在 2016 年接連發生的兩起黑天鵝事件:英國公投脫歐、川普當選美國總統,讓眾人將目光跟舌根都轉向了「假新聞」。許多牌子老、信用(可能)好的新聞媒體批評 Facebook、Twitter、Google 等網路大公司根本是假新聞的天堂,讓眾多背景不明、沒有真的記者、資料不清不楚的假新聞機構,不僅得以大肆散播偽裝成新聞的宣傳戰,以偏頗的評論取代查證過的事實,還可藉此大賺廣告費。
然而「假新聞」一詞很快就喪失意義。現在只要政客不同意任何一則新聞內容,他們就稱其為假新聞。因此透過研究,正確地定義出哪些新聞是假新聞、這些假新聞流傳地有多廣、選民在選舉期間如何與假新聞互動(特別是在社群媒體上),便是阻止各方繼續打爛仗的唯一方式。英國牛津大學網路研究所(Oxford Internet Institute)的研究團隊決定以 Twitter 上的推文為對象進行分析,把事情講清楚說明白(點開看論文)。

研究方式很簡單,分成四部分:
- 取得 2016 年 11 月 1 日到 11 月 11 日這段期間,含有跟美國政治以及選舉有關的 #hashtag 的推文,總共 2千2百萬則。
- 接著根據使用者的資料,篩選出發送位址位於密西根州的推文。選密西根的原因是這州選民在選前對兩位主要候選人柯林頓與川普的支持度不分軒輊。這樣挑出來的推文有 138,686 則。
- 然後再從這些推文中,篩選出有分享網路鏈結的推文,共有 25,339 則。
- 最後就是去編碼。
首先,他們發現在 138,686 則密西根人的政治選舉相關推文中,挺川普的推文超過一半以上(56.7%),遠多於挺柯林頓的兩成(20.3%)。可見川普真的是推特總統。
另一個點是,他們原本預期會發現很多機器推文,但可能是因為限定密西根州的原因,機器推文佔比很低,只有 2%。
重點來了,被當成美國人範本的密西根人都分享些什麼網路鏈結呢?研究團隊將包含鏈結的 24,783 則政治推文分成五大類。第一類是來自專業新聞組織(記者跟作者身份明確、報導有憑有據、符合新聞產製道德規範),第二類是專業的政治內容(來自政府單位、政黨與候選人,還有專家),第三類是「其他政治新聞與資訊」,包括:
- 「垃圾新聞」:研究者指的是為了宣傳目的,充滿極端思維、陰謀論、非常偏頗、刻意製作出來的假消息。單位不明確、沒真的雇用專業記者或作者、用許多情緒化的言詞、敘事充滿謬誤、而且愛用大寫!
- 來自維基解密的消息
- 來自獨立公民社群與網站的文章或連署
- 幽默、娛樂類
- 宗教類
- 俄羅斯生產的消息
- 入口網站如 Yahoo, AOL… 等的鏈結
第四類則是連結到其他網站,但與政治無關,第五類是連向已經消失的網頁。結果研究者發現令人尷尬的結果…
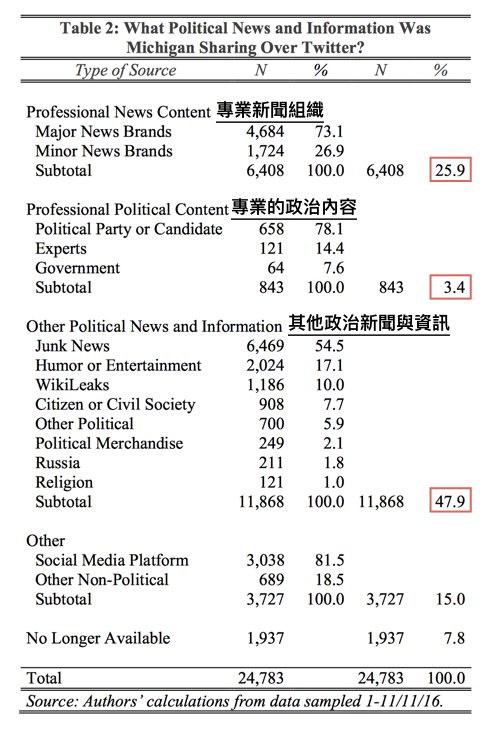
含鏈結推文中,只有 25.9 % 的鏈結是來自於第一類的專業新聞組織,來自第二類專業政治內容的竟然只有 3.4 %。
而含有垃圾新聞鏈結的推文竟然也佔了 25%!跟來自專業新聞的比例幾乎一樣。而如果再把來自未經驗證的維基解密內容、以及俄羅斯產的新聞內容加上來,則高達 46.5%!也就是說,在投票前,在 Twitter 上被熱烈分享轉傳的鏈結中,將近有一半的內容都是不可信的宣傳戰訊息。
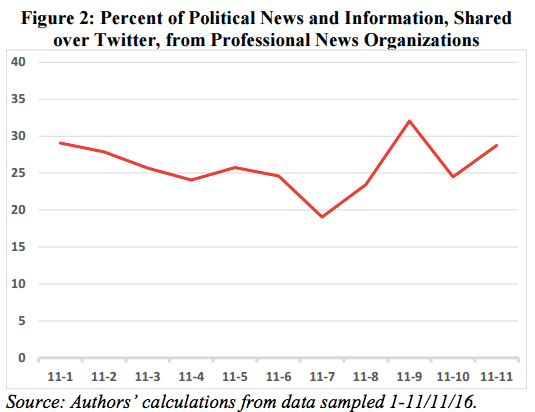
而且根據推文發佈的時間點,研究團隊更發現在 11 月 7 日,也就是投票前一天,網友分享垃圾新聞的行為更是猛烈,比例大為提高,相對地就壓縮了來自專業新聞組織的內容。
難道這就是社群媒體時代,民主選舉的宿命嗎?不,研究團隊還找了個對照組。今年年初,德國也舉行了聯邦總統選舉,雖然德國真正的國家領袖是總理(現任為梅克爾),總統沒什麼實權,但總統選舉也有後續大選風向球的代表性,因此一樣是政黨爭奪的目標。
團隊用類似的研究方式(點開看論文),他們收集了今年二月 11~13 日的 121,582 則推文,其中 17,453 則包含外部鏈結,然後再重新檢視,得到 14,852 則推文樣本。他們發現右翼民粹黨派 AfD (德國另類選擇)在推特上聲量頗大,雖然該黨支持的候選人最終沒有出線,但從推特上來看是一股蠻強的力量。
接下來一樣把推文裡包含的鏈結分類,不過跟先前針對美國密西根人的調查,兩國間的差異可真大。
- 來自專業新聞組織的鏈結有 44.9 % (密西根只有 25.9 %)
- 來自專業政治內容的有 13.7 % (密西根只有 3.4 %)
- 來自垃圾新聞網站+俄羅斯生產的內容,也就是基本上不可信的占 12.8% (密西根高達 46.5 %)
雖然選制不同、國情不同……眾多因素都不同,但總體而言,德國人看來還是比起美國人來得明理許多。儘管如此,研究者也發現,選前在 Twitter 上獲得最多分享的前三名鏈結都是極端右翼反政府的內容,還是得警惕警惕,慎防納粹如九頭蛇般再起。
兩篇初步研究呈現出美、德兩國人民在社群媒體上不同的文化。不禁讓我好奇要是拿台灣的數據來研究看看,結果會是怎樣?不過台灣人少用 Twitter,肯定得從 Facebook 爬資料了。在此也特別歡迎政治、傳播、社會學領域的研究者分享你對於如何研究「假新聞」的見解喔。
文獻來源: