各種交通運輸功能的基礎設施,包括道路、鐵路、石油管線、水管、纜車、綿延的電塔與電纜、整排風力發電機組、甚至海岸沿線的消波塊等,這些在地圖上常常以「線」來表示的元素,通稱為「線狀基礎建設」(linear infrastructure)。以往道路生態學(road ecology)所探討的議題,已經擴大到各種線狀基礎建設對環境與生態的衝擊。不同的線狀基礎建設對環境的影響雖然不盡相同,但大致上相似:切開棲地、造成隔離、形成邊緣、棲地破碎…所以常常一併討論。今年七月澳洲生態及運輸網絡(Australia Network for Ecology and Transportation)即將在澳洲舉辦研討會,我沒錢參加只好在此深表遺憾。為了方便說明,下文還是以道路為例。
然而,隨著人類社會的發展,道路的開闢、建築的擴張、農地的開墾,製造了許多「人造的邊緣」。建築、道路、農地等元素,大多不是生物所偏好的棲地,因此人造邊緣所產生的負面效應遠比自然的邊緣還要來的多,邊緣效應對環境及生物的負面影響也受到重視[6]。以道路的邊緣為例,車輛與人類生活所帶來的廢氣、污染、垃圾更容易影響自然棲地;外來種植物也比較容易在邊緣地區擴張;位於邊緣的樹木容易受到風害;鳥巢中的雛鳥容易被獵食或感染寄生蟲等等[reviewed by 7]。
(作者提供)
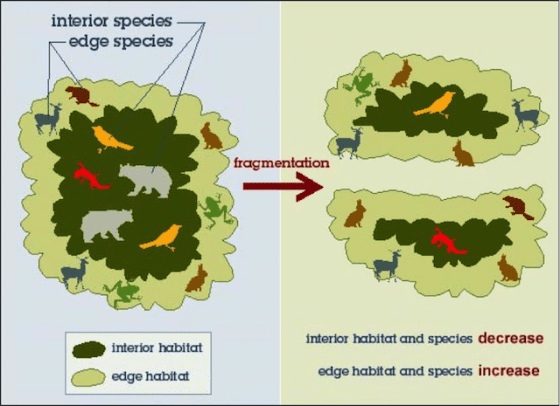
生物對邊緣的偏好並不一致
隨著研究邊緣對野生動物影響的文獻越來越多,發現邊緣對不同物種的影響並不一致 [reviewed by 7, 8]。偏好邊緣地區的物種稱為邊緣物種(edge species),排斥邊緣地區的物種則稱為內部物種(interior species)。邊緣物種通常是不同生活史階段需要不同棲地內生存資源的生物,例如兩棲類,或是需要較高日輻射的非耐陰(non-shade tolerance)植物,因而在邊緣地區的密度較高。反之,內部物種僅偏好棲地內部的環境條件,邊緣越普遍,棲地內部的面積就會越小,大幅降低內部物種的存活率及繁殖成功率[9]。因為邊緣效應的不一致性,如果對該物種的基礎生活史或棲地偏好沒有充分的瞭解,就難以判斷邊緣的形成究竟會帶來什麼樣的影響。
Lovejoy, T. E. et al. 1986. Edge and other effects of isolation on Amazon forest fragments. In Conservation Biology: the Science of Scarcity and Diversity, edit by Soulé, M. E., 257 –285. Sinauer Associates, Sunderland, Massachusetts, USA.
Clements, F. E. 1907. Plant Physiology and Ecology. Henry Holt and Company, New York, USA.
Leopold, A. 1933. Game Management. Charles Scribner’s Sons, New York, USA.
Yahner, R. H. 1988. Changes in wildlife communities near edges. Conservation Biology,2: 333–339.
Harris, L. D. 1988. Edge effects and conservation of biotic diversity. Conservation Biology,12: 465 –469
Gates, J. E. and Gysel, L. W. 1978. Avian nest dispersion and fledging success in field-forest ecotone. Ecology,59: 871–883.
Ries, L. et al. 2004. Ecological responses to habitat edges: mechanisms, models, and variability explained. Annual Review of Ecology Systematics,35: 491–522.
Fahrig, L. 2003. Effects of habitat fragmentation on biodiversity. Annual Review of Ecology, Evolution and Systematics, 34: 487–515.
Fahrig, L. 2002. Effect of habitat fragmentation on the extinction threshold: a synthesis. Ecological Applications,12: 346–353.
Arrhenius, O. 1921. Species and area. Journal of Ecology, 9: 95—99.
Balmford, A. et al. 2005. The convention on biological diversity’s 2010 target. Science,307: 212 —213.