美國哈佛史密松恩天文物理中心(Harvard-Smithsonian Center for Astrophysics,CfA)天文學家Jennifer Yee等人利用美國航太總署(NASA)史匹哲太空望遠鏡(Spitzer Space Telescope)和OGLE(Optical Gravitational Lensing Experiment)計畫位於智利Las Campanas觀測站的Warsaw望遠鏡進行聯合觀測,發現一顆距離遠達13000光年的氣體行星OGLE-2014-BLG-0124L,是迄今已知最遠的系外行星之一。這項發現有助於天文學家瞭解系外行星在扁平、螺旋狀的銀河系中如何分布:究竟是比較喜歡集中在星系中心區域呢?還是會平均散佈在銀河各處?
OGLE計畫是以微重力透鏡(microlensing)方式搜尋系外行星,即當某顆恆星行經另一顆遠方恆星與地球之間時,其微弱的重力場會類似放大鏡般,將遠方恆星的光集中並變亮;如果這顆前景恆星恰好有行星環繞,將使遠方恆星亮度變亮加劇,天文學家便可藉此事件察覺系外行星的存在。
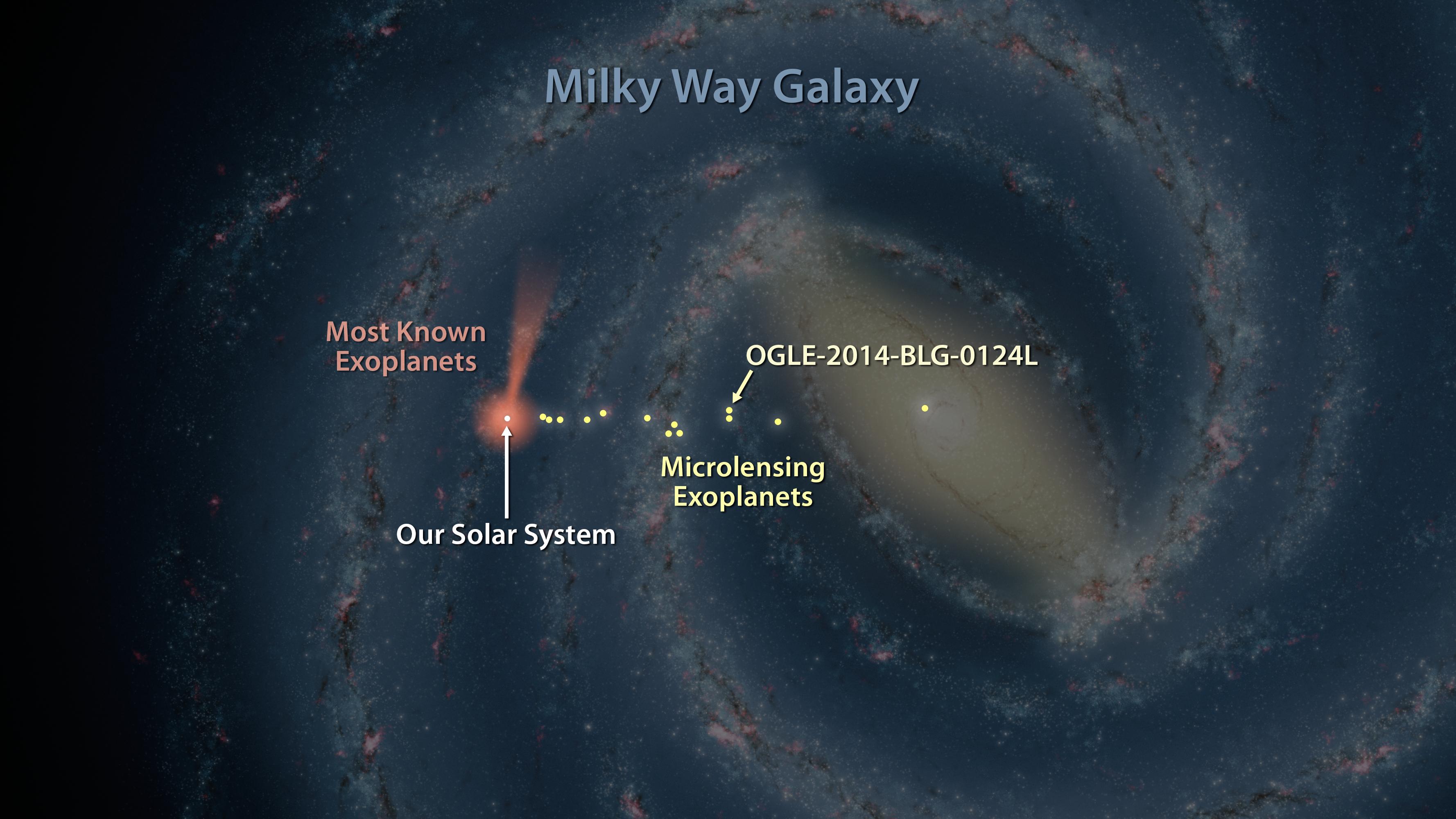
我們的太陽系其實是位在銀河系的郊區,約銀河系半徑2/3之處。利用微重力透鏡法,可以偵測從太陽系鄰近區域一直到銀河中心區,可偵測範圍比其他系外行星偵測方式廣泛得多,因此與其他偵測方式相互配合的話,可有效地瞭解整個銀河系內的系外行星分布概況。其中,離地球約27000光年遠的銀河系核球區,因恆星密度高,彼此遮蔽的機會也隨之增加,是微重力透鏡事件最容易發生的方向。到目前為止,已經以微重力透鏡法在核球區發現約30顆系外行星,其中最遠的約為25000光年左右。
雖然微重力透鏡可以偵測比較遠的系外行星,但卻有個關鍵問題:它無法精確的測定造成微重力透鏡事件的前景天體的距離。事實上,若不是遠方恆星的亮度被增亮,有時候根本連前景恆星都無法察覺其存在與否。所以,測定精確距離變成是微重力透鏡法的最大挑戰。事實上,迄今已知的30個以微重力透鏡法發現的系外行星中,有半數不知其精確位置,這讓天文學家彷彿抱著沒有標示「X」的藏寶圖一般,不知該如何下手去尋寶。

在史匹哲太空望遠鏡的協助下,天文學家終於有機會找到藏寶圖上那個X標示之處。史匹哲太空望遠鏡距離地球約2億700萬公里,跟隨地球之後一起繞太陽公轉。由於和地球相距甚遠,因此當史匹哲太空望遠鏡與在地球上的望遠鏡觀測到同一個微重力透鏡事件時,它們「看到」背景恆星變亮的時間點並不相同,從兩座望遠鏡觀測到變亮的時間差便可估算出前景天體的距離。這和一般的「視差法(parallax)」一樣,故稱為「微重力透鏡視差法(microlens parallax)」;這也是天文學家第一次用微重力透鏡視差方式獲得系外行星的距離訊息。
利用太空望遠鏡觀察微重力透鏡事件並不容易。地面望遠鏡一旦偵測到微重力透鏡事件後會立即向天文社群發佈「警報」,不過這個觀測活動很快就結束,平均只有約40天左右。史匹哲團隊得趕在收到警報的3天後,倉促地排開其他原已排定的觀測工作,轉而開始觀測微重力透鏡事件。
在這顆新發現的系外行星OGLE-2014-BLG-0124L案例中,微重力透鏡現象持續了150之久,與往常案例相較之下就顯得相當不尋常。OGLE首先偵測到這個事件,而後史匹哲也加入監測的行列;之後OGLE和史匹哲都偵測到象徵有系外行星的亮度突亮的現象,不過史匹哲觀測到的時間比OGLE早了20天左右。Yee等人由此估算這顆行星的距離約13000光年;而一旦知道距離之後,又由此估算出這顆行星的質量約為0.5倍木星質量,因此比較可能是顆氣體行星,而非類似地球這樣的岩質行星。
到目前為止,史匹哲和OGLE及其他地面望遠鏡已經合作觀測了其他22個微重力透鏡事件,雖然都沒有發現新的系外行星,但還是可據以瞭解並統計銀河中心區的恆星和行星的族群分布狀況。因此根據計畫,史匹哲太空望遠鏡在今年夏季將要監測120個額外的微重力透鏡事件,以便達到天文學家想要進行的統計目標。
資料來源:
- Spitzer, OGLE Spot Planet Deep Within Our Galaxy. [2015.04.14, CfA]
本文轉載自網路天文館。