
還好礙於倫理考量,沒有人打算經由技術手段將奧茲冰人復活。不過冷凍人的復活倒是不少科幻小說中常用的哏。
最早的一篇可以追溯到 1931 年,故事的主角叫詹姆斯,他死後遺體被保存在低溫和真空中發射到太空裡,就這樣漂泊了幾百萬年。後來他的遺體被外星人復活,復活的方式也十分特殊:只復活了他的頭顱,並為他裝上了機械身體。就這樣在人類已經滅絕的時代,詹姆斯獲得了永生。
其實在現實中,雖然幾百上千年不好說,但要讓一個人凍上幾十年,並且仍具有「復活」可能性的技術早已出現,那就是人體冷凍技術。
獲得永生的起點——人體冷凍
1962 年,羅伯特.艾丁格博士(Robert Ettinger)出版的《永生不死的前景》一書,是現實中的人體冷凍的起點。艾丁格博士在書中指出:人類和大量低等動植物一樣,具有「冷凍復活」的潛力。他還在書中預言人體冷凍技術可以使「我們大多數人獲得永生不朽的機會」,並對此進行了嚴密的科學論證。這本書的出版標誌著人體冷凍保存運動的開端,艾丁格博士後來也因此被稱作「人體冷凍之父」。
人體冷凍並不是簡單地將人一凍了之,而是以在未來的某個時刻將冷凍的人體喚醒為目的的冷凍。因此,在技術上,不但要考量如何將人凍住,也要考量在冷凍以及化凍時不會對人體產生傷害。像奧茲冰人那樣凍成一具乾屍,肯定是不行的。
不過經由前面小象由香和奧茲冰人的故事,我們已經了解,在生物體死後及時讓其進入低溫環境,可以很大程度上延緩甚至叫停讓屍體腐爛。同樣,人死後越快進入冷凍,細胞和身體受到的影響就越小。當然,只要提前簽好協議、做好準備、安排好一切事宜,及時進入冷凍狀態並不是什麼困難的事情。
要怎麼把活人冰起來?
常煮飯的廚藝愛好者都應該知道,一塊鮮肉,在經過冷凍再化凍後,往往會滲出大量的血水。這是因為在冷凍時,細胞中的水分會結冰,而這些冰晶會破壞細胞結構,從而造成細胞的死亡。凍肉化凍時滲出的血水,很大一部分就來自這些破損的細胞。這顯然是我們在以喚醒為目的的人體冷凍中不願意看到的結果。
因此,在對人體進行冷凍之前,需要經由手術和灌注,將人體中的血液替換為冷凍保護劑。冷凍保護劑可以降低冰點,減少冰晶的產生,最大限度地避免對身體細胞組織造成破壞。然後,人體才會進入降溫程式。經過 60 小時的降溫後,冷凍的屍體就可以被轉移到巨大的液氮罐中長期保存了。
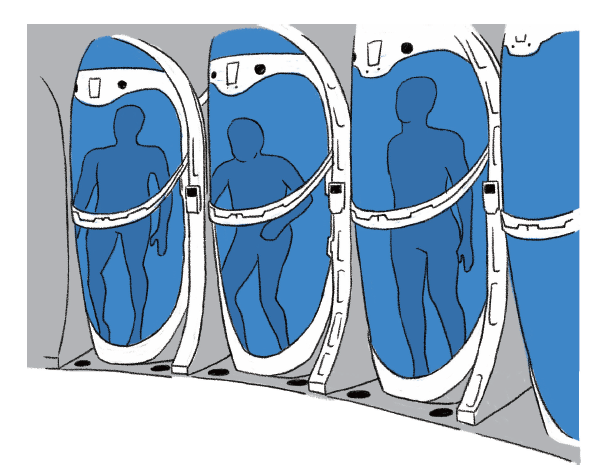
如今世界上冷凍人的數量已經接近 500 人,但能夠獨立實施人體冷凍的機構只有 4 家,分別是美國的阿爾科生命延續基金(Alcor Life Extension Foundation)及人體冷凍研究所(Cryonics Institute)、俄羅斯的 KrioRus 和中國的山東豐銀生命科學研究院。其中人體冷凍研究所是由「人體冷凍之父」艾丁格博士創立,而阿爾科生命延續基金會中保存著全世界第一個被冷凍保存的人詹姆斯.貝德福(James Bedford)的身體。
按照計畫,貝德福本應該在進入冷凍狀態 50 年後,也就是 2017 年被喚醒,但阿爾科生命延續基金會至今並未行動。
一方面,我們可能仍未對喚醒冷凍人在技術上做好準備;另一方面,據傳聞,貝德福當年所使用的冷凍保護劑似乎對人體傷害甚大,也就是說,就算技術完備,貝德福是否能夠醒來也十分不好說。
人體冷凍很貴嗎?
進行人體冷凍的費用倒是並沒有想像中那麼高昂,以這幾家機構中收費最高的阿爾科生命延續基金會在 2017 年的報價為例,進行全身冷凍的費用約為 20 萬美元,還有一個更便宜並且更具有科幻意味的選擇——單獨冷凍頭部,僅需 8 萬美元。不過,在現有的技術手段之下,選擇人體冷凍,比起「追求永生」和「無限可能」,更像是在參與一場結果未知的科學實驗。
當然,技術仍然不斷進步,關於人體冷凍的最新進展似乎為貝德福以及其他被凝固在液氮罐中的人們帶來了一些希望:據報導,2020 年 12 月,一個在液氮罐中沉眠了 27 年的胚胎被取出植入一位母體的子宮,並分娩出一名健康的女嬰。
如果有一天,我們真的像艾丁格博士所說的那樣,打破生與死的邊界,獲得「永生」之時,生命是否也就失去了很多意義?

——本文摘自《真的假的!奇怪知識又增加了:自說自話的總裁顛覆認知的科學奇想》,2023 年 7 月,晴好出版,未經同意請勿轉載。





































{kind=link}