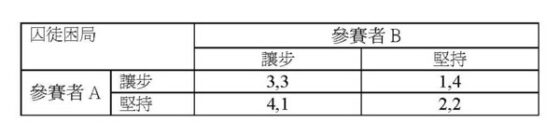
前幾天才結束春季的「人類理性行為」課程,沒想到整個學期和學生討論「納許均衡」,而約翰‧納許就驟然離世了。
紀念納許,我覺得最好的方法是讓大家瞭解他的賽局理論如何地可以用在我們日常生活中的各種面向。我的「人類理性行為」課程規定每個學生要交三篇論文,每篇要講一個真實或虛構的、包含「囚徒困局」的故事,然後用賽局理論加以分析。
第一篇只須是簡單的二人單次囚徒困局,第二篇必須是二人重複性囚徒困局,第三篇則須是多人囚徒困局。雖然大學部學生的論文大都乏善可陳,但每次總有幾篇文章有令人驚艷的創意。這些文章間或有關市場經濟、國際關係,但大多數是與學生個人生活密切相關的人際關係,特別是男女關係。多年來,學生把囚徒困局的理論應用到把妹問題、小三問題、性愛問題等等,令我目不暇給,學到了很多年輕人的次文化。
這裡介紹一個今年一位學生提出的「告白遊戲」來闡釋納許均衡此一概念的實用性。關於賽局理論相關概念的意義,這裡先簡單介紹,詳細請參考文後所列我部落格已發表的幾篇文章。
- 優勝策略:不論其他參賽者採取何種策略對自己都是比較有利的策略。
- 納許均衡:沒有參賽者願意「單方面」改變策略的策略組合。
- 伯瑞多最佳結果:參賽者無法「同時」改進的賽局結果。
- 困局:納許均衡不是伯瑞多最佳狀態的局面。
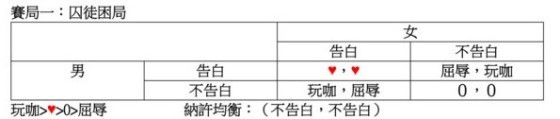
下圖三個賽局中參賽者均為交往中的男女二人,每人可以選擇「告白」或「不告白」兩種策略。這裡告白意味合作,而不告白意味不合作。兩人的策略選擇交叉相乘,共得四種結果。每一結果以男先女後為序,是為:(不告白,告白),(告白,告白),(不告白,不告白),(告白,不告白)。這四種結果對男女二人各有不同的價值,在賽局一中,我們對這些價值初步假設如下:
如果我不告白而你告白,我可以享受玩咖的樂趣而不必負任何責任,這個結果對我最有利,其價值可以稱之為「誘惑」(Temptation)。用數學式子表示:T=玩咖。
如果雙方都告白,兩人都可以享受愛情的甜蜜,但也要負起相當責任(例如不能再劈腿了)。這個結果的價值,對雙方是一樣的,可以稱之為「獎勵」(Reward):R=♥。
如果雙方都不告白,雙方各自心中忐忑,充滿了狐疑,不知道對方究竟想要怎樣,自己下一步該怎麼走。這個結果算是現狀,其價值可以標準化為0,稱之為「懲罰」(Punishment):P=0。
最後,如果我告白而你不告白,我本將心向明月,誰知明月照溝渠,真是令人感到委屈恥辱!這個結果對我最不利,其價值可以稱之為「傻瓜的報酬」(Sucker’s Payoff):S=屈辱。
在這些價值假設之下,大家大概可以同意T>R>P>S,也就是:玩咖>♥>0>屈辱。這個數學關係的成立,使得第一個賽局符合了囚徒困局的條件。簡言之,因為玩咖的樂趣比要負起責任的愛情好,而且現狀比屈辱好,不論你告白不告白,對我而言不告白都要比告白來得有利,而這對雙方皆然。因此,不告白是男女雙方的所謂「優勝策略」,也就是雙方均會選擇不告白。
這個(不告白,不告白)的策略組合便是「納許均衡」的一個例子。當男女參賽者陷於這個結果中,任何人都不願意單方面改變策略,因為如果你單方面改變不告白策略而逕行告白,你只會讓對方自詡為玩咖而沾沾自喜,而自己得忍受當傻瓜的屈辱。「納許均衡」是一個穩定的結果,理性的參賽者在「納許均衡」的結果中不會單方面改變策略。在告白的遊戲中,男女雙方會陷於(不告白,不告白)的泥淖裡不能自拔。
這個賽局也是「囚徒困局」的一個例子。很明顯的,因為♥>0,男女雙方其實都喜歡相互告白甚於相互不告白,但又不願意單獨採取行動。換句話說,在(不告白,不告白)的納許均衡中,如果雙方都願意,雙方的價值都有同時改進的空間。這意味此賽局唯一的納許均衡不是一個「伯瑞多最佳結果」,這就是「囚徒困局」的定義。在上述價值假設之下,告白遊戲是一個囚徒困局。
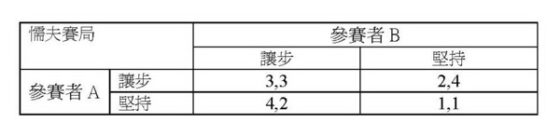
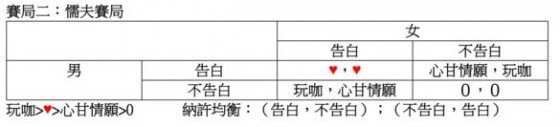
以上是我學生的第一篇論文所分析的,但也許大家會質疑:那為什麼交往中的男女儘有人會告白呢?這牽涉到價值假設的問題。比如有人太過於為對方著迷,不論對方回應與否,心甘情願地自動告白依附,像那首《在那遙遠的地方》所唱的:「我願做一隻小羊跟在她身旁,我願她拿著細細的皮鞭不斷輕輕打在我身上」。在這樣的價值假設之下,我告白而你不告白的價值S便不是屈辱,而是S=心甘情願>P=0了。這樣的告白遊戲,便變成了下圖中的賽局二。因為T>R>S>P,這已不是「囚徒困局」而是「懦夫賽局」了。「懦夫賽局」有兩個納許均衡:(不告白,告白)和(告白,不告白),其中哪一個會發生,就不是賽局理論所能置喙的了。
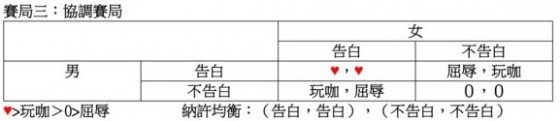
當然,也有人會認為規規矩矩從一而終地談戀愛比當玩咖好,也就是S=♥>T=玩咖。這樣的假設使得下圖中的賽局一變成了賽局三,它也有兩個納許均衡:(告白,告白)和(不告白,不告白),其中(不告白,不告白)仍然不是伯瑞多最佳結果,但(告白,告白)卻是。因為這個賽局有一個是伯瑞多最佳結果的納許均衡,它已經不算是囚徒困局,而是一種「協調賽局」了。在這樣的價值假設之下,男女只要有足夠的默契,便容易相互告白而訂下情緣。
你也許看過「美麗境界」電影但對數學敬而遠之,你甚至連納許的鼎鼎大名都沒聽過,但你知道嗎:你的人際關係中很多你不願意單方面去改變的狀態,包括男女朋友或夫妻關係,不論你喜歡與否,很可能都是「納許均衡」呢?納許的偉大貢獻,便是在概念上釐清了這些狀態的性質,讓我們清楚瞭解它們之所以存在的邏輯,進而使得人類理性行為的預測成為可能。納許雖然死了,但「納許均衡」仍然無所不在於我們的生活中!
有興趣的讀者請進一步參考其他文章:
- 囚徒困局系列:【一】金球的囚徒
- 囚徒困局系列:【二】電影〈史密斯任務〉中婚姻的囚徒
- 囚徒困局系列:【三】學生與政府的「墨西哥對峙」僵局
原刊載於Tse-min Lin 的部落格