本文轉載自中央研究院「研之有物」,為「中研院廣告」
採訪撰文|劉韋佐
責任編輯|田偲妤
美術設計|蔡宛潔
人工智慧將改變以人為主的法治領域?
由人工智慧擔任警察,再也不是科幻電影的情節,交通管制常見的科技執法就是應用 AI 辨識闖紅燈、未依規定轉彎、車輛不停讓行人等違規行為。 AI 的客觀、高效率正在挑戰以人為審判主體的法治領域,這樣的轉變會對我們產生什麼影響呢?中央研究院「研之有物」專訪院內歐美研究所陳弘儒助研究員,他將帶我們思考:當 AI 取代人類執法時,將如何改變人們對守法的認知?
交通尖峰時段,後方出現一台救護車,你願意闖紅燈讓道嗎?iStock
想像有一天你正在尖峰時段開車,車子停在十字路口等紅燈時,後方出現一輛急駛而來的救護車,你為了讓道必須開過停止線。這時你是否願意冒著違規被開罰的風險?還是承擔風險以換取他人盡速就醫?
在上述情境中,針對「要不要闖紅燈」我們經歷了一段價值判斷過程。如果剛好十字路口有真人警察,他的判斷可能是:這是情急之下不得不的行為,並非蓄意違規。
然而,如果負責執法的是「法律人工智慧系統」(Artificially legal intelligent,簡稱 ALI)情況可能截然不同。
ALI 這個詞源自 Mireille Hildebrandt 的研究 ,在概念上可區分為兩類:採取傳統程式碼的 IFTTT(if this then that)、運用機器學習的資料驅動 。前者是注重法律推理或論證的計算機模型,將法律規範轉為程式碼,藉由程式編寫來執行法律任務。後者則透過大量資料的學習,來預測行為範式,用於再犯率、判決結果預測上有較好的成果。
一般情況下,應用在交通管制的 ALI 會辨識車輛是否超速、闖紅燈等違規行為,不過交通情境千變萬化,ALI 能否做出包含「道德價值的判斷」將是一大挑戰!
中研院歐美研究所陳弘儒助研究員察覺,人工智慧(AI)正在左右人們對守法的價值判斷及背後的因果結構,進而反思當我們將原本由人來判斷的事項,全權交由 AI 來執行時,可能產生哪些潛移默化的影響?
讓我們與陳弘儒展開一場從法哲學出發的對話,探索 AI 與法治價值之間的緊張關係。
中研院歐美研究所陳弘儒助研究員,從法哲學出發,探索 AI 與法治價值之間的緊張關係。研 之有物
怎麼會對「人工智慧」(AI)與「法律人工智慧系統」(ALI)產生研究興趣?
會對 AI 感興趣是因為我很早就對電腦有興趣,我原本大學想唸資訊工程,因為高中有些科目沒辦法唸,於是去唸文組,大學進入法律系就讀,研究所考入「基礎法學組」研讀法哲學。
後來我到美國讀書,當時 AlphaGo 的新聞造成很大的轟動,啟發我思考 AI 的應用應該有些法律課題值得探討,於是開始爬梳 AI 與法律的發展脈絡。
AI 這個詞大概在 1950 年代被提出,而 AI 與法律相關的討論則在 1970、80 年代就有學者開始思考:我們能否將法律推理過程電腦程式化,讓電腦做出跟法律人一樣的判斷?
事實上,AI 沒有在做推理,它做的是機率的演算,但法律是一種規範性的判斷,所有判斷必須奠基在法律條文的認識與解釋上,給予受審對象合理的判決理由。
這讓我好奇:如果未來廣泛應用 AI 執法,法律或受法律規範的民眾會怎麼轉變?
至於真正開始研究「法律人工智慧系統」(ALI)是受到我父親的啟發。有一陣子我經常開車南北往返,有一天我跟父親聊到用區間測速執法的議題。交通部曾在萬里隧道使用區間測速,計算你在隧道裡的平均速率,如果超速就開罰。
父親就問我:「政府有什麼理由用區間測速罰我?如果要開罰就必須解釋是哪一個時間點超速。」依照一般的數學邏輯,你一定有在某個時間點超速,所以平均起來的速率才會超過速限,可是法律判斷涉及規範性,我們必須思考背後的正當性課題,不能只用邏輯解釋,這啟發我逐漸把問題勾勒出來,試圖分析執法背後的規範性意涵。
如果將執行法律任務的權限賦予 AI,可能暗藏什麼風險?
我們先來談人類和 AI 在做判斷時的差別。人類無時無刻都在做判斷,判斷的過程通常會先做「區分」,例如在你面前有 A 和 B 兩個選項,在做判斷前必須先把 A 和 B 區分開來,讓選項有「可區別性」。
在資料龐大的情況下,AI 的優勢在於能協助人類快速做好區分,可是做判斷還需經歷一段 AI 難以觸及的複雜過程。人類在成長過程中會發展出一套顧及社會與文化認知的世界觀,做判斷時通常會將要區分的選項放進這個世界觀中,最終做出符合社會或自身考量的抉擇。
當我們將判斷程序交由 AI 執行,就會涉及「判斷權限移轉」 的問題,這經常在日常生活中發生,你只要發現原本自己可以執行的事情,有另外一個對象做的比你好或差不多好,你就會漸漸把判斷的工作交給它,久而久之,你大概會覺得這是很好的做法,因為可以節省大量時間。
我擔心這種判斷權限移轉會快速且廣泛的發生,因為 AI 的工作效率極高,可以大幅節省人力成本,但是哪一些權限可以放給 AI?哪一些權限人類一定要守住?我們經常沒有充足的討論,等到發生問題再亡羊補牢可能為時已晚。
以讓道給救護車而闖紅燈的情境為例,如果讓 AI 來做交管,可以節省警察人力,又可以快速精準地開罰,卻迫使民眾需額外花時間,證明闖紅燈有正當理由。如果是真人警察來判斷,警察通常會認為你的行為有正當理由而不開罰。這對於受法律規範的民眾來說,會產生兩種全然不同的規範作用。
AI 產生的規範作用會讓民眾擔心事後銷單的麻煩程序,如果無法順利解決,可能會訴諸民意代表或上爆料公社,並漸漸改變民眾對守法的態度。而真人警察產生的規範作用,將使民眾自主展現對法律的高度重視,雖然當下的行為牴觸法律,卻是行為人經過多方權衡後做的判斷,相信法律會支持自己出於同理心的行為。
使用 AI 執法除了看上它的高效率,也是因為和真人相比 AI 不會受私情影響,比較可以做出公正的判斷。如果從法治觀念來看,為何決策權不能全權交由 AI 執行?
我認為法治的核心價值在臺灣並沒有很好的發展,我們常想的是怎麼用處罰促成民眾守法,長久下來可能會得到反效果。當人們養成凡事規避處罰的習慣,一旦哪天不再受法律約束,可能會失去守法的動機。
事實上,法治最根深柢固的價值為:
法律作為一種人類行為規範的展現,促使民眾守法的方式有很多種,關鍵在於尊重人的道德自主性,並向民眾陳述判決理由。
給理由非常重要,可以讓民眾不斷透過理由來跟自己和法律體系溝通。如此也可以形成一種互惠關係,使民眾相信,國家公權力能用適當的理由來制定法律,而制定出的法律是以尊重公民自主性為主。當民眾理解法律對我所處的社會有利,會比較願意自動產生守法的動機。
AI 執法看似比人類「公正無私」,但它的執法方式以處罰為主、缺乏理由陳述,也沒有對具體情境的「敏感性」。人跟人之間的互動經常需要敏感性,這樣才能理解他人到底在想什麼。這種敏感性是要鍛鍊的,真人警察可在執法過程中,透過拿捏不同情境的處理方式來累積經驗。
例如在交通尖峰時段應該以維持交通順暢為原則,這時警察是否具備判斷的敏感性就很重要,例如看到輕微的違規不一定要大動作開罰,可以吹個警笛給駕駛警示一下就好。
我越來越覺得人類這種互動上的敏感性很重要,我們會在跟他人相處的過程中思考:跟我溝通的對象是什麼樣的人?我在他心中是什麼模樣?然後慢慢微調表現方式,這是人類和 AI 最根本的不同。
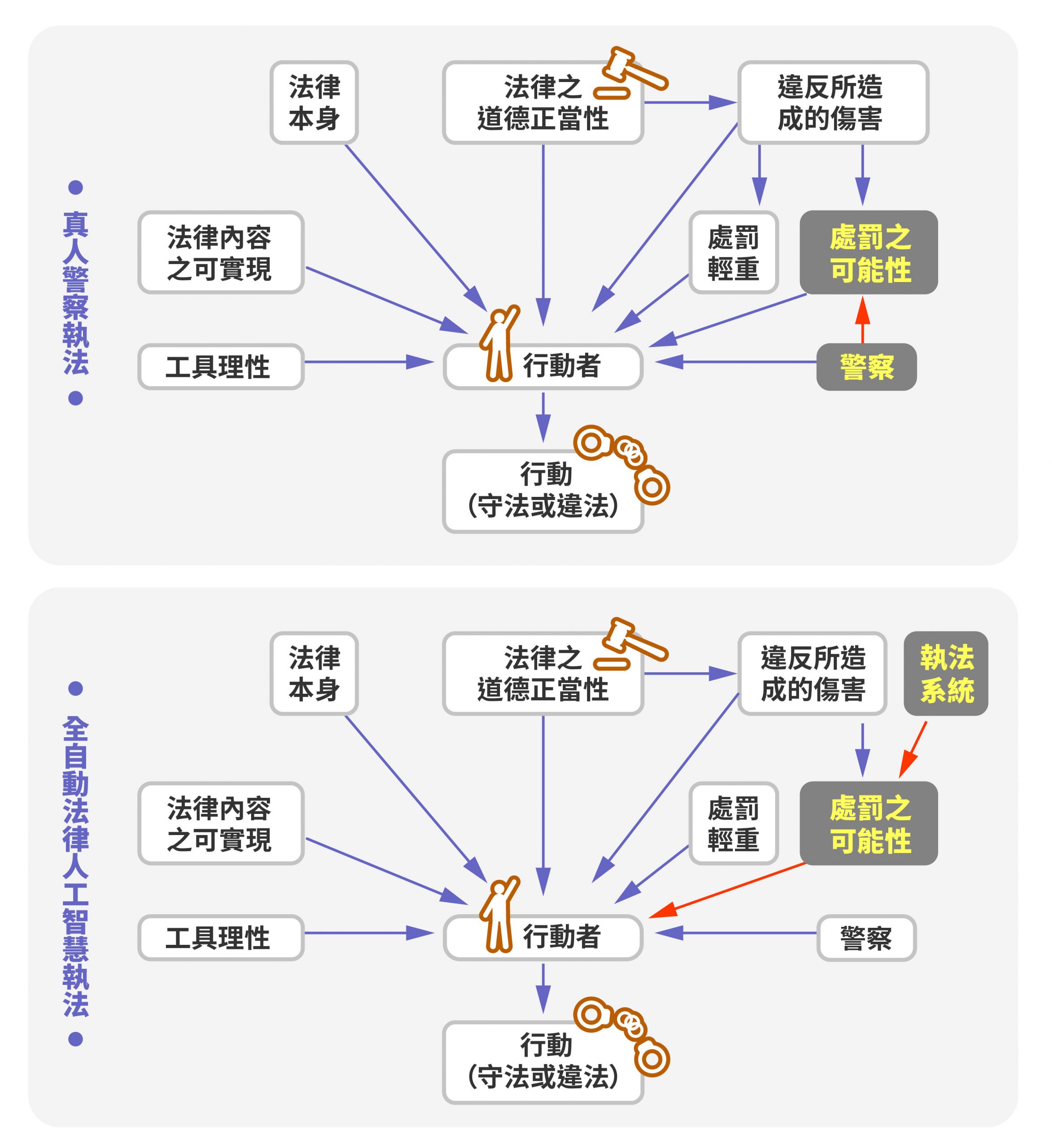
行動者受各種法律變項影響的因果圖。上圖是由真人警察執法,對於處罰之可能性有影響力,可依不同情境判斷是否開罰。下圖是由全自動法律人工智慧執法,由 AI 直接將處罰之可能性加諸在行動者身上,缺乏真人警察二次確認,很可能影響行動者對守法與否的衡量。研 之有物 (資料來源|陳弘儒)
相較於法律人工智慧,ChatGPT 等生成式 AI 強大的語言功能似乎更接近理想中的 AI,其發展可能對我們產生哪些影響?
我認為會有更複雜的影響。ChatGPT 是基於大型語言模型的聊天機器人,使用大量自然語言文本進行深度學習,在文本生成、問答對話等任務上都有很好的表現。因此,在與 ChatGPT 互動的過程中,我們容易產生一種錯覺,覺得螢幕後好像有一名很有耐心的真人在跟你對話。
事實上,對於生成式 AI 來說,人類只是刺激它運作的外在環境,人機之間的互動並沒有想像中的對等。
仔細回想一下整個互動過程,每當外在環境(人類)給 ChatGPT 下指令,系統才會開始運作並生成內容,如果我們不滿意,可以再調整指令,系統又會生成更多成果,這跟平常的人際互動方式不太一樣。
ChatGPT 能讓使用者分辨不出訊息來自 AI 或真人,但事實上 AI 只是接受外在環境(人類)刺激,依指令生成最佳內容,並以獲得正向回饋、提升準確率為目標。iStock
資工人員可能會用這個理由說明,生成式 AI 只是一種工具,透過學習大量資料的模式和結構,從而生成與原始資料有相似特徵的新資料。
上述想法可能會降低人們對「資料」(Data)的敏感性。由於在做 AI 訓練、測試與調整的過程中,都必須餵給 AI 大量資料,如果不知道資料的生產過程和內部結構,後續可能會產生爭議。
另一個關於資料的疑慮是,生成式 AI 的研發與使用涉及很多權力不對等問題。例如現在主流的人工智慧系統都是由私人公司推出,並往商業或使用者付費的方向發展,代表許多資料都掌握在這些私人公司手中。
資料有一種特性,它可以萃取出「資訊」(Information),誰有管道可以從一大群資料中分析出有價值的資訊,誰就有權力影響資源分配。換句話說,多數人透過輸入資料換取生成式 AI 的服務,可是從資料萃取出的資訊可能在我們不知情的狀況下對我們造成影響。
面對勢不可擋的生成式 AI 浪潮,人文社會學者可以做些什麼?
國外對於 AI 的運用開始提出很多法律規範,雖然國外關於價值課題的討論比臺灣多,但並不代表那些討論都很細緻深入,因為目前人類跟 AI 的相遇還沒有很久,大家還在探索哪些議題應該被提出,或賦予這些議題重新認識的架構。
這當中有一個重要課題值得思考:
我們需不需要訓練 AI 學會人類的價值判斷?
我認為訓練 AI 理解人類的價值判斷很可能是未來趨勢,因為 AI 的發展會朝人機互動模式邁進,唯有讓 AI 逐漸理解人類的價值為何,以及人類價值在 AI 運作中的局限,我們才有辦法呈現 AI 所涉及的價值課題。
當前的討論多數還停留在把 AI 當成一項技術,我認為這種觀點將來會出問題,強大的技術如果沒有明確的價值目標,是一件非常危險的事情。實際上,AI 的發展必定有很多價值課題涉入其中,或者在設計上有一些價值導向會隱而不顯,這將影響 AI 的運作與輸出成果。
思考怎麼讓 AI 理解人類價值判斷的同時,也等於在問我們人類:對我們來說哪一些價值是重要的?而這些重要價值的基本內容與歧異為何?
我目前的研究有幾個方向,一個是研究法律推理的計算機模型(Computational models of legal reasoning);另一個是從規範性的層面去探討,怎麼把價值理論、政治道德(Political morality)、政治哲學等想法跟科技界交流。未來也會透過新的視野省視公民不服從議題。
這將有助科技界得知,有很多價值課題需要事先想清楚,影響將擴及工程師怎麼設計人工智慧系統?設計過程面臨哪些局限?哪些局限不應該碰,或怎麼把某些局限展現出來?我覺得這些認識都非常重要!
鐵面無私的 ALI ?人類與人工智慧執法最大的分野是什麼?
陳弘儒的研究室有許多公仔,包括多尊金斯伯格(Ginsburg)公仔,她是美國首位猶太裔女性大法官,畢生為女權進步與性別平權奮鬥。研 之有物 陳弘儒是臺灣少數以法哲學理論研究法律人工智慧系統(ALI)的學者,他結合各種現實情境,與我們談論 ALI、生成式 AI 與當代法治價值的緊張關係。
由於 ALI 擅長的資料分類與演算,與人類判斷過程中涉及的世界觀與敏感性思辨,有著根本上的差異;以處罰為主、缺乏理由陳述的判斷方式,也容易影響民眾對公權力的信任。因此陳弘儒認為,目前 ALI 應該以「輔助人類執法」為發展目標,讓人類保有最終的判斷權限 。
至於現正快速發展的生成式 AI ,根據陳弘儒的觀察,目前仍有待各方專家探索其中的價值課題,包括資料提供與使用的權力不對等、哪些人類價值在訓練 AI 的過程中值得關注等。
在過去多是由人文社會學者提出警告,現在連 AI 領域的權威專家也簽署公開信 並呼籲:AI 具有與人類競爭的智慧,這可能給社會和人類帶來巨大風險,應該以相應的關注和資源進行規劃和管理 。
在訪談過程中,有一件令人印象深刻的小插曲,陳弘儒希望我們不要稱呼他「老師」,因為他從小就畏懼老師、警察等有權威身分的人,希望以更平等的方式進行對話。
假如今天以 AI 進行採訪,整個談話過程或許能不受倫理輩分影響,但這也讓我們意識到,在 AI 的世界裡,許多人際互動特有的敏感性、同理反思都可能不復存在。
陳弘儒的研究讓我們體會,AI 在法治領域的應用不僅是法律問題,背後更包含深刻的哲學、道德與權力課題,也讓我們更了解法治的核心價值:
法律要做的不只是規範人們的行為,而是透過理由陳述與溝通展現對每個人道德自主性的尊重。