文 / 廖英凱、雷雅淇
2019年12月,不明原因肺炎在中國武漢出現。2020年1月7日,經全基因組定序確認為新型冠狀病毒,世界衛生組織命名為 2019-nCoV(2019新型冠狀病毒),俗稱武漢肺炎。1月下旬,關於 2019-nCoV的相關臨床統計、病理研究與傳播模式的學術研究,以及與疾病管制科學有關之評論陸續發表。在這篇文章裡,我們挑選了首批發表的三篇相關研究,一起來看看這些研究告訴了我們什麼?又有哪些限制?
目前學術研究發現的重點摘要:
- 確認 2019-nCoV 與 SARS 類似
- 可以跨城市尺度人對人傳染
- 發現有出現無症狀感染的病例
- 封城隔離成效有限,有可能蔓延到北上廣等大城市,台日韓等國有較大蔓延風險(該結論未經同儕審查)
- 本文於2020年1月27日刊登,仍有許多與2019-nCoV相關的研究正在進行,研究的發現也有可能不是最終結果。
嚴重症狀患者臨床症狀統計
武漢金銀灘醫院統計41位中重症患者的臨床症狀,研究成果於2020年1月24日發表於知名醫學期刊 The Lancet(刺胳針):
Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China
該研究針對本次疫情初期,症狀較嚴重的 41 位病人,臨床症狀的統計發現 2019-nCoV 與 SARS 有類似的症狀如發燒、咳嗽、肌痛與疲勞。
所有患者在電腦斷層掃描中,均觀察到肺炎症狀;其他常見症狀有(百分比為該研究統計中的患者比例):
發燒37.3度以上(98%)、咳嗽(76%)、肌痛或疲勞(44%)、痰(28%)、頭痛(8%)、咳血(5%)、腹瀉(3%)
較重症的部分:
- 55%的患者會呼吸困難,這些患者從初始症狀發作到呼吸困難的平均時間為八天。
- 29%的患者併發急性呼吸窘迫症候群 (Acute Respiratory Distress Syndrome; ARDS)註;15% 病毒血症;12% 急性心臟損傷;10% 繼發感染。
- 有32%(13位)患者送入加護病房;15%(6位)患者死亡。
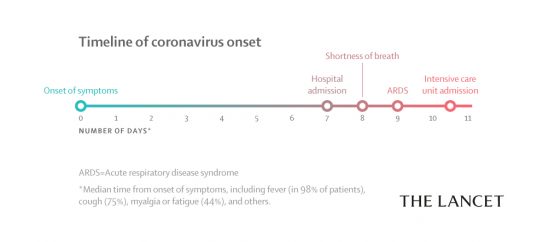
也須留意這是本次疫情初期,確診後已有肺炎症狀,可視為中度至重度症狀的病人,完全不等於感染 2019-nCoV 的症狀表現,目前針對其他患者的觀察,仍有相當比例是未產生肺炎的輕症表現。
傳染病防治醫療網指揮官張上淳教授,在「2020/1/26 中央流行疫情指揮中心嚴重特殊傳染性肺炎記者會」上,則指出目前針對患者的初步觀察,粗估致死率約為 3%,但仍須繼續追蹤。
此外,該研究聲明目前尚無對冠狀病毒的感染有效的抗病毒治療方法,但過去針對 SARS 和 MERS 的研究中,已發現有藥物可能有助於該類疾病的治療,目前也已經展開將該類藥物應用於 2019-nCoV 的治療研究。
確認人傳人途徑與發現無症狀病例
香港大學深圳醫院針對一個深圳的家庭,研究病毒傳播方式,研究成果也於2020年1月24日發表於知名醫學期刊 The Lancet(刺胳針):
該研究針對一個深圳的家庭研究,該家庭中有六人前往武漢旅遊一周,並於旅遊期間接觸已被 2019-nCoV 感染的家庭,導致六人家庭其中五人於旅遊期間被感染。其中四人於武漢旅遊期間已出現發燒、虛弱或腹瀉等症狀。
感染的五個人,都沒有接觸過武漢的市場或動物,僅有其中兩人曾前往當地醫院,返回深圳後,又感染一名未前往武漢的家庭成員,因此可以相信是傳染途徑為透過人傳人。
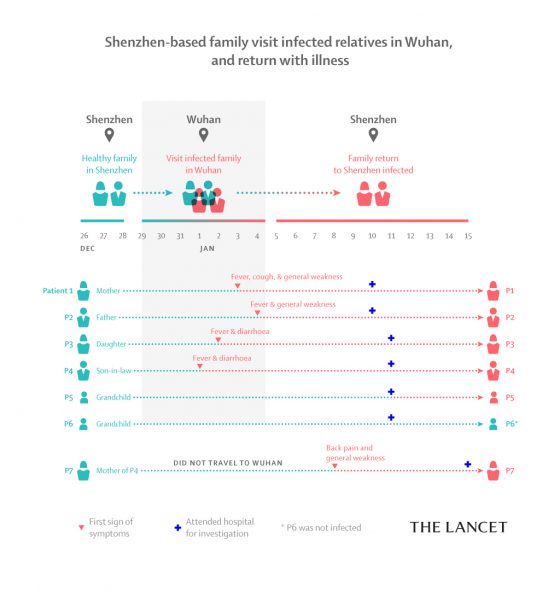
該家庭於深圳就醫時,確認感染 2019-nCoV,受感染者肺部出現「放射狀玻璃樣混濁變化(radiological ground-glass lung opacities)」,且年齡較大(60歲以上),擁有更多與更嚴重的全身症狀。
然而,家庭中有兩位兒童成員,其中一位兒童成員雖同行至武漢,但並未感染 2019-nCoV,另一位兒童成員雖沒有顯示發燒、咳嗽等狀況,但電腦斷層掃描仍發現肺部有異狀,確診為感染 2019-nCoV,代表 2019-nCoV 可能可以有無症狀感染的特性。
研究團隊的基因組分析亦支持 2019-nCoV 與 SARS 相似,基於 SARS 病原被證實來自蹄鼻蝙蝠(horseshoe bats,又稱菊頭蝠)[1]。且本次疫情起源與華南海鮮市場高度相關,研究建議應對野生肉類的食用與貿易加以管制。

總括而論,研究結果確認 2019-nCoV 與 SARS 類似;可以在家庭與醫院中,達到人對人的傳播;可以在跨城市傳播;可能可以無症狀感染。研究者亦建議應該盡早隔離患者,並追蹤與隔離接觸。
傳染程度評估與預測
以英國 Lancaster 大學醫學院為主的幾位專家,基於既有 2019-nCoV的病例資料,提出了傳染狀況的未來預測,與達到成功疾病管制的目標門檻與限制:
Novel coronavirus 2019-nCoV: early estimation of epidemiological parameters and epidemic predictions
- 該研究尚未經過同儕審查,應對該研究持保留態度
2019-nCoV 的基本再生數
該研究利用2020年1月21日以前病例報告,套入傳染病的傳染模型,估計出 2019-nCoV的基本再生數(R0, Basic reproduction number)為 3.6-4.0(95%信賴區間)。
基本再生數的意義是指一個病人,在易感染的人群中,平均能感染的人數。R0= 3.8-4.0 代表在此研究的統計中,平均一個病人會再感染到3.8-4.0人。如果能透過措施使基本再生數小於1,也就是平均一個病人,會再感染不到1個人,則該疾病就能被撲滅。因此,須確保至少72-75%以上的感染者,能被控制不再傳染給他人,則該疾病就能被阻止傳播。
以 SARS 為例,WHO有研究估算 SARS 在香港的傳播初期,R0為 2.9,但實施控制隔離措施後,R0降為 0.4,代表疫情被有效控制 [2]。
阻止傳播疾病的方法通常可透過增加社會距離措施(social distance measures),例如停班停課或管制公眾場所;治療與隔離;疫苗接種或抗病毒藥物的預防性投藥。來降低基本再生數。
不過R0的估算受到統計資料品質與傳播模型選用的影響很大,WHO 針對 2019-nCoV的估算則為 1.4 – 2.5 [3];倫敦帝國理工學院MRC全球傳染病分析中心(MRC Centre for Global Infectious Disease Analysis)則估算為 2.6(不確定範圍為 1.5 – 3.5)[4]。
確診人數偏低
研究估計確診人數僅佔總感染人數的 4.8-5.5%(95%信賴區間),有可能代表社會上仍有大量人口未被確診。
感染人數可能持續上升
研究認為如果疾病管制或傳播方式沒有改變,則自1月21日起,預估至2月4日的兩周後,武漢的受感染人口將會超過19萬人(預測區間為 132751 人至 273649 人),且可預期在中國大陸的其他城市(如北京、上海、廣州、重慶、成都)進一步爆發疫情,並加速傳播到其他國家的速率,風險最大的國家或區域為:泰國、日本、台灣、香港、韓國。
封城效果有限
研究表明就算封鎖 99% 的武漢對外交通,至2月4日時,武漢以外的疫情也只會減少 24.9%
但仍須強調,該研究尚未經過同儕審查,必須對此研究的所有數據、方法與論述等持保留態度,並關注後續論文同儕審查的進度。
評論、限制與持續警覺
針對 The Lancet(刺胳針)期刊上武漢金銀灘醫院與香港大學深圳醫院的研究, The Lancet期刊編輯部亦發表了編輯評論:
編輯評論認為中國大陸當局從過去 SARS 不充分的感染控制措施中成功吸取了教訓,而能在本次疫情中迅速分離病毒並完成基因定序 [5],而能使各國藥廠開始製作篩檢用試劑盒。評論認為在多數的狀況下,中國大陸當局在隔離病患與接觸者、診斷與治療,以及公眾教育上正在達到國際標準。並引述了世界衛生組織(WHO)總幹事( Director-General) Dr.Tedros Adhanom Ghebreyesus 的論點,Dr.Tedros 讚許了中國大陸在本次疫情中的透明性、資料共享與快速反應。
雖然世衛組織尚未針對本次疫情發布國際公共衛生緊急事件(PHEIC,作者註:如2019年7月剛果伊波拉病毒即被列為PHEIC)而引發諸多評論與猜測,但編輯評論仍讚許世衛組織未屈服於壓力的判斷。

編輯評論中也提及了煽動恐懼的新聞報導方式,會損害執政當局的感染控制策略成效。且隔離等感控措施,有很大程度取決於執政當局與在地公眾之間的信任。評論中也強調醫護工作者的感染風險仍令人極度擔憂(extremely worrying);也尚無法確認隔離措施所帶來的成效。
但是,對比之下 Lancaster 大學等團隊的研究,則較不支持封城隔離的成效,並認為不應輕忽未就醫或未確診的黑數。且中國大陸當局的媒體輿論控管策略是否增進公眾信任,仍有諸多評論與批判,例如:
- 張妍&符雨欣. (2020/01/25), 武漢疫情:封城是最好的辦法嗎?. 端傳媒.
- Sammi Zheng & Emily Chan (2020/01/26).武漢疫情每日情況更新. 紐約時報中文網.
先別提什麼研究了,你知道防疫的關鍵就是你自己嗎?
回到個人尺度,面對持續蔓延的疫情,我們能如何面對呢?
注意個人衛生和飲食習慣
目前對2019新型冠狀病毒的完整傳播途徑,尚未完全瞭解,且目前未有疫苗可用來預防冠狀病毒感染。從發病個案的流行病學資訊來看,除了曾在華南海鮮市場活動外,亦有家庭群聚與醫護人員感染的個案報告,因此高度懷疑2019新型冠狀病毒可藉由近距離飛沫、直接或間接接觸病人的口鼻分泌物或體液傳染。
因此,面對2019新型冠狀病毒我們能做的預防措施與其他呼吸道感染相同,包括常用酒精消毒以及用肥皂洗手、配戴外科口罩,儘量避免出入人潮擁擠、空氣不流通的公共場所,且避免接觸野生動物與禽類,也避免食用生食或未煮熟的動物製品。更詳細的資訊也歡迎參考WHO所提供的建議。
別輕信謠言,保持關注也別太過焦慮
而面對鋪天蓋地而來的各種資訊,我們可以持續關注但也無需太過焦慮。不論新聞說世界如何「淪陷」、有貼文資訊再怎麼「聳動」,都要記得無論國內外消息,都以最終疾病管制署公告的為主:國內消息、國外資訊,和旅遊警示 在這裡。
還有還有,也不要因為恐慌而亂發假消息,如果因為亂發而消息造成社會的危害,是會被重重處罰的喔。根據《傳染病防治法》第 63 條「散播有關傳染病流行疫情之謠言或不實訊息,足生損害於公眾或他人者,科新臺幣三百萬元以下罰金。」,因此在面對資訊想分享時,也要記得三思而後傳啊!
- 更多防疫相關資訊,請參考中華民國衛生福利部疾病管制署、疾病管制署 – 1922防疫達人
One more thing… 不要再說「武漢肺炎」了
武漢肺炎、或是武漢肺炎病毒叫起來多順,嚴重特殊傳染性肺炎、2019新型冠狀病毒好長啊,為何不用俗稱就好?它的確也是從武漢開始的啊,而且中東呼吸系統症候群、西班牙流感不也是這樣?

還記得偶像劇《我要變成硬柿子》裡的男主角因為名叫阮適止,而被從小欺負到大的故事嗎(天啊到底有多少人知道這個梗XD)?傳染病人人避之唯恐不及,而一但名字取錯了,會產生一些意想不到的負面影響。例如其實不會透過食用豬肉而被傳染豬流感,但因為其名稱的關係,導致大眾容易對豬肉產生不必要的誤解。
因此在2015年,世界衛生組織發布了人類傳染病命名指南,認為傳染病命名應該避免使用:1. 地理位置(例如中東呼吸綜合症、西班牙流感);2. 人名(例如庫賈氏病、恰加斯病);3. 動物或食物的種類(例如豬流感,禽流感);4. 文化、人種或職業(例如退伍軍人症);5. 引起過度恐懼的術語(例如未知、致命)。而最佳的命名法應由:1. 疾病的症狀(例如呼吸系統疾病)和一般性的描述詞組成;2. 使用更具體的描述,來彰顯疾病的特徵,例如季節性、嚴重程度、影響對象;3. 若是已知的病原體,則應將病原體並名稱的一部分(例如冠狀病毒,流感病毒、沙門氏菌)。
所以,「武漢肺炎病毒」、「武漢肺炎」雖可作為簡易口語或俗稱使用,但 2019 新型冠狀病毒(2019-nCoV) 、嚴重特殊傳染性肺炎仍是較為理想且精準用法。可以的話仍盡量避免,或至少於作為俗稱使用時,明確聲明為俗稱,並提及病毒正式名稱。
- 編按:關於病毒命名,有其他不一樣的看法與本篇作者相左,詳見:病毒不是源於武漢的海鮮市場?從分子演化學角度看2019新型冠狀病毒(武漢肺炎)的起源與傳播
當疫情還在蔓延時,多一點認識就少一點恐懼。
Keep Calm and Carry On
參考資料:
- Zhou, P., Fan, H., Lan, T., Yang, X. L., Shi, W. F., Zhang, W., … & Zheng, X. S. (2018). Fatal swine acute diarrhoea syndrome caused by an HKU2-related coronavirus of bat origin. Nature, 556(7700), 255-258.
- WHO.(2003) Consensus document on the epidemiology of severe acute respiratory syndrome (SARS)
- WHO. (2020/01/23). Statement on the meeting of the International Health Regulations (2005) Emergency Committee regarding the outbreak of novel coronavirus (2019-nCoV).
- Report 3: Transmissibility of 2019-nCoV
- Wuhan seafood market pneumonia virus isolate Wuhan-Hu-1, complete genome
- WHO best practices for naming of new human infectious diseases
- 看懂武漢肺炎病毒命名學避地名防污名化| 生活| 重點新聞
- 本文授權轉載給以下單位:
端傳媒,泛科學:三篇最新的新冠肺炎相關論文,都講了什麼?
鳴人堂,泛科學/從三篇新型冠狀病毒論文中,我們知道什麼?
註解:2020/2/5 原文 Acute Respiratory Distress Syndrome; ARDS 應為「急性呼吸窘迫症候群」誤植為「急性呼吸衰竭」,特此更正。
若有轉載需求,請寄信至:contact@pansci.asia