-200x200.jpg)
18 世紀工業革命,人力從家庭進入工廠,連孩子們也無法倖免。為了保障童工的權利,1819 年英國制定了《工廠法》(Factory Act),規範合法工作年齡和時數。[1]現在 COVID-19 又把部份勞工趕回去,在家工作的現象,竟讓英國企業動了「善用」童工的念頭……。
學童成為人工智慧幕後推手

2020 年英國政府因應 COVID-19 疫情,成立了「橡樹國家學院」(the Oak National Academy)網路平台,提供線上教學課程。這招多少能挽救受學校停課影響的教學品質,但解決不了封城或隔離期間課後活動的匱乏,無聊到快抓狂的孩子,差點逼瘋在家工作的家長。此時,數位病理科技集團 PathLAKE 橫空出世,為家長分憂,「順便」利用學童來發展人工智慧。[2]

- 人工智慧(artificial intelligence)的「機器學習」(machine learning),大略分為三種:
- 監督式機器學習(supervised machine learning):把標註好的資訊,餵給機器。由於標註的步驟是人類執行的,機器在學習的過程中,會逐漸朝人類設定的目標,愈加精準。[3]
- 非監督式機器學習(unsupervised machine learning):要求程式從未標註的資料中,找出現象或模式。在人類沒有插手的狀況下,有時會得到出乎意料的結果。[3]
- 增強式機器學習(reinforcement machine learning):設下獎勵機制,讓機器從嘗試中學習。例如:告訴自駕車它在行駛中,做對了哪個決定。[3]
PathLAKE 集團想做的是病理圖像的「監督式機器學習」。然而,標註資料的工作耗時費力,近年選擇從事病理科工作的醫師比例又大不如前。於是,「童工」就成為填補業界人力空缺的另類解方。
PathLAKE 的策略,大致上是這樣的:首先,昭告天下說這裡有個線上課外活動,即將開放給學童參加。拐來一票願意簽署同意書的家長後,先教他們的小孩癌細胞長怎樣。等小鬼頭們學得差不多,便可以玩遊戲闖關,藉此驗收他們的學習成果。依循此模式,將來或許就能聘僱為數龐大的「童工」,來標註病理圖像,然後再以此數據資料訓練人工智慧機器。[2]

「打敗病理學家」細胞形態辨識競賽
PathLAKE 集團舉辦的活動分二個梯次,每次都招募 3 個不同年齡層的學童:4 到 11 歲、11 至 16 歲以及 16 到 18 歲。他們透過網路學習基礎的「細胞形態學」(cell morphology),以辨識乳癌細胞染色影像的 4 種類型:陽性癌細胞(positive tumour cell)、陰性癌細胞(negative tumour cell)、陽性非癌細胞(positive non-tumour cell),還有陰性非癌細胞(negative non-tumour cell)。課程結束,便參與競賽。[2]
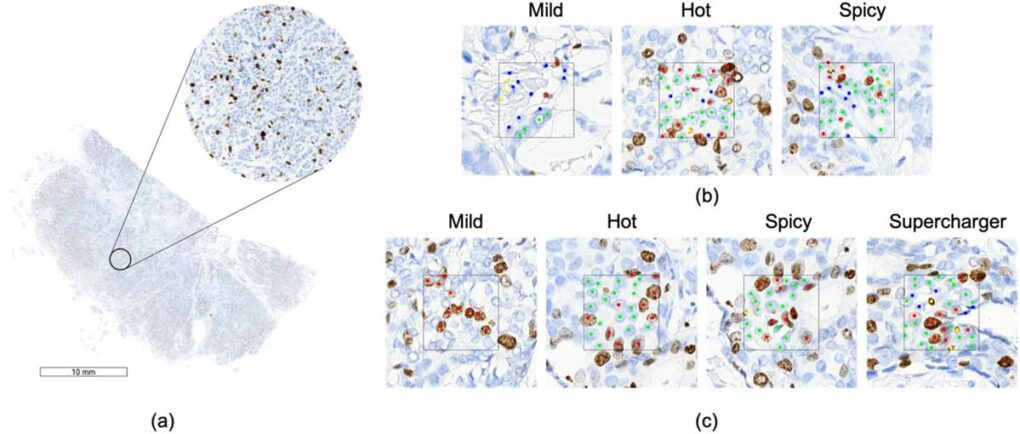
以下是二個梯次競賽部份的內容與差異:[2]
- 測試版競賽(Pilot competition):
- 關卡:遊戲總共有三關,關卡名稱「微辣」(Mild)、「中辣」(Hot)、「大辣」(Spicy),聽起來頗像麻辣鍋的辣度分級……,每一關分別有 20、30 和 50 張影像,要參賽者辨識。
- 成績:報名並完成線上課程的 28 名學童中,僅有 5 人參加競賽。其中只有 1 人成功地從「微辣」晉級到「中辣」,而「特辣」根本沒人玩。教學和遊戲的難度,明顯須要調整。
- 主要競賽「打敗病理學家」("Beat the Pathologists"):
有了上一梯次的經驗,PathLAKE 團隊修改設計,於 2020 年 10 月的「牛津科學節」(the Oxford Science Festival)推出「打敗病理學家」活動。
- 關卡:這回有「微辣」(Mild)、「中辣」(Hot)、「大辣」(Spicy)以及「特辣」(Supercharger),共 4 個關卡,邀請參賽者分別得挑戰 20、40、60 和 80 張影像。
- 成績:總計 98 位學童登記報名中,有 95 人參與競賽。其中 91 人通過「微辣」考驗,經過層層過關斬將,最終 22 人成功解鎖(含 15 人晉級)「特辣」關卡。
成效與願景
皇家病理學家協會(the Royal College of Pathologists)在 2020 年「國家病理週」(National Pathology Week)期間,宣傳 PathLAKE 的活動。PathLAKE 集團本身也萬分滿意其成效,在 2022 年 5 月 12 日的《科學報告》(Scientific Reports)期刊中,表示「學童有精確標註細胞的高度潛力……,期望此類的競賽不光使他們對病理學和人工智慧產生興趣,還能促進病理學家與電腦科學家的合作」,並預告他們之後會推出一個標註「腺體結構」(glandular structures)的新活動。[2]
當然,看完「資方」的心得與願景,也該來瞭解一下「勞方」的處境。在英國文豪狄更斯(Charles Dickens)小說《孤雛淚》(Oliver Twist)描述的 19 世紀維多利亞時代,兒童被家長或監護人逼迫去工作,工時冗長且勞動環境惡劣。[4]
將近二個世紀的時間過去後,COVID-19 疫情期間的英國學童,是否受到相對優渥的待遇?

從 PathLAKE 團隊的片面描述,我們可以得知:除了病理知識外,每位活動成員均得到參與證書一份,前三名則另有獎項。
參考資料
- Impact of government acts improving working conditions(BBC)
- Lessons from a breast cell annotation competition series for school pupils(Scientific Reports, 2022)
- Machine learning, explained(MIT Sloan School of Management, 2021)
- Children in Dickens’s Novels(International Journal on Studies in English Language and Literature, 2014)







































{kind=link}
{kind=link}
{kind=link}