本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位
- 採訪編輯|歐宇甜、美術編輯|林洵安
路殺社成立故事
2011 年 8 月創立的路殺社,成員已有一萬七千多名,是全世界首創利用社群媒體收集路殺資料的社團,目前上傳網站資料已逾十萬筆。運作這麼龐大的線上社團和資料庫,有什麼成功的「眉角」?路殺社社長林德恩以及中研院資訊科學研究所莊庭瑞副研究員,娓娓道來他們一路破關前行的精彩故事。

林老師一直都在研究路殺問題嗎?
路殺社社長林德恩(以下簡稱為林):其實我是做動物的生理跟生態學研究的,專長是爬行類。長年研究發現:台灣的蛇很多,但在野外一百天可能只有不到二十天碰得到,卻常看到馬路上稀有蛇種被車壓死。於是我想:既然活蛇不好找,何不乾脆找死的,透過蛇類的路殺資料來推測族群狀況和分布地點。
2008 年,特生中心培訓志工幫忙調查全台物種分布,我負責爬行類的培訓。蛇具危險性、不易找,大家對牠的恐懼感也大,我就訓練志工記錄死蛇,門檻較低。因為這個機緣,我開始做起動物的路殺調查。
對生態研究來說,找死蛇比活蛇容易得多,因為蛇多是夜行性,體型長,在馬路上移動慢,加上大家討厭牠、不會留情,被車子壓死的機率較高。而且蛇有鱗片,死後外形能保持完整、留在路面的時間較長。

後來為什麼會想成立路殺社呢?
林:路殺是意外,創立路殺社也是個意外!
2009 年臉書進來台灣,為了方便志工聯絡,我在臉書成立「特生中心爬行類志工聯誼社」。我看社團裡什麼都沒有,隨手丟進一張路殺蛇類照片。結果一傳十、十傳百,大家紛紛把自己「壓箱底」的路殺照片上傳……一周後,社員暴增到兩百多人,我才驚覺臉書的傳播功能有多強大。
不過,最初的社員多是生態圈的老師、學生,大家習慣記錄珍稀物種,採樣嚴重偏差。於是有人建議:是不是把社團的功能改一下,擴大收集各種路殺動物的資料呢?我想臉書是免費的、操作方便,失敗了也沒負擔,決定試看看。後來又有人提議社團改叫「路殺社」,聽起來跟路透社很像。
透過臉書來收集路殺資料,會碰上什麼問題嗎?
林:當路殺社逐漸成長後,遇到第一個關卡是:上傳的資料要怎麼建檔?
我們起初以完全人工的方式,只要有人上傳一筆,就在 Excel 輸入一筆,並把照片抓下來、編號……。可是社團一天有一、兩百筆資料,我和助理又常跑野外,每次回來都要往前回溯數百、甚至上千筆資料,臉書文章洗版速度又很快,助理追資料追得精疲力竭。
幸好,我們很快碰到貴人相助!
那時在莊庭瑞老師實驗室工作的鄧東波先生在網上尋找研究素材,意外發現這個古怪的社團:人家都是在臉書上「曬」漂亮的動物照片,我們卻是秀路死動物照片。 他是學資料科學,馬上就知道我們用臉書收集資料的工作有多「笨」,於是熱心的給了我們一些建議。
我心想:你可以給建議,就表示有辦法解決囉!於是,我邀請他與莊老師來幫忙。
莊老師認為用臉書收集資料有哪些問題呢?
中研院莊庭瑞(以下簡稱為莊):臉書是適合大家交流、互動的社群網站,但不是很好的資料收集平台,有一些先天的缺陷:
- 臉書是商業公司,路殺社依附在其下,要同意臉書的使用條款,而且社團可能隨時被關閉。
- 大家上傳的高解析度照片,臉書會自動壓縮,再撈回來的皆是低解析度照片。
- 早期手機拍攝照片,很多沒有內建拍攝位置的空間資訊。即使有,上傳臉書後都會被清除,照片是在哪拍的只能仰賴作者的文字資訊。但有人用門牌號碼 ,有人用電線桿或配電箱的編號、知名景點或道路名稱,形式非常混亂。為此,我們還曾經設計一個爬蟲程式,先把每筆資料從臉書抓回來,再透過「自然語言」技術將文字位置資訊,轉換成經緯度的空間座標。
2013 年,特生中心委託我的實驗室處理資料時,我心想,資料先傳到臉書,再撈回來處理,明明大家上傳的照片和資訊是完整的,撈回來卻是殘缺的。因此,我打算做新的資料蒐集與處理流程,建置新的研究型網站為資料蒐集中心,說服社員先上傳資料到新的網站。
但光是這一關,就花掉三年時間!
用網站收集資料應該更有效率,為什麼反而不容易達成?
主要是使用者的習慣問題!大家會覺得:臉書很好用啊,為什麼要再申請一個網站的新帳號?
為了符合使用者習慣,我們一開始是做手機 App,讓大家透過 App 先傳資料到臉書,再傳到網站。但除了前面提過的問題,智慧型手機的作業系統 Android 、 iOS 皆會改版,臉書更是經常改版,每當它們一改,手機 App 就要跟著改。
後來我們決定讓手機 App 上傳的資料不先到臉書,而是先進網站,但舊社員果然抱怨這樣繞了一條路、不自然。中間我們又嘗試:手機 App 上傳的資料同時到臉書與網站,只是這樣跟臉書的連動性依然很高,臉書一改版,手機 App 就會當掉……。
就這樣來回調整好多次,才改成現在的模式:不用手機 App,而是開發成網頁型式的 App,我們稱作 Web App。
Web App 在手機環境的操作方式跟手機 App 類似,可以將使用者回報的資料直接上傳到我們建置的網站「台灣動物路死觀察網」,雖然功能上稍微受到限制,維護成本大大降低。再由網站自動將統一格式的資料發文到臉書上的路殺社社團,讓社員覺得好像是自己發文到臉書上,總算兼顧了使用者習慣和資料品質(呼~)。
我們也不斷跟社員說明,直接上傳到路殺社網站對他大有好處!因為上傳臉書的照片,日後抓回來解析度會變差,上傳網站等於幫忙他保存歷年的高解析度照片與觀測紀錄,還可以畫成統計圖,回顧自己的的觀測歷程。更重要的是,可以保障上傳者及物種的隱私,避免詳細的地點資訊直接暴露在公開的社團。
除了使用者習慣,在網路上經營萬人規模的志工社團,還要考慮什麼?
莊:路殺社成功的另一個關鍵,就是上傳照片與資料的開放授權。
過去在生態領域,志工幫研究人員做的資料大多歸屬研究人員管理使用,最後發表或歸檔,再利用率比較低。如果路殺社也用這樣模式,大家可能想,我們的資料都被研究人員拿去用,當我看到其他社友的照片或資料很不錯,自己不能隨意使用,必須透過研究人員,或是另外開口去要,很不方便啊。
簡言之,同一個團體共同蒐集、建置的資料庫,應該讓成員都可以使用!
我一開始接觸路殺社這類由公眾參與建立的資料庫,即積極推動開放授權的觀念,讓參與建立資料庫的眾人,也能自由使用成果資料。這類似維基百科的概念,眾人協作生產有文字、也有影像的著作內容,這著作可再授權給眾人改寫、編輯。參與者只要同意這樣的安排,就可以加入一起編寫,這對公眾有很大的吸引力。
我們推動社員使用 CC 授權條款 (Creative Commons Licenses) 釋出自己的照片給公眾,或更開放一點,將照片釋出到公眾領域 (Public Domain),讓任何人以任何方法自由運用。
林:有趣的是,一般網站要作者開放授權,通常難度很高,但路殺社都是動物死亡照片,大家較不在意,多半樂意配合。原本我們最大的缺點,卻變成最大的優點 (笑)。
在莊老師的協助下,路殺社的資料處理和著作權問題逐步得到解決,運作步上軌道,現在是透過網站收集與自動化處理資料。網站程式原始碼也可以開放給大眾運用,國內外許多團體紛起效尤,在臉書設立各種收集資料的社團。
路殺社資料越來越多,物種鑑定是否也是個問題?
林:的確!每筆路殺資料一定要正確鑑定物種,才會有價值。
起初幫忙鑑定者,多是生態界的教授、專家,只要有人丟照片,馬上有人搶著辨認,碰到不易辨認的還會展開激烈討論。
那時大家是覺得好玩,因為活體的特徵容易辨識,一旦被壓死,則要透過微小特徵去分辨,好像在練功。厲害的人只需觀察一根羽毛,就知道是哪種鳥,是公的還是母的。而且剛開始資料量不多,鑑定完成率有九成五以上!
但時間一久,問題來了。這些專家都有自己的工作,不可能天天掛在網上幫忙鑑定,加上資料越來越多,現在一年有幾萬筆,工作量大到無法想像,目前完成率只剩下七成。
最近我正設計一個破關遊戲程式,訓練志工鑑定能力。先將已鑑定的照片按照難度分階:初階是完整、好鑑定,中階是稍有破碎、特徵還在,高階是破損嚴重、只剩一點特徵,再設計是非題、選擇題或連連看,讓志工一路「練功」,達到某個程度還有考試,及格後就具備初階鑑定師資格並發給正式證書。如果未來能培養出一大批熱心的業餘鑑定師,網站就能自主運作了。
真是關關難過關關過啊!未來路殺社還有什麼計劃嗎?
林:最重要的工作是「系統化路死動物全台同步大調查」(路殺社 2.0)。目前網站上幾萬筆資料,雖然可以呈現一些現象,但無法做科學性的分析與比較。例如:當你問我全台一年路死多少動物?我無法估算。
因為過去社員都是隨機調查,任何時間、地點,只要看到就記錄,缺點是「努力量不一樣」。某個地方成為路殺熱點,可能是常常有人做調查,許多地方不是沒有路殺,只是沒人記錄。
為了解決這個問題,我們開始推動系統化調查。簡單來說,是把台灣分成 5 公里 乘 5公里,共 1440 個方格,開放社員認領。每個方格有三種不同變項,包括:八種生態氣候分區 (影響動物族群跟分布)、三種道路密度 (高、中、低密度)、四種道路型態(省道、縣道、鄉道、其他)。
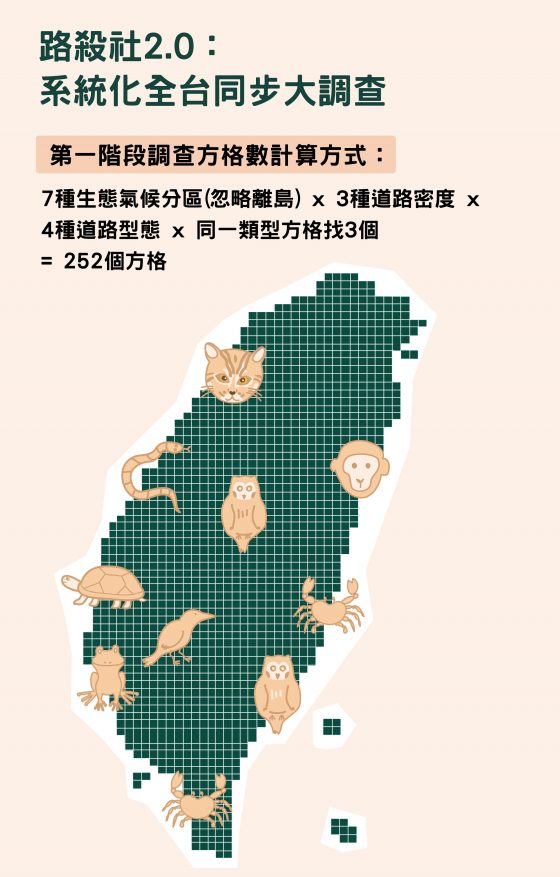
社員可根據自己方便挑選方格並組隊,在每年 1、4 、7、10 月,去認領的方格做調查,路線要固定,每條路最少做三公里長度,一個區域至少做兩條不同型態的道路。
本來擔心沒人理我們,還好大家很支持!(汗!)第一階段 252 個格子都達成,未來將擴增到 420 個格子,透過取樣調查方式,研究者就有相同時間、相同努力量的資料可以做精確分析了。
路殺社從臉書起家,成員來自四面八方、各式各樣的專業與人才,彼此之間並不認識,但能夠同心協力走到今天,真的難能可貴。未來希望有更多人加入我們,讓這把改善路殺、保育動物的火苗繼續壯大,一同守護台灣的野生動物。
延伸閱讀
本文轉載自中央研究院研之有物,原文為公民科學萬人齊發!路殺社的成功心法,泛科學為宣傳推廣執行單位