


既然咖啡因正是以咖啡為名,2014年這篇中果咖啡(Coffea canephora)基因組定序的論文[1],標題除了咖啡基因組外,還加上「咖啡因生合成的趨同演化」,似乎是再自然也不過的事。可惜《咖啡為何要合成咖啡因?咖啡的基因體還說了什麼》一文對這篇論文的內容多有誤會,因此特別為文說明。
咖啡因製程的趨同演化
趨同演化的意思是,演化上沒有直接親緣關係的生物,卻擁有類似的特徵(也就是同功演化),例如鯨魚是哺乳類,與魚類不親,但兩者都演化出適應水生生活的身體構造。用鯨魚跟魚的身體構造舉例只是方便,事實上,趨同演化講的是特徵,不限於器官,因此不同種植物各自演化出製造咖啡因的能力,也是趨同演化。
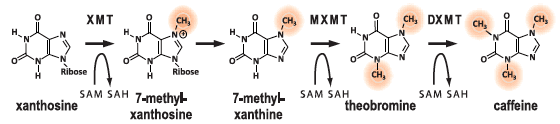
什麼是「製造咖啡因的能力」?咖啡因是多種植物的次級代謝產物,光是在被子植物旗下的真雙子葉植物(eudicots)中,至少就有3種會合成咖啡因:咖啡、茶、可可。咖啡因是由xanthosine經歷4步化學反應,由4個不同酵素加工而成(見圖一),第一、第三、第四步的酵素,都屬於甲基轉移酶(N-methyltransferases ,縮寫NMTs),能製造咖啡因的植物,都配備這些替化合物加上甲基的酵素。
看看這些真雙子葉植物,彼此親緣關係接近的物種,只有一種能合成咖啡因,反而是親戚關係很遠的不同物種,各自能夠合成咖啡因(見圖二左),這有兩個可能:第一、這是沒有直接親戚關係的咖啡、茶、可可趨同演化所造成;第二、這些植物的共同祖先會製造咖啡因,只是後來大部分植物都喪失這個能力,只剩少數幾種保留了祖傳祕技。
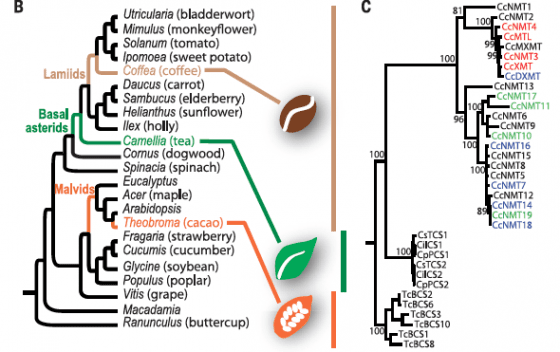
怎麼知道製造咖啡因的能力是由不同物種獨立演化出來?這時候就要把不同植物參與合成咖啡因的基因,通通擺在一起畫演化樹,以咖啡來說,第一個加甲基的酵素叫作XMT,第二個叫MXMT,第三個是DXMT,這些酵素在其他植物中,步驟上都有其對應的酵素基因。
若是畫出演化樹做出來的親緣關係,不同植物的第一個酵素被歸成一群,第二個被歸成另一群,第三個也被歸成自己一群,那麼那麼就可以判斷,各種植物的共同祖先是先有這套製程,後來才分化成不同的種;反過來講,假如每種植物參與咖啡因製程的酵素,都各自成群,就意謂這些基因是植物分家以後才各自產生。
咖啡整個基因組定序後,發現能跟製造咖啡因的NMT(確定有5個)歸在一起的共有23個基因,茶與可可各自有6個基因參與其咖啡因製造,這一共35個基因的演化樹顯示,咖啡的23個自己一群,茶與可可各6個也獨自一群(見圖二右),意思是,這3種能合成咖啡因的植物,製程應該是各自獲得,也就是趨同演化的結果。
雖然這篇論文的表達法有點聳動,加上報導推波助瀾[2] [3] [4],容易讓讀者誤會這次發現咖啡因製程的趨同演化,是對本來完全未知的大突破,不過其實早在2006年就有人做過類似的分析[5],歷來也有數篇論文提過這個說法[6] [7],只是以前的分析比較簡單,沒有這回這麼全面。
基因家族演化史:繁衍與搬家
基因怎麼來的?絕大多數基因,都是由已經存在的基因複製生成,可以追溯到同一個基因祖先複製而來的眾多基因,稱作基因家族(gene family),成員間彼此是「同源」的關係(可以跟趨同演化的「同功」關係對照),在咖啡中,參與咖啡因合成的NMT基因屬於一個有23位成員的大家族。

這23個基因,有13個基因分成3群,各自以串聯的方式排列,分佈在基因組不同的3個地方,第一號染色體上有兩群,一群5個(藍色),另一群4個(綠色),第三群4個則位於第九號染色體上(紅色);另外10個則是散佈在基因組各處(見圖三左)。假如幾個同源基因在染色體上是串聯排列,演化樹上彼此的親緣關係又最接近,那麼就能合理的推測,它們當初是由串聯複製(tandem duplication)所生成。
由基因在染色體上的位置,以及彼此間的親緣關係,可以追溯這個基因家族演化的歷史:這3群基因一開始都位於第一號染色體(藍色),藉由串聯複製誕生,後來一部份位移到第九號染色體(紅色),另一部份位移到第一號染色體的其他地方(綠色),才變成我們今天看到的3群,它們雖然在染色體上位置隔很遠,彼此間的親緣關係卻很密切(見圖二右基因的顏色分佈)。
這些位移也導致咖啡幾個參與咖啡因合成的關鍵基因(CcXMT、CcMXMT、CcDXMT、CcMTL、CcNMT3),位於染色體上不同的位置,雖然基因隔很遠,但酵素產物當然還是可以一起工作,它們在咖啡各個部位與生命週期的表現量,也是全家族裡最高的(見圖三右)。
有利生存的演化力量:正向選汰
突變是造成生物體個體差異的來源,突變的效應可分為三種,有利、中性(沒有利也沒有害)、有害,假如完全沒有任何外力影響,突變會隨機發生並留在基因組中。然而現實是突變發生後,若是這個突變有害,改變是不好的,那麼帶有這個突變的個體不容易留下後代,這個突變也就不會保留在基因組中傳遞下去,這個過程稱為「淨化選汰(purifying selection)」,許多功能上很重要的基因都有這個特徵。
反過來,假如某個突變對生物有利,增加這些個體留下後代的機率,這時改變是好的,這個突變也因此有機會保留在這種生物的基因組中,甚至最終從小眾成為這種生物的主流,這個過程就是「正向選汰(positive selection)」。有很多種方法能計算DNA序列受到的外力影響,不同的方法,不同的比較對象,常會算出不一樣的結果。
這篇論文在偵測參與合成咖啡因的基因,受到何種演化外力影響時,是比較茶、可可、咖啡各自的NMT基因群,發現通往咖啡這群23個基因的分支有受到正向選汰的跡象,並借此推論獲得生成咖啡因的能力,在演化上對咖啡有利。
個人意見是,這個分析的確能告訴大家這「一整群23個基因的共同祖先」,在歷史上可能受過正向選汰,但這不等於「製造咖啡因的這條合成路徑」有受到正向選汰,畢竟正向選汰發生的時候,咖啡還沒有這條咖啡因生產線,要下這種結論,還需要更多分析。
比較合理的推論是,當初這些NMT基因的共同祖先,產生某些突變,可能有利咖啡的生存,後來這個基因在咖啡的基因組中大量串聯複製,產生很多咖啡限定的同源基因,這些複製品之後各自演化出不同功能,包括一條咖啡因的生產線。
總之,這篇論文的重點是定序出咖啡的基因組,並再度確認咖啡、茶、可可的咖啡因製程是趨同演化的產物,至於這些參與其中的基因怎麼改變,怎麼演化,就留待未來更多研究告訴我們了。
參考文獻:
- Denoeud, F., Carretero-Paulet, L., Dereeper, A., Droc, G., Guyot, R., Pietrella, M., … & Argout, X. (2014). The coffee genome provides insight into the convergent evolution of caffeine biosynthesis. Science, 345(6201), 1181-1184.
- Coffee genome sheds light on the evolution of caffeine
- Coffee got its buzz by a different route than tea
- Coffee genome sequenced, caffeine genes abound
- Yoneyama, N., Morimoto, H., Ye, C. X., Ashihara, H., Mizuno, K., & Kato, M. (2006). Substrate specificity of N-methyltransferase involved in purine alkaloids synthesis is dependent upon one amino acid residue of the enzyme. Molecular Genetics and Genomics, 275(2), 125-135.
- Ashihara, H., Sano, H., & Crozier, A. (2008). Caffeine and related purine alkaloids: biosynthesis, catabolism, function and genetic engineering. Phytochemistry, 69(4), 841-856.
- Pichersky, E., & Lewinsohn, E. (2011). Convergent evolution in plant specialized metabolism. Annual review of plant biology, 62, 549-566.




































