


- 採訪編輯/嚴融怡 美術編輯/張語辰
你聽過「聲景」嗎?
走進公園或森林,你會聽到鳥聲、蟲叫、蛙鳴,甚至存在人耳無法聽見的蝙蝠超音波。這些生物聲響與環境音構成了「聲景」,是生物多樣性的重要指標。中研院生物多樣性研究中心助研究員──端木茂甯,與跨領域團隊正嘗試蒐集大量錄音資料、結合機器學習,探討生物的聲音反映生物進行了哪些活動、或生態環境中發生了哪些事件。
唱著超音波的蝙蝠
談到蝙蝠,你可能會想到身穿黑色緊身衣、痛揍敵人的蝙蝠俠?但在生態系統中,「蝙蝠」帶來的貢獻,可能比蝙蝠俠還要多(希望影迷不會抗議),例如移除害蟲、幫助傳播種子花粉、讓人類有機會發展生態旅遊等等。
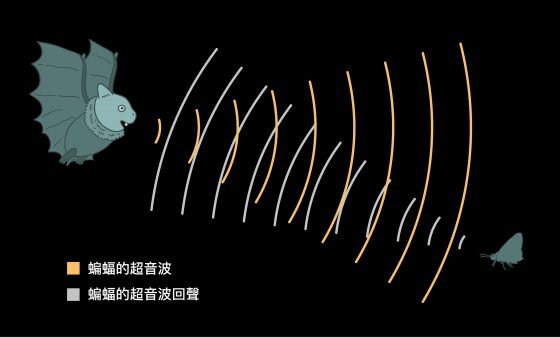
資料來源/端木茂甯提供 圖說重製/張語辰
但若想確切了解蝙蝠的行為,實在有些困難,除非你有雙翅膀、而且晚上不用睡覺,可以追蹤牠們飛來飛去,並且能用「超音波」和蝙蝠溝通。
生態學家雖然沒有這般能力,但靈活的大腦可以想出辦法,彌補感官與行動能力的不足。
端木茂甯團隊採用的研究方式是:錄下蝙蝠的超音波與環境音、運用機器學習分離出不同蝙蝠物種的聲音,並藉由「聲音特徵」辨別不同地區的蝙蝠、會發出哪些不同超音波,可能代表什麼樣的生態行為。
有趣的是,生活在不同環境的蝙蝠,叫聲類型也會不一樣。
以森林為主要活動範圍的蝙蝠,為有效偵測複雜的周圍環境,多使用「頻率變化大的短促叫聲」;相對地,喜好生活在開闊地區的蝙蝠,則多使用「固定頻率」的叫聲。且大多數的蝙蝠也會根據自己周遭環境的複雜程度,調整叫聲的頻率範圍與長度。
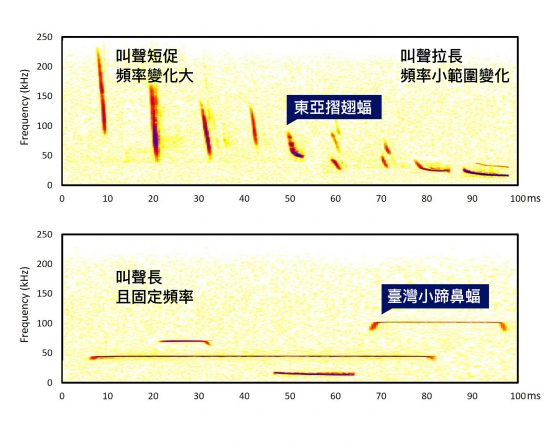
透過聲景監測,也可發現自然界一些「看不見」的因果關係。
當自然環境中某些高頻的噪音影響蝙蝠偵測空間,蝙蝠會改變超音波頻率、避開噪音。例如夏天時,有些暮蟬的吵雜跨及超音波的波段,蝙蝠為了不受干擾,會等到稍晚暮蟬發聲減緩之後,才展開活動、進行回聲定位。
運用聲景的概念與機器學習技術,可以解析不同物種的蝙蝠超音波、探討蝙蝠如何適應環境。「這講起來很容易,但要怎麼做,我在這方面也還是個新人。」端木茂甯說。
與「聲景」的初相遇
端木茂甯大學曾窩在實驗室做切片,也曾跟隨台大李玲玲教授至野外研究,與學長一起追尋山羌、飛鼠的腳步,碩班時則用無線電發報器與三角定位,追蹤神出鬼沒的食蟹獴。
「但野外最困難的是……動物不是想遇就遇得到,不確定因素太多了!」端木茂甯回想起來,仍能感到當時歲月流逝、生態觀測卻毫無進展的壓力。
後來在 2007 年美國的景觀生態學(Landscape Ecology)研討會,端木茂甯接觸到聲景生態學,「那時看到生物的聲音,如何在時間與空間上產生動態變化,感到很有趣,雖然當時還沒想到可以做這個題目。」

直到 2016 年,端木茂甯來到中研院生物多樣性研究中心,有了兩個強大的資料庫為基礎──邵廣昭博士帶領建立的台灣生物多樣性資料庫、來自林試所的王豫煌博士建立的亞洲聲景平台,加上跨領域專家的知識與技術合作,包含專精蝙蝠生態的黃俊嘉博士後研究員,以及中研院網格中心的研究副技師嚴漢偉,提供所需的雲端儲存運算空間。
天時地利人和,「聲景生態學」研究才得以實踐。
於是從 2017 年 3 月開始,沿著中橫海拔 100-3,350 公尺的山上,端木茂甯團隊辛苦地在蝙蝠容易經過的地方設置 15 個樣站,藉由 SM4 超音波錄音機、溫濕度計,蒐集蝙蝠的超音波與環境音,並同時紀錄環境氣候。
另一方面也要設置豎琴網,捕捉野外的蝙蝠、紀錄物種,再設置飛行帳錄下超音波,作為後續比對蝙蝠物種的音訊依據。



「我們每兩分鐘就錄一分鐘,從下午 4:30 錄到隔天早上 7:30 ,這是蝙蝠活動的時間。每個樣站每月至少錄音一個禮拜,一年下來共有 56 萬分鐘的音檔。」端木茂甯說明。
有了這些在不同環境條件取得的龐大音檔,接下來,讓專業的來。
從聲景交響樂,拆出蝙蝠的音符
與中研院資創中心曹昱副研究員、林子皓博士後研究員合作,端木茂甯團隊得以將在野外錄到的音檔,運用 PC-NMF 技術解析成可供後續生態分析的資料。

野外錄到的音檔像首交響樂,包含所有蝙蝠的超音波、嘈雜的背景噪音,幸好這兩者聲音有個區分之處:
蝙蝠的超音波通常有較強的週期性,因為每天活動時間、範圍幾乎都差不多。
因此, PC-NMF 技術藉由找出「較強週期性」的音頻,排除環境中沒有週期性的背景噪音,從聲景「交響樂章」中,分離出不同蝙蝠所唱的超音波「音符」。
聲景研究除了可以聲音為據,找出環境中不同種的蝙蝠,也能透過長期監測,觀察蝙蝠的回聲定位行為與環境條件的變化。
例如下圖,比較 2016/7/14~7/22 錄到的音訊,會發現每天分離出的蝙蝠超音波,在時間與頻率上有些不同。後續累積更多這類音訊變化、與環境氣候等資料,就能進一步探究讓蝙蝠改變回聲定位行為的因素。
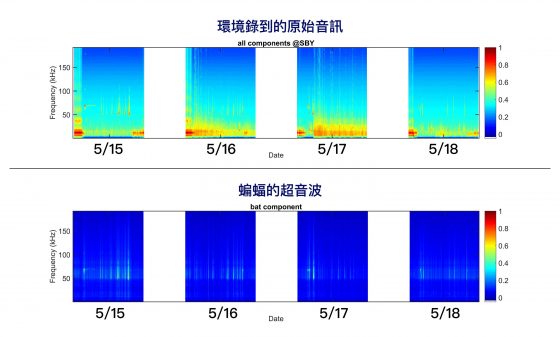
圖片來源/端木茂甯提供
聲音版的小獵犬號之旅
19 世紀達爾文航行小獵犬號,沿著各地海岸以紙筆、標本蒐集紀錄物種,那時尚無法錄下物種的聲音,並透過電腦分析音訊。現今受惠於錄音設備的普及、機器學習的發展,「聲景生態學」研究與延伸應用越趨成熟。
國際上有 〈xeno-canto〉 致力分享全世界的鳥類鳴聲,美國康乃爾大學有〈Macaulay Library〉 自 1929 年開始收集野生動物的聲音,而國內則有〈台灣聲景協會〉,促進大眾了解與參與保護聲景。
另外,〈雨林連結組織(Rainforest Connection, RFCx)〉也運用回收的舊手機、佈置在熱帶雨林中,透過遠端追蹤雨林中可疑的聲音,成功阻止了一些盜伐活動。
端木茂甯團隊以學術角度,希望在亞洲拼上更多片聲景保育拼圖,將繼續與王豫煌、林子皓等跨領域專家合作,將聲景研究擴展到東南亞國家,除了蝙蝠也會包含其他以聲音溝通的物種,橫跨水域和陸域。
最終期望將這些蒐集得到的聲景音訊與環境條件紀錄,轉換為公開資料,讓相關領域的研究團隊得以共享,一起保存生物多樣性。
人類雖然有兩只耳朵,但常常只聽見自己想聽的。或許今後可試著將注意力放在附近公園、野外踏青的聲景中,在寂靜的春天來臨之前,透過「聲音」展開屬於你的小獵犬號之旅。
本著作由研之有物製作,原文為《蝙蝠的超音波,藏了什麼訊息?》以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位
延伸閱讀:
___________
你是國中生或家有國中生或正在教國中生?
科學生跟著課程進度每週更新科學文章並搭配測驗。來科學生陪你一起唸科學!







































