛夫相信,有了電腦的輔助,人類不再需要花時間在棋盤細節的計算上,而是將心思放在整體戰略上,人機合作,能讓人類的棋藝再創高峰。
這樣的劇情非常類似於 DeepMind 的圍棋軟體 AlphaGo 在 2016 年的創舉。在 AlphaGo 相繼打敗世界冠軍李世乭以及柯潔後,AlphaGo 以及其繼任 AlphaGo Zero 的棋譜變成職業選手們爭相學習的目標。DeepMind 甚至推出 AlphaGo 圍棋教學工具,讓大家學習它的佈局,並進而開發出新的佈局形式。AlphaGo 沒有取代人類棋手,反之,它為圍棋世界注入了新的生命。

演算法無法回答的問題:隱私與安全該如何平衡
接著讓我們談談一個較嚴肅的例子。在本書「犯罪」這一章節中,弗萊提到「臉孔辨識系統」如何對人類產生顯而易見的貢獻。在 2015 年,紐約警察局透過臉孔辨識系統「成功指認了 1700 名嫌犯,並且發動了 900 次逮捕行動。」另外,她也提到從 2010 年以來,紐約州「僅僅針對詐欺和身分盜用就發動了超過四千次逮捕行動。」有了臉孔辨識系統,各大交通運輸管道也可藉恐怖份子資料庫來預防恐怖襲擊(而事實證明這很有用)。

作為預防手段,臉孔辨識系統可以有效增進人們生命與財產之安全。但這些好處有其代價。弗萊指出,就連目前全世界最先進的臉孔辨識系統(來自於中國的「騰訊優圖實驗室」),在一百萬張臉孔資料庫的測試中,也只有 83.29% 的辨識率。這在技術上已經令人佩服,但在現實中卻可能釀成大禍。
比方說,2014 年,一位住在丹佛的居民被錯誤辨識為銀行搶匪,並在警察的逮捕過程中「遭受神經損傷、血栓及陰莖折斷。」或許有人會主張,只要技術更好,辨識率更高,問題就解決了。但情況可能沒這麼簡單,辨識率提高的代價是隱私度的下降。試問,我們願意讓「老大哥」看著大家嗎?
臉孔辨識系統有其好處,有其代價。我們願意讓此系統做到甚麼程度?為了安全,我們願意犧牲多大的隱私?而為了隱私,我們又願意犧牲多少安全?這些問題是演算法無法回答的,只有人類可以,因此,人類只會更重要。
演算法兩難:自駕車該拯救駕駛還是行人?
另外一個嚴肅例子,我想談談「車輛」這一章節中的自動駕駛技術。一旦自動駕駛技術普及,將可以大幅減少人為車禍的發生。而我們知道,現代大多數車禍都源於人為。然而,將駕駛工作交給演算法,也意味著將決策的任務交給演算法。當失控的自駕車面臨的選項是「拯救駕駛,還是拯救行人」時,演算法應該如何行動?
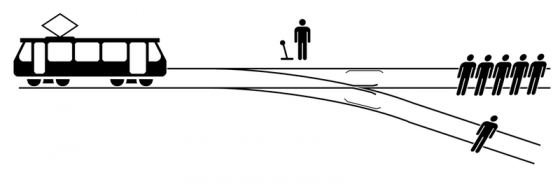
弗萊提到,在 2016 年發表於《科學》期刊(Science)的一篇文章指出,多數人主張應該盡可能的拯救更多人命。然而,當詢問他們自身較願意購買哪一款自駕車時,我們可以從賓士汽車發言人胡苟(Christoph von Hugo)的回應(當被問到賓士車會如何設計時),理解他們的猶豫:「保護駕駛。」
這衝突看起來不可調和,我們一方面希望盡可能拯救人命,另一方面又希望可以保障駕駛的安全(否則我幹嘛買它呢?)。在這樣的衝突中,弗萊指出另外一個可能選項:放棄全自動駕駛,將演算法的目標放在輔佐駕駛人上(比方說,現在已有的「自動緊急煞車」或「自動與前車保持距離」等設計)。換言之,演算法不扮演「司機」,而是扮演「守護者」。我們該做的,是讓演算法配合人類,主動性依然在人類手上,因此,人類只會更重要。

在《打開演算法黑箱》中,弗萊透過大量有趣的案例,說明演算法如何深入日常的同時,也提醒我們人類的重要性,這是我認為本書最大的優點。新技術的提出值得受到肯定,然而,在肯定其貢獻的同時,背後所付出代價卻往往會被忽略。本書在闡述新技術的同時,也很平衡地展示這些技術背後的代價。
就如同作者一再強調的,她肯定技術所帶來的好處,但我們必須思考如何在新技術所帶來的進步中,保有人類的主動性,或者說,如何在機器年代中當個人。

本文為《打開演算法黑箱:反噬的AI、走鐘的運算,當演算法出了錯,人類還能控制它嗎?》書評






























-200x200.jpg)













{kind=link}