- 採訪編輯/廖英凱 美術編輯/張語辰
中研院人社中心的詹大千團隊與遠傳電信合作,利用資料探勘技術,分析電信公司所統計的行動裝置網路訊號,藉以建立更準確的人群流動預測模型,有助了解人口流動與社會經濟活動的關係。
人,是會流動的
你有沒有想過,一個地區、一個城市,甚至是一整個國家內部,「人」在哪裡、在哪裡工作、在哪裡居住?「長時間」的遷徙趨勢是往城市、還是往鄉村移動?「短時間」的通勤人口是來自外縣市還是不同行政區?
或者你會否好奇,不同的年齡層、性別有沒有不一樣的生活範圍、移動特徵?對於某一個商圈、公共設施的選址,是不是建立在一個適宜行人路過的良好地點?
這種探討與人類遷徙、移動、人口增減等現象的學科,就是「人口學」。

人的流動可能是大尺度的遷移消長,也可能是小尺度的通勤或消費行為。人口學探討國家或大城市之間的人口消長、人口遷徙時,往往以「數個月」至「數年」作為時間尺度,並利用人口普查、抽查、電話問卷、民調訪談等方式,來了解指定地區的人數和習性。
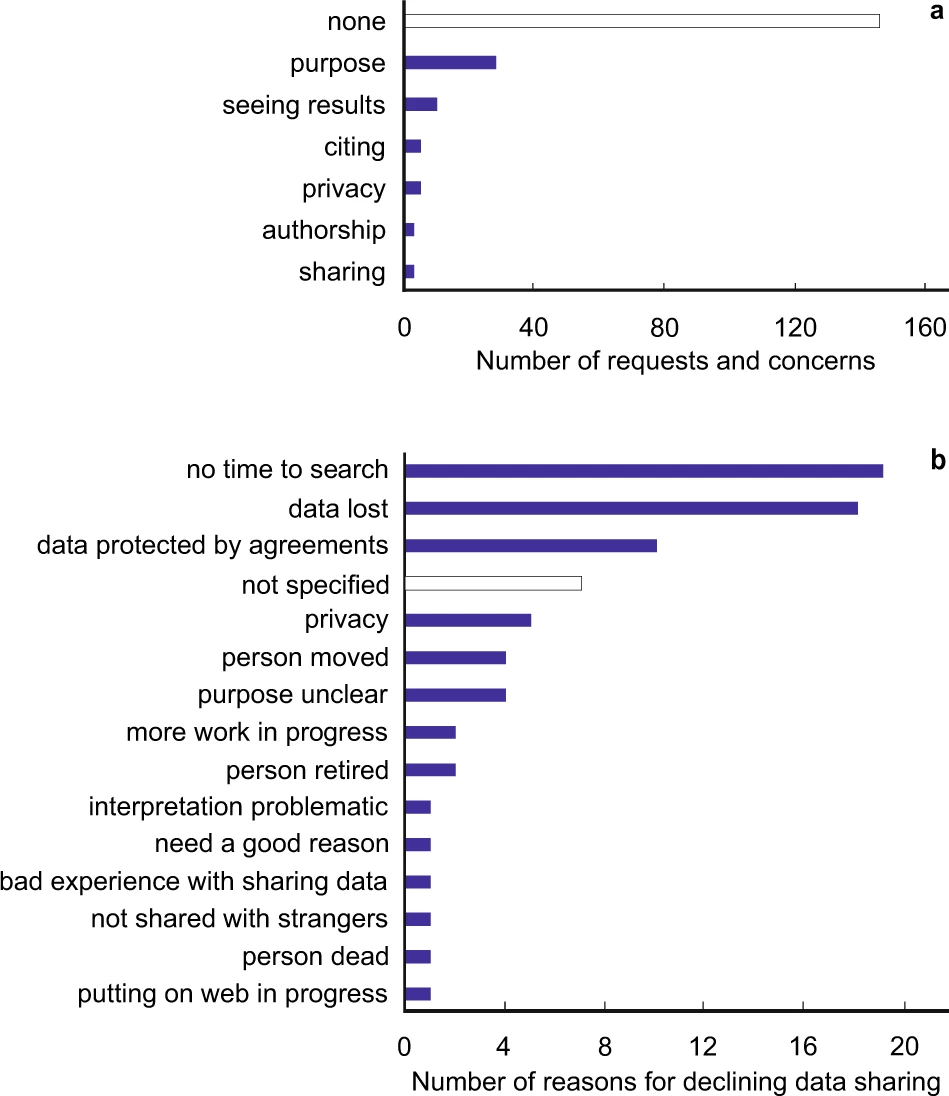
但是,像這樣子的調查方法,長期以來會有取樣代表性的疑慮,例如戶口抽查時,可能只會調查到剛好在家的族群。而藉由訪談或問卷來了解民眾生活型態,也會受到回憶偏差的影響。或是傳染病傳染區域、或傳染路徑的預測,運用許多假設與模型來猜測人移動的方式,而降低了預測的準確度。
「動態人口學」的概念被提出來,更精準地了解人口的分布與流動的特徵,更細緻地分析人們的日常生活與消費行為。
動態人口學:人口如何分布與流動
2005 年起,「動態人口學」的概念被提出來,在人口學的基礎上,透過研究概念與研究方法的改進,更精準地了解人口的分布與流動的特徵,更細緻地分析人們的日常生活與休閒消費行為,或是有脈絡地拆解出不同年齡層、性別、族群等的行為差異。
因此,研究者需要有比既有普查、抽查等方式,還能獲得更多資料的研究方法,例如,所取得的資料能精細到越短的時間尺度、越小的空間尺度,才有機會探討人口,如何處在動態中不斷變化,如何受到各種不同環境變數影響。
日常生活中,剛好有一種資料,能表現出「小尺度」的時間與空間下人口分布的特徵──就是行動裝置的上網資料。特別是今日的臺灣社會,平均一個人擁有兩個以上的手機門號,並且多用於持續性的行動上網。因此,透過電信公司於每個基地台所記錄到的行動裝置網路訊號,我們就可以藉此推估各個區域中的實際人口。
圖片來源/ Google 地圖
2017 年起,在「中央研究院資料科學種子研究計畫」支持下,中研院人社中心詹大千副研究員及其團隊,與遠傳電信合作。利用資料探勘技術分析電信公司所統計的行動裝置網路訊號,建立更為準確的人口調查方法、人群流動的演算法模型,以此了解人群的流動趨勢,來探索動態人口與社會經濟活動的關係。
為了確保個資隱私,研究運用的行動裝置網路訊號,並非追蹤每個人手機的定位,而是加總在不同時段、不同區域中的行動上網門號數。
在空間解析度上,研究團隊鎖定了「台北市」與「新北市」為研究範圍,以每 250 公尺 x 250 公尺作為一個網格。時間解析度上,則是以每 10 分鐘作為區間。
如果某一個手機門號的網路訊號,在同一網格中停留超過 10 分鐘則列入一次計數,這樣子的計數意義是將這個手機門號的使用者,視為停留在這個網格中、或是正在步行經過,而並非在交通通勤的路上匆匆擦身而過。因此,我們就可以假定這個使用者,有可能跟這個網格中的設施有所互動。
區分「居住」與「通勤」人口
將手機網路訊號統計資料應用於人口學,就能突破傳統研究的許多限制,例如過去對於居住人口、通勤人口、日間人口的估算,均需仰賴戶口普查抽查、或是民調訪談等。
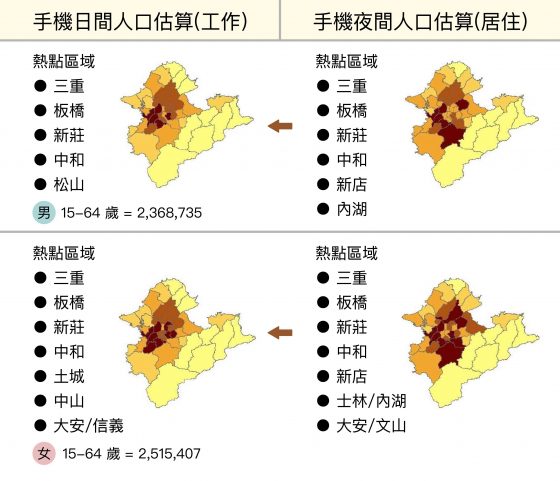
詹大千團隊鎖定資料登記為 15 至 64 歲的遠傳電信用戶,並設定晚上 10 點至凌晨 3 點有行動上網訊號的紀錄為「手機夜間人口」,早上 10 點至下午 3 點則為「手機日間人口」,同時比對戶籍資料數作為「戶籍夜間人口」,就能分辨哪些人住在哪區(因為手機晚上在此有長期的網路訊號紀錄),而到了早上這些人又移動到哪區上班(因為手機白天在此有長期的網路訊號紀錄)。
從團隊推估結果,我們可以輕易地看出日間與夜間、住宅區和商業區的人口差異。也能發現不同性別的日夜分布區域也略有差別,比起傳統戶口調查的方式更為即時且準確。
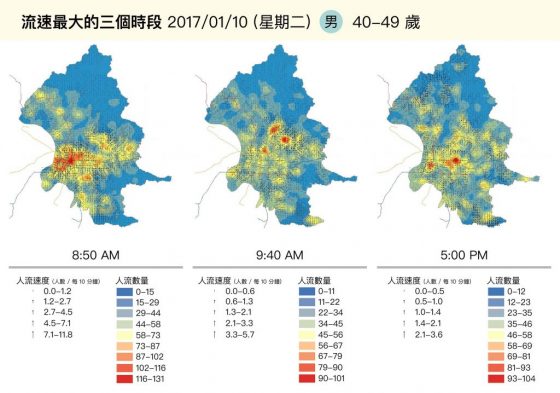
除了找出什麼類型的人,會在什麼地方工作或居住,上下班時刻看到的龐大人潮,也可以透過行動裝置的網路訊號,建構演算法來分析人口流動規律。只要計算隨時間推移,相鄰網格的人數變化差異,我們就可以掌握人群的移動方向與移動速度。
例如,詹大千團隊發現上午 8:50 、 9:40 和下午 5:00,是人口流速最大的三個時段,而且人潮熱區也不同,這就可供交通部門規劃合適的通勤疏運方案。
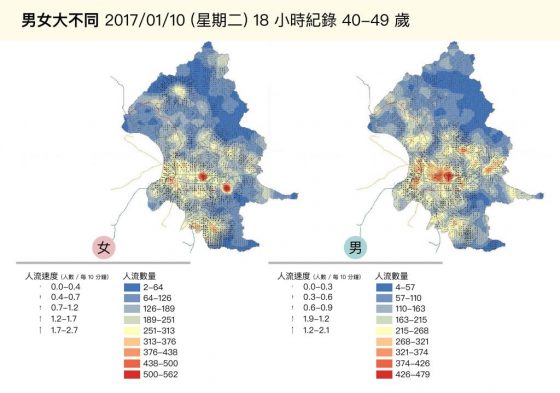
統計同一天中 40-49 歲人口的流動狀況,也可以發現在信義計畫區一帶,女性的人潮明顯多於男性。這樣的發現有助於研究者了解性別在不同產業或地區的差異,有機會更進一步找出社會結構的問題、與政策制度的改善方向。
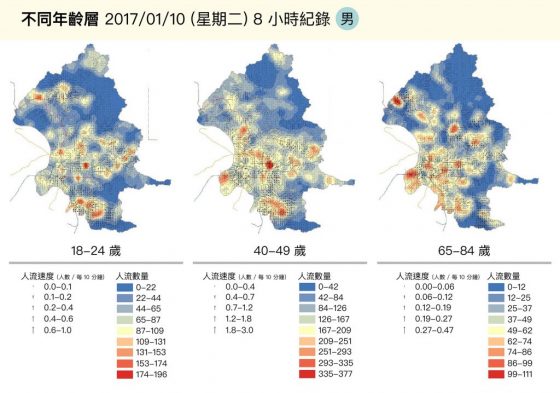
而不同年齡層的流動區域也有差異,甚至透露著生活型態。以 2017/1/10(二)為例,這天是學期末, 18-24 歲男性多分佈於各學區。這天也是工作日,40-49 歲男性多位於市中心與捷運沿線人口稠密區。而 65-84 歲男性,則與前述兩個年齡層有較不一樣的分佈,例如集中在北投、萬華一帶活動。
結合政府開放資料:電子發票、土地利用

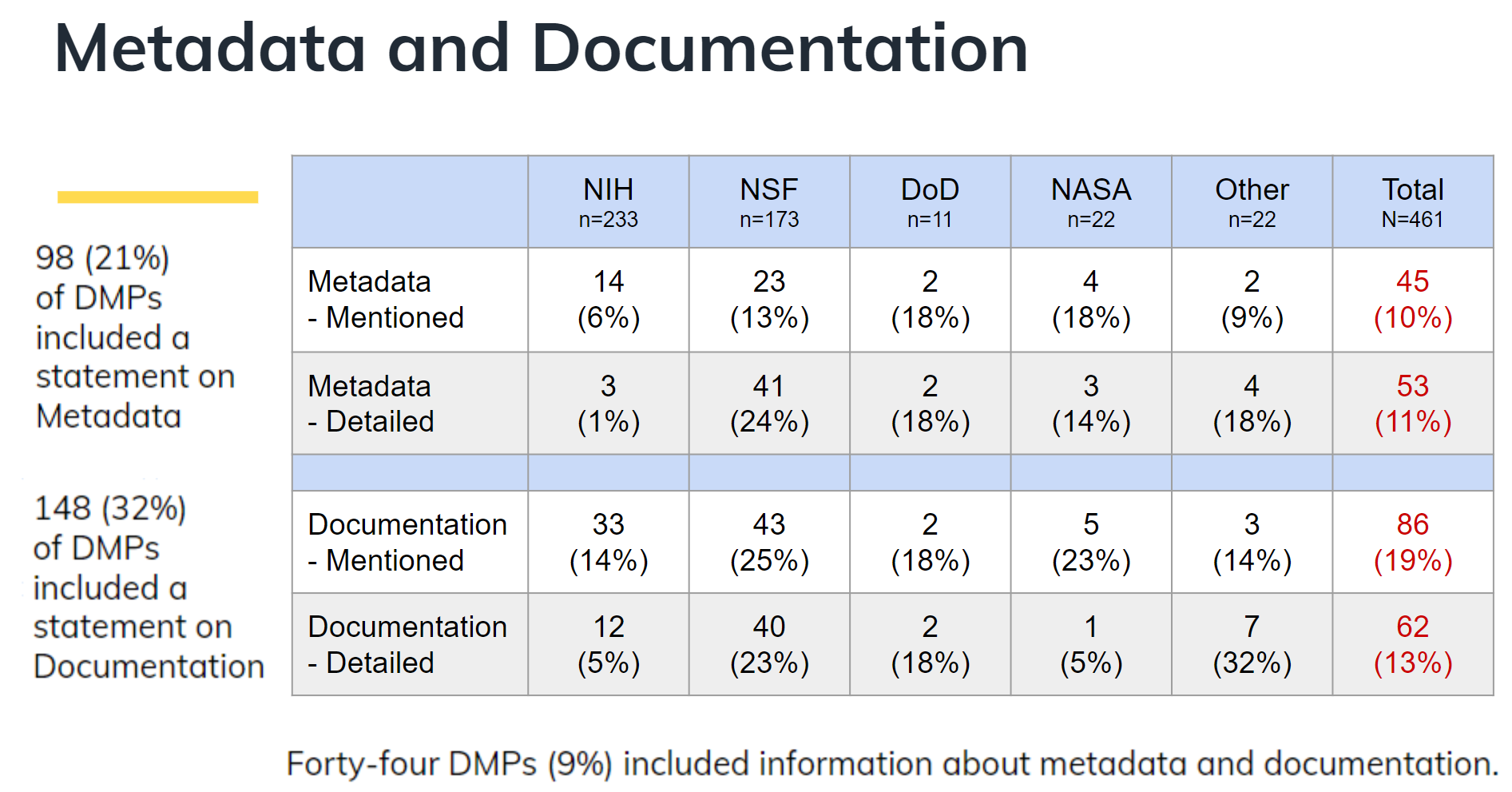
有了人口隨時間與空間流動的趨勢,進一步再結合內政部的「國土利用調查資料」與財政部的「電子發票開放資料」,詹大千團隊就能更入微地分類行動用戶的族群,並推測其生活特徵、消費行為、經濟能力。
例如從「時間」來分群,可以觀察到有兩種群體:一種是在白天出沒、離開居住地;另外一種則是早晚出沒、離開居住地。比較兩群體的消費能力,會發現白天出沒的族群消費力較高,早晚出沒的族群消費力則較低。
從「出沒地點」來看,白天出沒的族群分布於服務業、商業住宅、小學與大專校院;而日夜出沒的族群則主要集中於住宅區。
因此,從上述資料中,我們就可以推測出:白天出沒的族群,可能就是上班族、服務業等大部分通勤族群;而早晚出沒的族群,則可能是家管與退休人員。
因此,研究者就可以藉此了解一個地區中通勤族與家管、退休待業族群的人口差異。地方政府主管機關,也可以利用這樣的推估成果,設計符合該地區的社區營造、或是足以負荷人流的交通規劃。
整體人口的移動,其實是由許多種不同的人流所組成。若能細緻地分群、找出每一種分群的移動規律,也能將過往的人流資料當作機器學習的訓練資料(請見下方影片的上半部 Groundtruth Data),提升電腦預測未來人流路徑的準確度(請見下方影片的下半部 Predicting Data)。
資料開放 vs. 隱私機密的拉鋸
利用手機網路資料,可以更即時、更準確地掌握人口流動的趨勢。一切的關鍵,也在於有沒有辦法取得這些資料,以及取得資料後會不會損害個人隱私。因此,資料必須去除個資、去識別化後才能被使用。
依目前政府規定,這些手機門號、網路訊號資料被歸為電信業者的財產,電信業者可在不涉及個資隱私的狀況下運用,但也需肩負監管責任。研究中大量應用到在單一網格中的行動網路訊號數量,對於電信業者來說,其實是一個不方便公諸於世的商業機密。
詹大千團隊有賴遠傳電信指派數位協同人員,協助將資料整理成符合法規、並合適電腦分析的格式,才得以進行這系列動態人口研究。團隊研究中遇到的另一個難題,是政府管理的電子發票開放資料時空解析度不足,且開放效率也不夠積極,導致無法更細微地分割各區域的商業活動、與人口流動的關係。
其實,運用資料科學來解決問題,已然是近年來相當熱門的潮流,各公私部門也多紛紛積極地開辦各種黑客松競賽,希望透過網路社群、技術社群的活力,運用政府資料來發現問題、解決問題。因此,若政府能提升資料品質,並為研究社群建立取得資料的合適管道,就有機會讓更多研究者透過資料科學,找到隱藏於巨量資料中的關鍵線索,一窺社會的真實面貌。

延伸閱讀:
- 詹大千的個人網頁
- 林柏丞、郭巧玲、葉耀鮮、楊毓仁、魏敬玲、江麗香、詹大千*,2017,〈運用開放式地理資訊架構於登革熱防疫機制之研究〉,《醫療資訊雜誌》,26(3), 1-14。
- Jia-Hong Tang,Yen-Hui Chiu,Po-Huang Chiang,Ming-Daw Su,Ta-Chien Chan*, 2017, “A Flow-based Statistical Model Integrating Spatial and Nonspatial Dimensions to Measure Healthcare Access”, HEALTH & PLACE, 47C, 126-138.
- 章可藍、蔡煜書、詹大千、束連文、陳娟瑜、顏正芳、 余沛蓁、徐睿、蔡文瑛、陳為堅*,2016,〈地理資訊系統應用於毒品查獲空間分布:縣市毒品查獲地點的分析〉,《台灣公共衛生雜誌》,35(6), 671-684。
- 鄧詠竹、郭巧玲、陳建州、葉耀鮮、高瑞鴻、林柏丞、范毅軍、詹大千*,2016,〈利用政府開放性資料建構台灣線上互動式疾病死因地圖〉,《台灣公共衛生雜誌》,第35卷第5期,頁553-566。
- Simini, F., González, M. C., Maritan, A., & Barabási, A. L. (2012). A universal model for mobility and migration patterns. Nature, 484(7392), 96-100.
本著作由研之有物製作,原文為《從手機網路訊號資料,探勘人口動態奧妙》以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位