最近有些地區開始檢測居民血清中的新冠病毒抗體。因為受病毒感染的人並不一定有症狀,而一般人是有症狀才會尋求病毒檢測,以確診數來估算病毒盛行率不但不準確,而且會高估了感染死亡率。很多公衛專家因此主張抗體檢測是估算盛行率較好的方法。

區域的盛行率到底有多高?血清抗體檢測的相關研究
這個網站所發表的都是未經同儕審查的初步報告(preprint),這項研究之所以受到特別注意,是因為它的作者中有一位大大有名的史丹福大學醫學院教授 John P. A. Ioannidis,近年來以批判傳統頻率學派統計檢定方法聞名。
研究結果發現:經過加權之後盛行率的估計值是 2.8%,意味聖克拉拉郡有 54,000 居民受過病毒感染,是當時該郡官方確診數 1,000 的 54 倍!但這項研究因為使用的是自願樣本,不是隨機抽樣,受到很多批評,連帶使得 Ioannidis 的聲譽受到影響。
5 月 18 日,上述報告的作者之一,南加大學者 Neeraj Sood 帶領的研究團隊在美國醫學會期刊〈JAMA〉上發表了一篇以抗體檢測結果推估新冠病毒盛行率的研究信函(research letter)。
這篇信函提供了很可能是在主要醫學期刊上發表的第一篇,以隨機樣本做抗體檢測的研究報告。此研究於 4 月中旬在加州洛杉磯郡對 863 位隨機抽樣的居民實施測流免疫抗體檢測(lateral flow immuneoassay test)。檢測結果顯示 35 位受測者呈陽性反應,佔所有受測者的 4.06%。經過人口學變數、敏感性、特異性的加權之後,陽性率調整為 4.65%,其 95% 信心區間為 2.52%-7.07%。
根據盛行率 4.65% 來估算,全郡成人應該有 367,000 人受到新冠病毒感染,為當時該郡確診案例 8,430 的 43.5 倍。至於感染死亡率,同一時間的死亡人數為 241 人,佔確診案例 2.86%,但同樣的死亡數字佔抗體檢測盛行率估算的全郡陽性人口則只有0.066%。值得注意的是:
- 這研究的樣本係從市場研究公司宣稱能代表全郡居民的數據庫為母體分層隨機抽樣。最初抽中的 1,952 人有 1,702 人同意受測,但最後只有 863 成功樣本數。這 863 人中有13% 發燒兼咳嗽症狀、9% 發燒兼呼吸短促、6% 喪失味覺或嗅覺。
- 研究所使用的檢測試劑,其敏感性為 82.7%(信心區間 76.0%-88.4%),特異性為 99.5%(信心區間 99.2%-99.7%)。
血清抗體檢測不夠精確?CDC提出指導方針
然而美國 CDC 在 5 月 23 日發出一份〈關於新冠病毒抗體檢測的臨時性指導方針〉。這份文件旨在說明血清抗體檢測缺乏精確性、警告各界不要輕易以檢測的結果作為解封、復工決定的依據。文件並提出一些改進抗體檢測精密性的方法,這包括提高檢測試劑的特異性以及以「二採陽」作檢定結果的最終判斷。
CDC 這份文件以實例說明抗體檢測之「陽性預測值」(positive predictive value, PPV)與病毒盛行率(prevalence)的密切關係,指出當特異性、盛行率都不夠高時,PPV 可能甚低。

所謂 PPV 就是數據科學的「精密性」(precision)。我們知道醫學檢測的品質有特異性(specificity)與敏感性(sensitivity)兩個基本面向。特異性是真陰性的比例,也就是未帶原者檢測陰性的比例。敏感性是真陽性的比例,也就是真帶原者檢測陽性的比例。以統計檢定的型一錯誤(偽陽性)機率 α 和型二錯誤(偽陰性)機率 β 來表示:
- 特異性=1-α;
- 敏感性=1-β。
PPV(精密性)則是檢測陽性者真帶原的比例,它因此是敏感性的「反機率」,需要用貝氏定理來算,但用貝氏定理則必須納入先驗機率,這裡先驗率就是真帶原者佔檢測人口比例的初步估計,也就是盛行率 π 的估計值。
我在附註文章中算得的結果是:
這個公式不論用在病毒核酸檢測(PCR)、快篩、或血清抗體檢測都是一樣的。但這三種檢測工具的特異性和敏感性則通常有所差別,因此即使盛行率一樣,它們的PPV也不會一樣。以台灣防疫中心和美國 CDC 所舉過的例子來看,這三種工具的品質可列表比較如下:
表:各種檢測工具的精密性
| 特異性(1-α) | 敏感性(1-β) | 精密性(PPV) | ||
| π=0.05 | π=0.52 | |||
| 台灣病毒PCR | 0.9999 | 0.95 | 0.9980 | 0.9999 |
| 台灣病毒快篩 | 0.99 | 0.75 | 0.7979 | 0.9878 |
| CDC抗體檢測 | 0.95 | 0.90 | 0.4865 | 0.9512 |
| 南加大抗體檢測 | 0.995 | 0.827 | 0.8970 | 0.9945 |
| CDC抗體二採陽 | 0.9975 | 0.81 | 0.9446 | 09972 |
從這表可以看出:因為 CDC 抗體檢測的特異性比快篩低,在盛行率只有 0.05 的情況下,抗體檢測的 PPV 比快篩還要低很多,更不用說與 PCR 相比了。只有在盛行率高達超過 50% 的時候,抗體檢測的 PPV 才能達到 95% 的統計門檻。
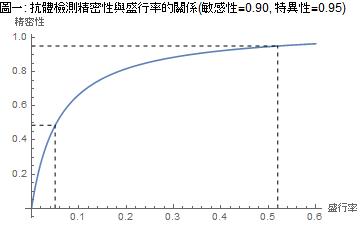
在盛行率 π=0.05 時,PPV=0.4865 是什麼概念?它是說抗體檢測為陽性者,其中只有不到一半(48.65%)是真帶原者, 也就是偽陽性的比例超過一半!

那麼盛行率 0.05 又是什麼概念?以武漢為例,根據德國之聲中文網 5 月 18 日的報導,「武漢在全市範圍內開展了全員新冠病毒核酸篩查。財新網報導指出,初步評估武漢核酸檢測結果顯示,1000 萬人中至少有 50 萬人已經感染。」如果這個數字屬實,武漢的盛行率就是0.05,可見這樣的盛行率在全世界極高了。
可是如果以美國 CDC 引為案例的檢測試劑在武漢全面實施抗體檢測,所得陽性結果中會有一半是偽陽性!前述洛杉磯郡抗體檢測估計的盛行率為 4.65%,也非常接近 0.05 了。如果也是用 CDC 引為案例的試劑做的抗體檢測,所得的 35 個確診數會有 18 個偽陽性。
但是南加大研究團隊用的試劑特異性高達 0.995,已經超過台灣 CDC 的快篩試劑特異性,敏感性也有 0.827,所以它的 PPV 可以高達 0.89,也就是 35 位確診者只有 4 位偽陽性。如果考慮盛行率的信心區間,PPV 的信心區間為 0.81-0.93,偽陽性在 1-7 位之間。
謹慎解讀抗體檢測的結果
那如果抗體施測單位所獲得的試劑品質不高怎麼辦?CDC 在指導方針中建議以「二採陽」作檢定結果的判斷。
如果是以相同品質的試劑採檢兩次,則先算出 二採特異性 = 1 -(1 – 一採特異性)²,二採敏感性 =(一採敏感性)²,再把二採的特異性、敏感性套入上面的公式即可。
以 CDC 所引抗體檢測試劑為例,二採特異性是 0.9975,敏感性是 0.81,則在盛行率 0.05 時的 PPV 可以從 0.4865 增加到 0.9446,增加了將近一倍。
CDC 在南加大的研究報告刊出之後,發表指導方針也許不是偶然。當各地、各界、甚至各行各業開始相信新冠病毒感染致死率沒有原來想像中那麼高的時候,CDC 及時發出指示,提醒大家要謹慎解讀抗體檢測的結果,以免貿然解封、復工可能帶來的災難。
- 延伸閱讀:有關檢測工具精密性的計算,請參考作者另外三篇文章
- 本文轉載自作者部落格,原文標題:從抗體檢測結果重估新冠病毒的盛行率與死亡率