最近賓州州立大學(Pennsylvania State University)應用研究實驗室(Applied Research Laboratory)的兩位科學家 Matt Poese 與 Steve Garret 於美國聲學學會(Acoustical Society of America) 年會中發表了一種利用高能量聲波致冷的技術,他們的方法未來有可能取代冷媒的技術,大量應用在冰箱或者是冷氣機的製造上。其實聲波致冷的概念早在二十年前就被提出,投入其中的研究單位、發表的研究成果也不計其數。但是 Poese 與 Garret 引人注目之處在於他們重新設計了一種單一頻率的揚聲器,其體積比起以往的設計大為縮小且效率很高。利用這種揚聲器,他們可以製造出 173 分貝(dB)的高能量聲波。這種聲波有多強呢?一般的搖滾樂演唱會所發出的音量大約是 120 分貝左右,而 173 分貝大約是這種強度的二十萬倍!目前他們所能達到的最低溫大約是攝氏零下八度左右,已經與現行家用冰箱的溫度相去不遠。雖然離商業化還有一段距離,但是 Poese 與 Garret 樂觀的表示,取代冷媒的那一天已經不遠,未來的冰箱將會是非常環保的。
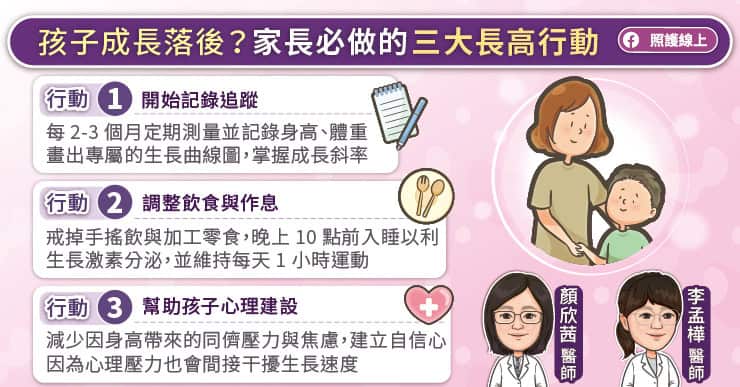
[1]衛生福利部桃園醫院 「空熱量食物」害你長不高 營養師:生長激素會停止分泌 Available at: https://www.tygh.mohw.gov.tw/?aid=309&pid=0&page_name=detail&iid=478%20Accessed%20in%20Mar%202026 Accessed in Jun 2025
[2]Mounir Chennaoui et, al. Sleep and the GH/IGF-1 axis: Consequences and countermeasures of sleep loss/disorders
[3]台灣精準兒童健康協會 淺談生長激素
[4]Mirtz, T. A., Chandler, J. P., & Eyers, C. M. (2011). The effects of physical activity on the epiphyseal growth plates: a review of the literature on normal physiology and clinical implications. Journal of clinical medicine research, 3(1), 1–7
-----廣告,請繼續往下閱讀-----
[5]馬偕兒童醫院 認識生長激素 Available at:https://www.mmh.org.tw/child/know_health_view.php?docid=166&utm_source=chatgpt.com Accessed in Jun 2026
[6]全民健康基金會 擔心小孩長不高?醫師解密身高發育關鍵 Available at:https://www.twhealth.org.tw/journalView.php?cat=74&sid=1263&page=1 Accessed in Jun 2026
[7]亞東紀念醫院院訊 談孩童生長激素缺乏症及治療藥物 Available at:https://www.femh.org.tw/magazine/viewmag.aspx?ID=11336 Accessed in Jun 2026