謝承安/現就讀臺大物理系,因喜愛動畫《戀愛小行星》而喜好小行星
林彥興/現就讀清大天文所,努力在陰溝中仰望繁星
2016 年 9 月 8 日,歐西里斯探測器(OSIRIS-REx)由擎天神五號火箭發射升空,追隨著前輩們 ── 隼鳥號 與隼鳥二號 ── 的腳步,前往近地小行星貝努(101955 Bennu),執行人類史上第三次的小行星取樣任務。
經過兩年多的飛行,歐西里斯號於 2018 年底成功抵達貝努,並在幾個月後成功採集樣本,預計在今年 9 月 24 號返回地球。透過採集小行星上的原始樣本,科學家將能夠推論 46 億年來太陽系的演變歷史,但除此之外,歐西里斯探測器也在環繞貝努的過程中進行了眾多觀測,也為小行星研究貢獻許多,現在就讓我們回顧歐西里斯號的浩瀚之旅!
歐西里斯基本介紹 歐西里斯想像圖。圖/NASA’s Goddard Space Flight Center Conceptual Image Lab 要了解歐西里斯號的觀測目標,我們只需要把他的英文全名攤開來看:
Origins, Spectral Interpretation, Resource Identification, Security-Regolith Explorer
翻譯作太陽系起源、光譜解析、資源識別、安全保障、小行星風化層探索者。其縮寫歐西里斯,是埃及神話中的冥神。儘管你可能無法了解各個專有名詞,但在看過那麼長的名字後,應該也能知道歐西里斯探測器的任務可不僅是採集樣本而已。
歐西里斯號的目標是小行星 101955 號「貝努」。
這是一顆於 1999 年由林肯近地小行星研究小組(LINEAR)發現的近地小行星。之所以選擇貝努作為觀測目標,是因為貝努的軌道與地球十分接近,有撞擊地球的潛在風險,另一方面距離近,也可以讓探測器在較短的時間內抵達。
值得一提的是,「貝努」這個名字源自古埃及神話的神鳥,同時也是引領前往冥界的諸神之嚮導。同時,貝努小行星上的各式地形或是地點,也都是以不同神話中的鳥類來命名。
貝努的表面地圖,圖中的地名皆與鳥類神話有關。如 Strix 來自羅馬神話中的條紋鳥、Simurgh 則來自波斯神話中的西摩格鳥。圖/NASA/Goddard/University of Arizona 在發射後過了兩年,2018 年,歐西里斯號逐漸接近貝努,並以相機模組中的 8 吋望遠鏡(Polycam)不斷進行觀測,直至十二月成功抵達貝努。
而抵達後的第一項任務,就是詳細繪製全小行星的地圖,過去科學家曾經透過金石太陽系雷達來(GSSR)來探測貝努的模樣,但地面上的雷達雖然可以看到貝努的大致形狀,解析度卻仍不足以窺見小行星上詳細的地形起伏,也就無法事先決定採集樣本的地點但藉由探測器上攜帶的雷射測高儀(OSIRIS-REx Laser Altimeter, OLA),歐西里斯號得以透過發射雷射訊號與接收的時間差, 像是測量海底深度的聲納一樣,繪製全小行星的地形高度圖。另外其配載的高解析度相機(MapCam),也可以讓科學家一覽高解析度的貝努影像。
雷射測高儀測量過程示意圖。圖/NASA/Goddard/University of Arizona NASA 哥達德太空中心以歐西里斯號製作的貝努表面導覽。影/Youtube 除了解地形以外,決定採樣地點時,另一項重要的考量是採樣地礦物或化學組成。正如同地球上各處的岩石化學組成不盡相同,不論是含水量、顆粒粗細程度以及有機物的有無,皆是採樣任務執行時需要考量的情況。於是,歐西里斯號使用了三種方法來探測小行星表面上的礦物。
第一種方法是透過風化層 X 射線成像光譜儀(Regolith X-Ray Imaging Spectrometer, REXIS)來觀測 X 射線光譜。讀者或許會想,X 射線多用來觀測高能天體的輻射,像是黑洞、超新星爆發等事件,並且小行星本身也不會發出 X 射線,為何要攜帶這樣的探測儀器?
事實上,當元素吸收到宇宙射線或太陽所發出的 X 射線時,內層的電子會吸收能量並游離,而外層的電子便會向下躍遷,補上原本內層電子的位置,更外層電子又再補上外層電子的位置。在這一連串的過程中,便會發出 X 射線。而由於每個元素的能階都是獨一無二的,藉由觀測X射線的光譜,我們便能了解小行星上各處的元素豐度。
這樣的分析方式被稱作 X 射線螢光分析(X-ray fluorescence, XRF),是一種非破壞性的元素鑑定方式,地質考察、考古甚至是博物館文物鑑定都常利用此方式進行探測。
REXIS 儀器。圖/REXIS Team / The planetary society 另外,歐西里斯號上還配戴可見光與紅外線分光儀(OVIRS),也能夠獲取小行星可見光與紅外線波段的光譜來辨別來辨別礦物或是有機物的種類。並且由於不同礦物的熱導率差異,歐西里斯還可以藉由熱輻射光譜儀(OSIRIS-REx Thermal Emission Spectrometer, OTES)掃描全小行星的熱輻射地圖來了解礦物與化學豐度。
熱輻射儀也可以更進一步用於研究小行星上的熱量傳輸問題。當小行星吸收太陽光後將以輻射的方式將能量釋放時,其光壓會給予小行星一個微小的作用力。在經年累月的作用下,便會對其軌道產生改變,此現象稱之為亞爾科夫斯基效應(Yarkovsky effect)。
由於亞爾科夫斯基效應的強弱會受到小行星的反照率、表面材質甚至是地形而影響,如果對小行星不夠了解,那預測小行星軌道的難度將大幅提升。因此歐西里斯號的近距離探測,對精準預測貝努的軌道非常重要。
樣本採集:歐西里斯與貝努的零距離接觸 在近兩年的搜集數據後,歐西里斯號便開始執行此次任務的最終目標:採集樣本。
一開始,科學家們有四個候選地點:夜鷺(Nightingale),此處位於年輕的隕石坑上,且具有最細顆粒的礦物;翠鳥(Kingfisher)為新的隕石坑並具有豐富的含水量;魚鷹(Osprey)具有較低反照率的岩石樣本;鷸(Sandpiper)位於兩個隕石坑之間,可能含有水合礦物。
在科學家掙扎的選擇後,最終決定在名為「夜鷺」的地點進行採樣。因為此處較年輕的地質特性,能夠讓我們採集到貝努更原始的樣本,以此探討貝努在太陽系闖蕩時所遺留的痕跡,再加上較細的礦物也能讓執行任務時能有較高的成功率。至於其他候選地點,只能說後會有期了。
NASA所選定的四個樣本採集地點之照片。圖/NASA/Goddard/University of Arizona 2020年10月20號,歐西里斯號伸出他的機器手臂,名為 Touch-And-Go Sample Acquisition Mechanism(TAGSAM),顧名思義便是碰一下小行星表面後便離開。其運作原理,是在碰觸到小行星表面時釋放加壓氮氣產生爆炸,再搜集飛散出來的碎屑樣本。
說起來雖然簡單,但降落在微小重力的且未知內部構造的小行星上其實非常困難,科學家們需要考量到所有可能影響的作用力,甚至是太陽光所造成的輻射壓都必須考慮進去。
現在,想像你是個科學家,坐在任務的控制室中,透過相機模組中的 SamCam,望著歐西里斯號逐漸靠近小行星,3,2,1⋯⋯,碰!(狀聲詞,事實上,太空中是沒有聲音的。)
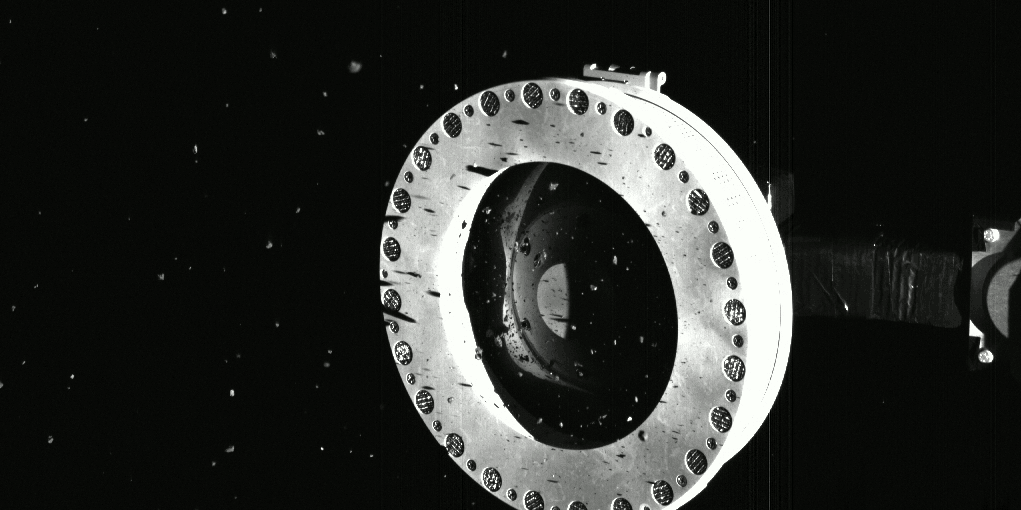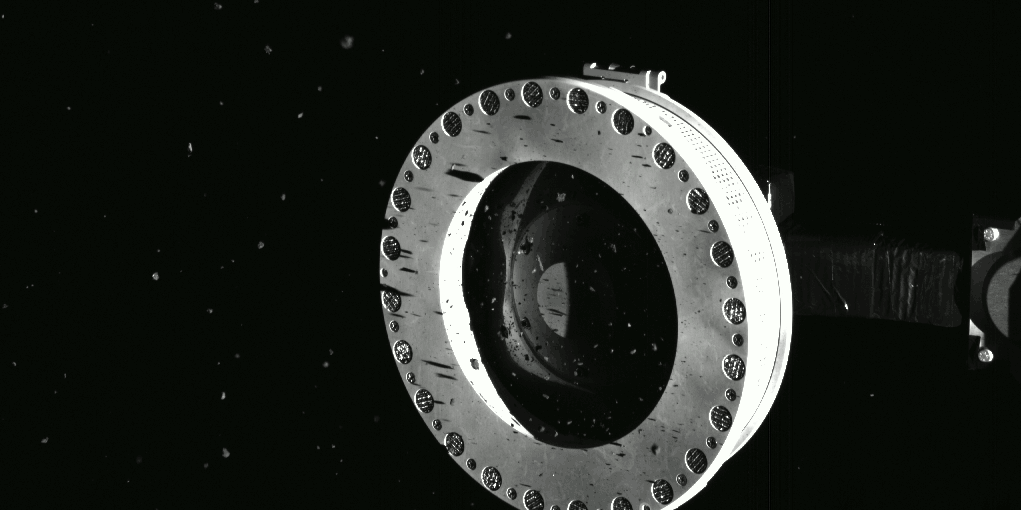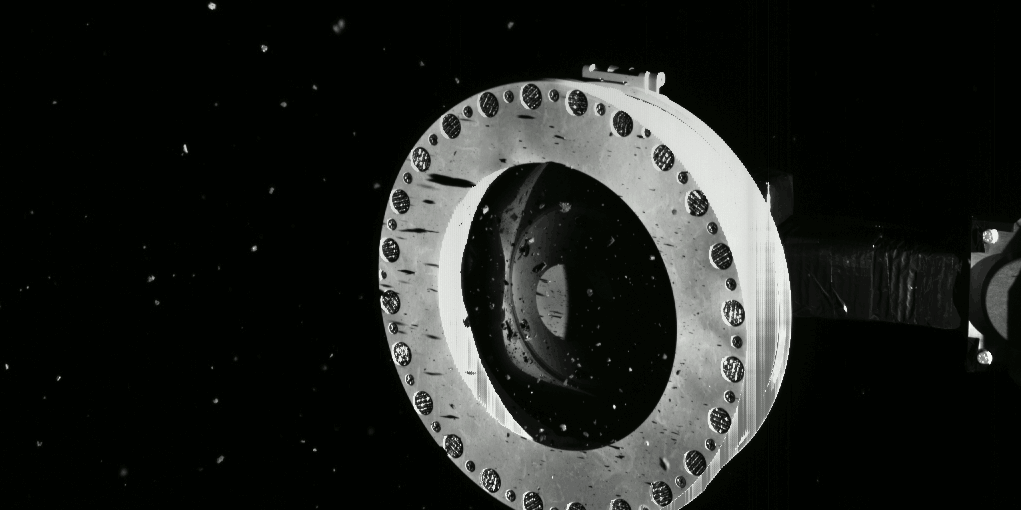
Touch-And-Go任務的執行過程。圖/NASA/Goddard/University of Arizona 採集任務看似十分成功,歐西里斯號將 TAGSAM 的頂端放入樣品返回艙(Sample Return Capsule, SRC)中,SRC 也使用了眾多隔板將散落在太空中的碎屑放入其中,兩天後,歐西里斯號回傳了樣本採集艙的影像,確認歐西里斯號已搜集足夠的樣本,但此時卻發現了些意外,由於採集的樣本太大顆,艙門無法完全緊閉,導致有部分樣本散逸至太空中,還好這不影響任務的完成,算是有驚無險。
小行星的樣本從樣品返回艙中散逸。圖/NASA/Goddard/University of Arizona 2021 年 4 月 7 日,歐西里斯號展開他的最後一次飛越任務,此次他以超近距離(約 3.5 公里)觀測「夜鷺」在採集後的模樣,可以清楚看見採樣任務前後的區別,中心區域產生了一個深度超過45公分的凹痕! 周圍的岩石也因此錯位。
過去天文學家們透過眾多觀測數據推論,大多數的小行星比起堅硬的石頭,更像是散亂的碎石堆。後來科學家們也透過此次採樣任務確認貝努表面並非像是地殼般的堅硬固體,而比較像是流體般,才產生如此大的凹痕。
「夜鷺」在採樣任務前後的差異。圖/NASA/Goddard/University of Arizona 在做完惜別任務後,2021 年 5 月 10 號,歐西里斯號啟動了他的主引擎,開始返回地球的旅程。預計在今(2023)年 9 月 24 號,裝載著貝努樣本的樣本返回艙將與歐西里斯號脫離,並以秒速 12 公里的高速衝入地球大氣層,並著陸於猶他州的沙漠中,由研究人員回收後取出樣本進行更近一步的分析。
然而歐西里斯號的旅程仍尚未結束。
接下來它將在 2029 年對另一個有潛在撞擊地球風險的小行星 99942 阿波菲斯(APophis)進行觀測。就讓我們歡迎冥神與他所攜帶的樣本歸來,以及期待未來科學上的重大發現吧!
延伸閱讀




 本文同時收錄於《科學史上的今天:歷史的瞬間,改變世界的起點》,由究竟出版社出版。
本文同時收錄於《科學史上的今天:歷史的瞬間,改變世界的起點》,由究竟出版社出版。