


- 作者/陳子翔|師大地科系,師大科教所, EASY 天文地科團隊創辦者
「一分鐘是 60 秒」是大家再熟悉不過的時間單位換算。
然而過去其實曾出現過許多次「一分鐘有61秒」的情形,原因是我們在曆法中加入了「閏秒」。自 1972 年至今,協調世界時(UTC)總共加入過 27 個閏秒,大約平均兩年就會插入一個閏秒。不過有趣的是,UTC 上一次加入閏秒已經是六年前的事了,最近甚至還有是否要「減去閏秒」的討論,這是怎麼一回事?閏秒為什麼會出現,它的功能又是什麼呢?

在討論閏秒前,先看「一秒鐘」是如何被定義的
「一日有 24 小時,一小時有 60 分鐘,一分鐘有 60 秒」,在這些時間單位中,「日」的概念是最天然而直覺的。在一天當中會有日出與日落、白晝與黑夜,地球上大多數的動物即便不會使用曆法與計時工具,也都依著一天一天的循環生活著。而要如何定義一天到底有多長呢?過去的人們以中午竿影達到最短的時間為基準,測量兩次竿影達最短的時間間隔來得出一日的長度,這樣定義出的一日就叫做一個「太陽日」。而有了一日的長度,就可以在以這個基準去切分成「小時」、「分鐘」和「秒」,或是「時辰」和「刻」等時間單位了。
然而隨著觀測與計時工具的技術提升,人們發現太陽每次達到最高點的時間間隔並不是完全一致的,而是會隨著季節有數十秒的差距,代表每一個太陽日的長度並不是固定的。但如果「一日」的長度是不固定的,那麼以「日」為基準定義的時、分、秒等時間單位,長度也當然會跟著每天的長度不同而變化,這樣「今天的一秒,不是明天的一秒」的奇怪狀況想必會產生許多問題。
因此「平均太陽日」就被定義出來以解決這樣的問題。顧名思義,「平均太陽日」就是把一年當中所有太陽日長度取平均,定義出的時間長度就是一個平均太陽日,如此一來一日的長度就能固定下來,也就不用擔心時間單位的長度會不斷變化的問題啦!
但,真的是這樣嗎?
平均太陽日的出現沒有讓時間的基本定義就此定下來,因為不論是太陽日或是平均太陽日,它們的長度都是決定於地球自轉的轉速,然而地球的轉速卻不是完全穩定的。因此又有一段時間,秒的定義改成以地球公轉的週期為基準訂定,但任何以天體運行為基礎定義出來的時間單位,都會有相似的問題:天體運行的週期不會是完全穩定不變的。
後來隨著原子鐘的發展,也為了盡可能讓時間的基本單位是一個不會變動的定值,1967 年世界度量衡大會決議將一秒鐘重新定義為「銫 133 原子於基態之兩個超精細能階間躍遷時所對應輻射的 9192631770 個週期的持續時間」,而以這個定義進行計時的時間則稱作「原子時間」。

為什麼會要加入閏秒,而閏秒又會帶來什麼困擾
改成以原子鐘為基準後,時間基本單位的定義變得更加精確而穩定。不過這麼一來,一秒的長度就與地球自轉沒有關係了。但「日」的概念終究還是地球自轉形成的,「一日有 86400 秒」這樣的單位換算也依然成立,如果長久下來都只以原子時間計時,我們使用的時間就會慢慢偏離實際的平均太陽日,也就是偏離地球的自轉週期。如果誤差無限制的累積下去,或許就會出現明明時鐘指著中午十二點,外頭卻是夜黑風高的景象。為了追求更加精確的時間單位,卻讓人類的計時計日與自然脫節,似乎就本末倒置了。
為了讓 UTC 中的一秒符合定義,又不要讓其與實際地球自轉週期漸行漸遠,1972 年世界時間局決定讓 UTC 使用標準定義的秒來計時,並以「閏秒」來修正偏離太陽日的問題。每當 UTC 與平均太陽日的時間差距達到約 0.6 秒時,就會以閏秒修正,好讓 UTC 與平均太陽日不會出現超過 0.9 秒的差距。
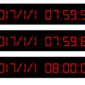
閏秒通常會插入在 UTC 12 月 31 日或是 6 月 30 日的最後一秒後面,而且每次插入閏秒都要提前半年公告。當閏秒插入時,UTC 就會出現「23 時 59 分 60 秒」,然而很多電腦系統並「不認得」這樣奇怪的時間格式,因此插入閏秒可說是讓許多電信、導航等系統工程師相當頭痛的噩夢。
為什麼過去閏秒都是加秒而沒有減秒?
從 1972 年 UTC 總共插入了 27 個閏秒,但從來沒有扣除過任何一秒。主要的原因是由於原子時間中的一秒被定義時,本就略短於當時平均太陽日定義的一秒,也代表原子時間是走得比較快一些的,因此 UTC 會需要透過加秒來對齊平均太陽日。
另外,由於地球長期受月球的潮汐力作用,使自轉轉速逐漸減慢,一個太陽日的長度就會越來越長,像是化石證據就顯示四億年前地球上的一天大約是現在的 22 小時。因此如果地球自轉轉速的趨勢持續,未來 UTC 加入閏秒的頻率應該會越來越高,也更不會有需要扣除閏秒的需求。
近年地球自轉速度比預期還快,讓「負閏秒」成為可能選項
然而事情沒有這麼簡單,根據近年的觀測發現,地球自轉轉速有略為上升的跡象,而目前地球的轉速比過去 50 年都來的快!地球自轉速度為何會有這樣的變化,目前也還沒有確定的答案。不過像是大地震和冰川融化等事件,都是可能提高地球自轉轉速的因子。因為這些現象能夠改變地球內部或表面的質量分布。當質量向地球中心移動,由於角動量守恆定律,地球轉速就會提升,就如同花式滑冰的選手在旋轉時收起手臂,就可以加速旋轉是一樣的原理。
地球自轉的些微加速,讓 UTC 已經超過五年沒有加入閏秒,而目前科學家也還不能確定地球自轉些微加速的趨勢會持續多久,會加速到多快。
如果地球的轉速持續變快,代表一日的長度會持續縮短,未來就可能會遇到原子時間超前太陽日的現象,而若是原子時間比太陽日還快上 0.9 秒時,如果相關單位沒有以其他方式解決,史上首次的負閏秒就有可能出現,不過想必這應該不是系統的工程師會樂於見到的事情。
大家不妨猜猜看,下一次 UTC 進行閏秒修正時,會是增加一秒還是扣除一秒呢?如果負閏秒真的出現了,可別忘了見證史上第一個只有 59 秒的一分鐘呀!
參考資料
- Earth Is Spinning Faster Now Than It Was 50 Years Ago | Discover Magazine
- 時間的單位:秒(s)
https://www.nml.org.tw/measurement/new-knowledge/3668-時間的單位:秒-s.html





































{kind=link}
{kind=link}