


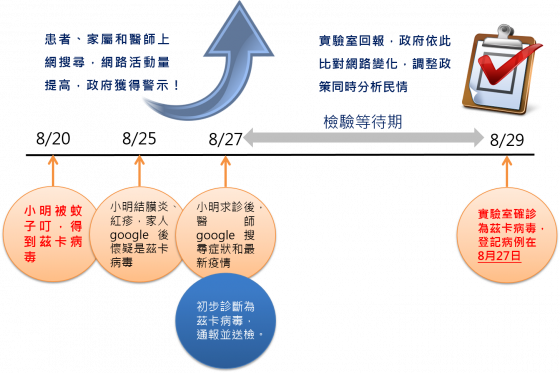
一名新加坡女性於 8 月 25 日出現結膜炎、紅疹等症狀, 8 月 27 日確診首例茲卡境內感染, 8 月 28 日又爆增 40 名病例。《自由時報》引用台大醫師看法:「一定擋不住了!」1-3
- 8 月 29 日新加坡衛生部和國家環境局確診 41 例本土茲卡案例;9 月 9 日數據顯示,總確認人數已達 304 例。
每年都有許多人從鄰國入境台灣,因此掌握鄰近國家傳染病疫情對台灣來說非常重要。那我們現在假設住在新加坡的小明,某天被帶有茲卡病毒的蚊子叮咬,數天後出現紅疹、結膜炎等症狀4,那身處千里之外的台灣疾病管制署(疾管署)要如何及時發現異狀呢?
下圖是近 30 天在新加坡,分別以「結膜炎」和「紅疹」(中、英和馬來文)為關鍵字在 Google 查詢的強度變化。有趣的是,可以觀察到英文的「結膜炎(conjunctivitis)」在 8 月 25 日至 28 日間飆升,而這幾天新加坡國內發生什麼事呢?
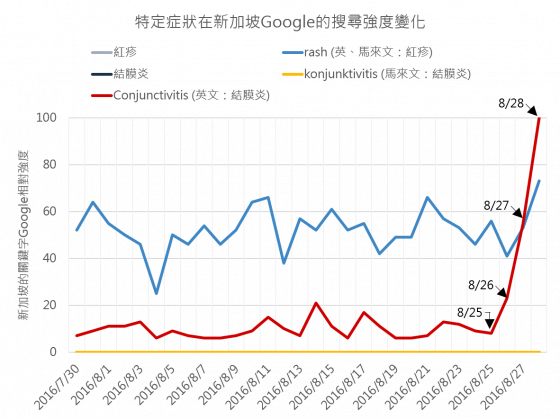
原來 8 月 25 日起,新加坡爆發了一波本土傳播的茲卡疫情。據新聞報導,首名女性患者在 8 月 25 日出現結膜炎、紅疹等症狀,而後續多人持續出現症狀。四天後的 8 月 29 日,新加坡衛生部確診 41 名本土茲卡病例5!
一般法定傳染病從患者採樣送檢到疾病確診,約有 1~5 日的等待期,但在極少數特殊案例中,甚至會有長達 20 日的空等待期。在此空窗期裡,政府無法了解疫情在民間肆虐的情況。倘若此傳染病又是發生在鄰國(如新加坡此波本土茲卡疫情),台灣政府可能要花更長的天數,才能透過媒體報導(如果該國媒體資訊公開透明的話)或外交管道知曉鄰國正在爆發流行病疫情,這對防疫決戰境外的概念來說,無疑是個無法解決的難題!
倘若鄰國對疾病爆發的處置方式,如同當年中國政府為了國家顏面、隱瞞 SARS 疫情6,7,使得台灣無法知道鄰國傳染病的發展,就有可能會重演當年 SARS 在台灣肆虐,最終導致全台三百多人、全球八千多人遭受感染的重大災情。(台灣確診病例數是 346 人,死亡 37 人; 全球確診 8096 人,死亡 774 人)8

儘管新加坡官方直至 8 月 29 日才確診此波疫情,但從圖 1 中可以發現到,英文的「結膜炎」和「紅疹」從 8 月 26 日就已經大幅的飆升,因此可以大膽的猜測 [註1],新加坡國內從 8 月 26 日起,就有越來越多人出現結膜炎或紅疹症狀,所以越來越多患者、家屬、醫師或相關醫療從業人員在 Google 上搜尋相關資訊,也同時反映了新加坡民間和第一線醫院的狀況 [註2, 3]!而此現象也同時發生在巴西去年 5 月的茲卡疫情,在大量疑似茲卡病例出現之前,葡萄牙語的「紅疹」在 Google 上的搜尋強度就已經開始飆升,顯示巴西的民眾正在被一種奇特的疫情所襲擊9 [註4]。
網路能幫我們決戰傳染病於境外嗎?
從 〈用 Google 預警茲卡病毒疫情?〉一文可以知道,觀察網路活動能夠針對不同國別、語言和日期進行縮限,以提高準確度。因此我們提出大膽的構想,可以:
1) 分析網路以建立台灣鄰國警戒圈 [註5]
2) 分析特定症狀關鍵字網路活動,以建立國內的疾病警戒機制
利用網路平台的各項縮限工具(如:韓國 / 韓文、日本 / 日文、菲律賓 / 英文、越南 / 越文等),定期分析各種症狀關鍵字(如:咳嗽 → 流感;水泡 → 腸病毒;紅疹、結膜炎 → 茲卡、登革熱),一旦某些症狀關鍵字的網路強度出現異常,就能夠針對相關的疾病或事件進行比對分析,有效掌握國內防疫的黃金時期,決戰跨國傳染病於境外之效!
- 本文感謝衛生福利部台東醫院檢驗科張昱維(Yu-Wei Chang)、馬來西亞友人林雯慧(whlim)協助。
註釋:
- 註1:猜測也有可能是錯的,如果同時在新加坡也有另一種會引發結膜炎、紅疹的疾病,此猜想就會有錯誤。
- 註2:必須要強調,疾病的確診必須要仰賴實驗室,網路活動僅是反映另一種觀察疫情的角度。
- 註3:新加坡的官方用語至少有英、中和馬來文,但英文的症狀關鍵字表現較為明顯,可能是因為醫師的學術用語為英文。
- 註4:巴西的官方用語為葡萄牙語。
- 註5:任何可以分析數據的網路平台都可以應用此概念,如 Google、Twitter、微博等。
參考文獻:
- 新加坡本土茲卡病毒 暴增至 41 例。天下雜誌
- 新加坡茲卡病毒本土感染病例增至 41 起。中華民國外交部
- 茲卡攻陷新加坡 暴增 41 例本土感染。自由時報
- 茲卡病毒感染症。中華民國疾病管制署
- Localised Community Spread Of Zika Virus Infection With More Cases Confirmed。新加坡衛生部(Ministry of Health, Singapore)
- 邱坤玄 (2003) SARS疫情與兩岸關係的發展。展望與探索,5-7
- 李慶四 (2003) 從SARS衝擊看中國政府的危機公關。二十一世紀
- Cumulative Number of Reported Probable Cases of Severe Acute Respiratory Syndrome (SARS). WHO官方網頁
- Chiang Wei-Lun. (2016, April 23). 用 Google 預警茲卡病毒疫情?. PanSci 泛科學. Retrieved August 30, 2016 from pansci.asia/archives/97183





































