


「有證據了!茲卡病毒真的會導致胎兒畸形!」——美國疾管署(2016/04/13) [1]
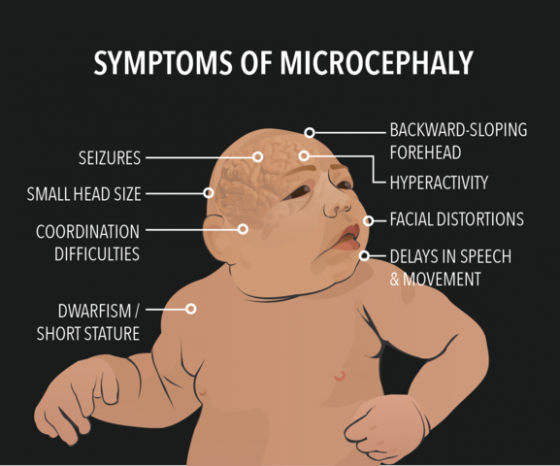
難以預警的疫情
2015 年年初,茲卡病毒在巴西爆發大流行,由於疾病的症狀不嚴重,僅有輕微地紅疹、結膜炎、關節痛等 [2],所以沒有引起太多注意。沒想到數個月後,多名曾感染茲卡病毒的孕婦產下畸形兒,全球的科學家才赫然發現,這個乘著埃及斑蚊而來的病毒,將是人類未曾想像過的殺手……
病徵不顯著,卻有無法承擔的併發症
不明顯的病徵,使得患者可能會忽視病況、選擇在家休息而不去就醫,導致政府無法監控疫情。而蚊蟲更加速了疫情的擴散,南美洲的疫情自 2015 年年初至今,推測已超過 1 百萬人感染 [3, 4]。種種的因素加總,導致南美洲的疫情嚴重度,完全出乎所有人的預料 [5, 6] [註1]。
中國、東南亞等國是觀察重點
巴西即將在 2016 年迎接奧運,大量的國際旅客可能會把病毒帶往全世界。資料科學家利用巴西各大機場的飛航紀錄進行分析,發現從巴西搭機飛往亞洲的旅客,絕大多數人都是前往中國。此發現顯示中國在夏季來臨之時,將面臨茲卡病毒嚴峻的挑戰 [4]。而鄰近的台灣,該如何預警即將襲來的茲卡病毒呢?
用關鍵字搜尋熱門度預測茲卡疫情?
Google 在數年前即發現,當流感爆發之時,民眾鍵入特定關鍵字(如:發燒)的頻率就會增加。以此現象為基礎,Google 公司和美國疾病管制署合作,設計了以關鍵字搜尋熱門度為基礎的預警模型,其成果甚至於發表在知名學術論文 [7] [註2]。(延伸閱讀:台灣流感疫情也可以問問 Google 大神!)
那麼茲卡疫情,能不能也比照辦理呢?以下是本文的分析條件:
表1:2015 年巴西茲卡疫情分析條件
| 時間範圍:2015/02/18~06/13 | |
| 搜尋限制:巴西/葡萄牙語 | |
| 疾病 | 疑似感染茲卡病毒病例數 |
| 資料來源:Emerging Infectious Diseases journal, 21, 2274-6 | |
| 症狀 | 發燒、紅疹、頭痛、關節痛和充血性結膜炎 |
| 潛伏期 | 三天~一週 |
| 資料來源:中華民國疾病管制署 | |
| 關鍵字A | erupção (紅疹) |
| 關鍵字B | artralgia (關節痛) |
| 資料來源:Google趨勢(Google Trend) | |
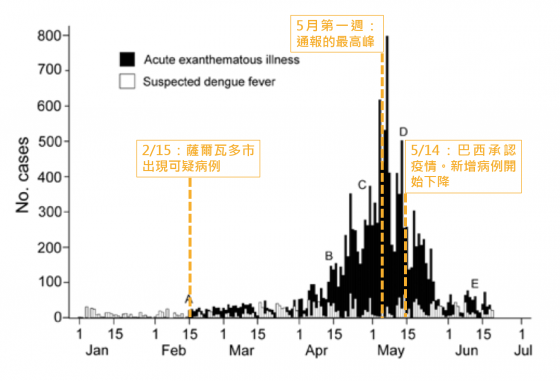
下圖是刊登在《新興傳染疾病》期刊(Emerging Infectious Diseases journal)的患者趨勢圖,顯示了巴西薩爾瓦多市的疫情變化。從圖中可以明顯地看到,該市在 2/15 出現疑似病例,而在4月第二週時,人數開始上升,並在 5 月第一週時達到高峰 [3, 5, 8-10]。
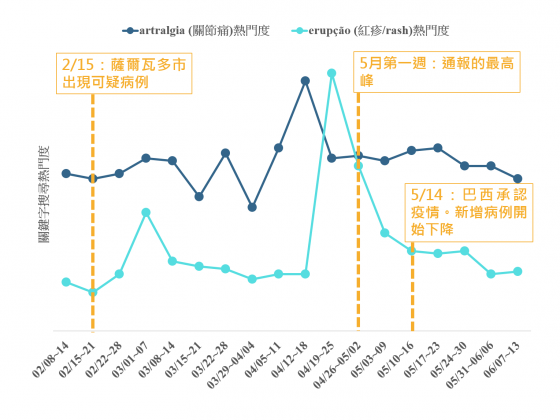
那麼用葡萄牙語的「紅疹」和「關節痛」的搜尋熱門度變化呢?從下圖中可以看出,「紅疹」的熱門度在 4 月第三週時出現明顯的高峰,早於醫院回報病例的高峰時間(5 月第一週),約提早了一週。這項觀察暗示了相較於醫院逐一回報病例的傳統模式,利用民眾在 Google 搜尋的變化量來監控茲卡疫情,有機會讓衛生單位獲得更多的預警時間!更早地評估當地的疫情趨勢。
而「關節痛」的搜尋熱門度,也相同地出現了顯著的高峰,發生的時間約在 4 月第二週,亦早於醫院回報病例的高峰時間(5 月第一週),約提早了兩週。暗示「關節痛」和「紅疹」關鍵字,都有潛力協助預警、評估巴西茲卡疫情的變化!
用群眾行為模式判斷疫情的優勢和缺點
近年來在金融、影視界裡,觀察群眾行為而作出未來趨勢判斷的例子越來越多(如:Netflix 打造熱門影視「紙牌屋」、巨量數據預測期貨價格)。而從上文中可以發現到,若以 Google 關鍵字搜尋變化作為本次巴西茲卡疫情的預警、評估系統,比起讓醫院逐一回報病例的方式,利用群眾行為來推測流行病,將有機會能夠盡早評估疫情,使政府擁有更多的防疫時間!
但利用 Google 關鍵字搜尋來判斷疫情會有以下的限制:
1) 其它疾病會影響結果,如:感冒也會引起關節疼痛。
2) 無症狀的患者無法追蹤。
3) 不使用 Google 的民眾亦無法追蹤。
雖然有上述的限制,但我認為由於 Google 數據的即時性高、反應快且成本低,未來在台灣的公衛防疫領域上,也許將是一種值得投資的預警模式。
寫在文末:面對茲卡,我們可以怎麼做?

對台灣來說,茲卡病毒是極為陌生的疾病,而該病毒的媒介——埃及斑蚊,卻是南台灣熟悉的老對手。面對既陌生又熟悉的敵人,我認為從中央、地方和民眾都有一些工作可以思考:
【中央】
研發廣效型快篩試劑
目前無法用血清學的方式區分茲卡病毒、登革熱和黃熱病[11],但換言之,若能研發廣效型的抗體,就能廣效性地辨識此群病毒,將十分有利於將疫情阻隔於台灣海關之外。[註3](補充:疾管署已在 4/13 宣佈台灣將進口登革熱、茲卡、屈公熱的三合一快篩試劑。)
促進且推廣正確的知識給一般民眾
未知將引起恐懼。政府應和媒體合作,如公信力高的維基百科、泛科學、科學人等;傳播力強的傳統媒體,如:民視、聯合報、蘋果日報等。政府和媒體協同產出科普性強的資訊,並利用網路傳播來確保流通資訊的正確性,避免錯誤的訊息造成恐慌,甚至阻礙政府的防疫措施。
研究台灣過往的病例
美國曾報導特殊的患者,同時被帶有登革熱和茲卡病毒的蚊子叮咬而共同感染,進而出現了近 40 ℃ 的高燒 [10],和典型的茲卡症狀有很大的差異。上述案例顯示某些患者感染茲卡病毒後,可能產生預料之外的症狀。而台灣民眾有許多獨有的盛行疾病,如:糖尿病、洗腎,若能先從病例中取得資訊,就能達到「多一分準備,少一分害怕」的目標。
研究畸形兒和登革熱之間的關係
由於茲卡病毒能引發畸形兒,而同為黃病毒科的登革熱病毒是否也會引起類似的併發症,將是學界未來可研究的方向。
【地方】
建置疫情模擬系統
利用氣象局的雨量、濕度資料庫,結合市府的城市發展、地籍資料,對於疫情進行模擬和預測。此概念在國內學界,政府單位皆有先例,如「疾管署科技發展計畫」及「中原大學和氣象局合作研究計畫」等。
【民眾】
孕婦或計畫懷孕的女性,避免前往中南美洲
若從疫區返國後產生症狀,務必告知醫師旅遊史的細節
閱讀公信力高的資訊,避免不必要的擔憂
我們天生都會對陌生的事物感到恐懼,而在網路時代裡,恐慌 = 對事件的不瞭解 X 事件的嚴重度。所以除了要努力製造「正確的資訊」,也要強化「正確資訊的流通力」,才能讓身在防疫前線的醫學、公衛專家們,好好地保護我們所愛的台灣!
- 本文感謝衛生福利部台東醫院檢驗科張昱維(Yu-Wei Chang)、UDN 聯合報系媒體創新研發中心研究員陸子鈞及病後人生—一站式服務網站長羅佩琪協助。
註釋:
- 茲卡病毒和畸形兒的關聯,仍需流行病學的進一步證實。
- 利用 Google 做為流行病的分析並非首創,請見〈用大數據畫出伊波拉救命地圖:看Big Data如何做疾病預測〉或〈大數據(Big Data)於疾病研究之應用〉。
- 我並不支持研發疫苗,雖然WHO和部分公司正研發疫苗 [11],但我認為要找到願意測試疫苗安全性的孕婦,會有很大的困難。
參考文獻:
- CDC Concludes Zika Causes Microcephaly and Other Birth Defects. 美國疾管署官方網頁
- 茲卡病毒感染症。衛生福利部疾病管制署官方網頁。
- Zanluca C, de Melo VC, Mosimann AL, Dos Santos GI, Dos Santos CN, Luz K. (2015) First report of autochthonous transmission of Zika virus in Brazil, Memórias do Instituto Oswaldo Cruz, 110(4), 569-572
- Bogoch II, Brady OJ, Kraemer MU, German M, Creatore MI, Kulkarni MA, Brownstein JS, Mekaru SR, Hay SI, Groot E, Watts A, Khan K. (2016) Anticipating the international spread of Zika virus from Brazil, The Lancet, 387(10016), 335-336
- Possible Association Between Zika Virus Infection and Microcephaly — Brazil, 2015. 美國疾病管制署官方網頁。
- Zika virus epidemic in the Americas: potential association with microcephaly and Guillain-Barré syndrome. 歐洲疾病管制署官方網頁。
- Jeremy Ginsberg, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski & Larry Brilliant (2009) Detecting influenza epidemics using search engine query data. Nature, 457, 1012-1014
- Cardoso CW, Paploski IA, Kikuti M, Rodrigues MS, Silva MM, Campos GS, Sardi SI, Kitron U, Reis MG, Ribeiro GS. (2015) Outbreak of Exanthematous Illness Associated with Zika, Chikungunya, and Dengue Viruses, Salvador, Brazil, Emerging Infectious Diseases journal, 21(12), 2274-2276
- Zika virus. 世界衛生組織官方網頁。
- Dupont-Rouzeyrol M, O’Connor O, Calvez E, Daurès M, John M, Grangeon JP, Gourinat AC. (2015) Co-infection with Zika and dengue viruses in 2 patients, New Caledonia, 2014, Emerging Infectious Diseases journal, 21(2), 381-382
- Bharat Biotech says working on two possible Zika vaccines. REUTURES新聞。



































