

- 作者/賴宜欣,台北大學法律系法學組學士,政治大學法律學系碩士,日本國立名古屋大學特別研究生,現為執業律師。
編按:在出現Deepfake之後,網路世界進入了「眼見不為憑」的年代。
本次泛科學和法律白話文合作策畫「Deepfake 專題」,從Deepfake 技術與辨偽技術、到法律如何因應。科技在走,社會和法律該如何跟上、甚至超前部署呢?一起來全方位解析 Deepfake 吧!
網紅小玉的「換臉私密影片」犯罪事件,讓深度造假(DeepFake)技術一夕之間成為台灣廣為人知的的技術。而此次風波,更讓社會大眾注意 AI 技術被濫用的嚴重性,呼請修法的聲浪不斷,希望政府能盡速遏止科技犯罪,不要再有下一個受害者。本文則介紹韓國、日本、歐盟各國的相關管制,擬以他山之石,一窺未來台灣可能的相關管制之道。

韓國:以 N 號房事件為鑑,修訂「性暴力犯罪法」
2019 年底,韓國爆發「N 號房事件」──受害規模之大不但震驚了整個韓國社會,也引發國際矚目。
「N 號房」營運的方式,是隨著付費等級提高,就能進入內容更加腥羶的色情房(總會員人數據傳高達 27 萬人);而在那些色情房中,也包含了以深度造假合成的不雅影像及照片為主題的群組。由於付費會員中不乏高社經地位人士,受害者眾多,也讓韓國的社會大眾意識到「數位性犯罪」的嚴重性。
當時韓國法規對數位性犯罪的規範相當不足 ,如同韓國的網路新聞所報導的,面對「換臉加散布」這樣的情況,只能用如《刑法》「提供猥褻物品(包含文書、圖畫或其他物品)罪」或《情報通信網法》中的「透過情報通信網對公眾散布、販賣、提供猥褻影像罪」來處罰,並以毀損名譽及侵害肖像權為由「請求損害賠償」。因此即使是如此眾所矚目的嚴重案件,在法律上實際要進行處罰,最重也不過是 1 年的有期徒刑及 1000 萬韓元(約台幣 25 萬元)的罰金,可說是相當輕微註一。

此外,法律專家們也指出另一個大漏洞──當時的法律並沒有依據能針對「使用深度造假製作虛偽影像的行為本身」施加處罰。也就是說,製作影片本身在當時並不違法,法律必須要等到行為人散布虛偽合成影像、讓影片接觸社會大眾,才能夠啟動處罰。
鑒於利用 AI 技術、合成虛偽影像對受害人已經是一大傷害;而至散佈虛偽影像對受害人來說(特別是被運用在成人情色片等猥褻物品方面),則應被視為極大的二度傷害。根據韓國法律新聞指出,2019 年統計受到「深度造假」換臉程式合成的被害人,高達 96% 是女性,其中 25% 是韓國的女性演藝人員。因此,韓國法界多半認為應直接針對活用深度造假虛偽影像的行為,量身打造可以直接適用的法律;也讓該國開始修定《性暴力犯罪之處罰等相關特例法》(下稱「性暴力犯罪法」)。
修法直接處罰「製作、散布及利用虛偽影像營利的行為」
就在前述的修法呼聲中,2021 年 1 月 21 日,韓國修正施行了《性暴力犯罪法》相關規定,明文禁止利用深度造假製作虛偽影像等數位性暴力行為。
首先,該法會處罰「製作虛偽影像的人」,只要「抱著散布目的」,在「違反當事人的意思」的前提下,利用「他人面孔、身體或聲音製作攝影、影像、聲音等物」,進行「誘發性慾望和性羞恥心」的「編輯、合成、加工等行為」,就會受到 5 年以下有期徒刑和 5000 萬韓元(約台幣 125 萬元)以下罰金的處罰。

其次, 修正後的《性暴力犯罪法》 也會處罰「散布虛偽影像的人」。換句話說,只要將上述「經過編輯合成加工的虛偽影像(包含影像的複製物)」散布出去;且即使在「編輯當時」沒有違反當事人的意願,但事後散布這些虛偽影像時,已經違反當事人意願的話,也是違法的。針對散布的行為,將處以 5 年以下有期徒刑和 5000 萬韓元以下罰金。
接著,如果是「違反當事人意願,利用情報通信網散布虛偽影像來營利」的行為,更會處以 7 年以下有期徒刑。更嚴重的,如果「製作、散布、營利」三種行為全包了,則會加重總合刑度的 2 分之 1。並且,以上這些行為,全部都有處罰未遂犯。
另外,韓國更進一步把利用影片進行「強暴、脅迫及行無義務之事」的行為也列入處罰。像是「利用能夠誘發性慾望和性羞恥心的攝影物和複製物來進行脅迫」,處 1 年以下有期徒刑;又或是利用前述影片「脅迫妨害他人行使權利或使其行無義務之事」者,則處 3 年以下有期徒刑。而若有人統包這兩種行為的話,更會加重總合刑度的 2 分之 1。
修法之後仍未懲罰虛偽影像的「消費者」?
但是,即使制定了專門的處罰法規,還是有不足的地方。比方說,該法並未處罰「購買、消費深度造假影像的視聽者」。律師解釋,修改後的法規只處罰「製作、散布虛偽影像者」一方,並未針對「購買、消費虛偽影像」的另一方,設下處罰規範,也就難以針對「購買、消費虛偽影像的視聽者」予以管制註二。
那麼,對於購買深度造假虛偽影像的人,真的沒辦法處罰嗎?律師表示,《性暴力犯罪法》還是會針對「單純持有影像者」,處以 3 年以下有期徒刑及 3000 萬韓元(約 75 萬台幣)以下罰金──不過,本條的處罰前提是:必須證明行為人「把虛偽影像當成真實影像」購買保存,才可以認定為不法持有影像的行為而加以處罰。
但這樣的證明方式過於迂迴,因此韓該國法界多認為,應正視購買視聽對受害人帶來的莫大創傷,未來應明文處罰「購買及消費影像」之人,才能予以平衡。

日本及歐盟:以「AI 倫理規範」防治不當使用
相對於韓國制定專法來防治數位性暴力,日本及歐盟則是建立「AI 利用倫理規範」,在利用 AI 的前階段,對未來的使用方式進行分類,賦予不同程度的行為義務。
2021 年 4 月 21 日,歐盟發表了《人工智慧統一管理規則的立法草案》(Proposal for a Regulation on a European approach for Artificial Intelligence)簡稱「人工智慧法」,依照危險性的高低及重要程度,將利用 AI 的行為分成 4 個類型——「不可接受的風險、高度風險、具限定性風險(有限風險)、極小/無風險」,並要求採取「禁止使用、提供情報、使用情況(如登入)之紀錄、協助主管機關監視 AI、由 AI 進行動作之通知義務、警告標示」等相對應義務。
其中,如同日本學者川嶋雄作專欄文章所討論的,「使用深度造假操作技術,形成畫面、聲音、動畫」等利用行為,是被分類在「具有限定性的危險」。依據該法案,使用深度造假技術做出虛偽影像者,具有通知義務、需附加警告標語,必須告知觀眾這是使用 AI 技術所形成的影像註三。
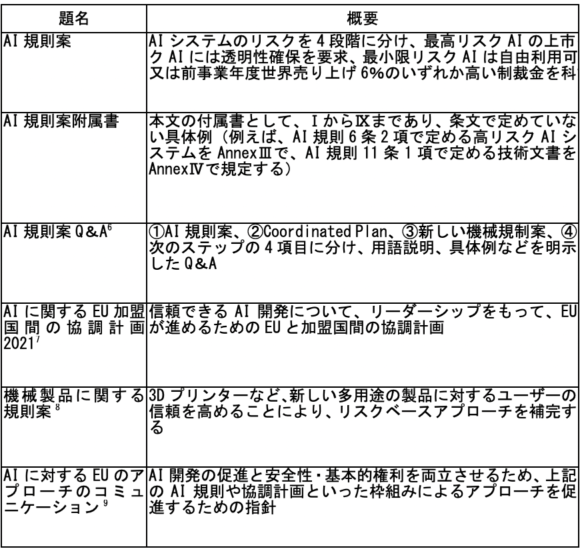
根據日本律師相關的分析內容,日本也採取了和歐盟相同的路線,不走法制化的路線,而著重推廣 AI 倫理 ,由政府部門和國際性企業為首,定期召開會議來檢討國內利用 AI 的情況。
像是日本學界就成立了「人工智慧學會」、內閣府(相當於我國的行政院)也召集了「人工智慧和人類社會之懇談會」、「AI 網絡社會促進會議」等組織,提出人工智慧倫理指南;該指南指出:不能透過人工智慧,直接或間接造成他人情報或財產侵害(安全原則),需尊重他人隱私,並落實誠實義務(透明化原則),並確保不得惡意使用之社會責任(適切原則)。而包括 SONY、日立等日系大廠,也都制定了自家的 AI 守則,來因應國際發展。
總的來說,日本與歐盟沒有立法,主要是針對 AI 的潛在危險性進行分類,並賦予相對的使用義務規範。不過,這樣的方式多少會限定特定 AI 的使用方式,因此是否有必要明文賦予拘束力,目前在歐洲委員會仍在檢討,各國仍尚未定案。而日本目前則是以公部門和企業為首,在配合國際趨勢下進行自主規範,並沒有打算進一步做出強制性的立法 。
相較於韓國因發生嚴重案件而具體修正《性暴力犯罪法》,以遏止類似惡性事件再度發生;歐盟與日本目前仍採取倫理推廣的路線,透過針對 AI 技術的研發起源進行規範。孰優孰劣、未來又將如何發展?恐怕只有時間才能告訴我們了。

註解
- 註一:韓國律師所舉出 2019 年當時可能用來處罰 DeepFake濫用的三個法規:首先是刑法第 244 條「提供猥褻物品(包含文書、圖畫或其他物品)罪」,可處罰 1 年以下有期徒刑和 500 萬韓元(約台幣 12.5 萬元)以下罰金。第二,依「情報通信網利用促進及情報保護等相關法律(情報通信網法)」第 44 條之 7,在「使公共得以接觸下,透過情報通信網散布、販賣、提供猥褻之符號、文件、聲音、畫像和影像等」,處 1 年以下有期徒刑和 1000 萬韓元(約台幣 25 萬元)以下罰金。最後是「名譽毀損」相關法規,對合成並提出猥褻物品者主張名譽毀損,及主張肖像權受侵害,提出損害賠償。
- 註二:本標題段落參自:딥페이크 처벌법’ 신설하긴 했지만, ‘반쪽’ 짜리 법안입니다 。
- 註三:體系圖參照「報道から見る欧州AI規則案の日本での受容と影響」,其中的圖 1:AI 規則案の全体像 。
參考資料
- 취향대로 골라보세요?” 한국 아이돌로 장사하는 딥페이크 포르노 ,2019年10月18日。
- 韓國《性暴力犯罪之處罰等相關特例法》。
- 딥페이크 처벌법’ 신설하긴 했지만, ‘반쪽’ 짜리 법안입니다 ,2021年1月14日
- 川嶋 雄作,AI規制は時期尚早か?「EUによる規制法案から考えるAI倫理」 , 独立行政法人経済産業研究所。
- InFoCom T&S World Trend Report,情報通信総合研究所主任研究員 栗原佑介,2021.5.31,「報道から見る欧州AI規則案の日本での受容と影響」。
- BUSINESS LAWYERS,注目度が高まるAI倫理と個人情報保護の関係 – カメラ画像の利活用を題材に – 。
- 經濟產業省,「我が国の AI ガバナンスの在り方 ver. 1.0 AI 社会実装アーキテクチャー検討会 中間報告書 」,令和3年1月 15 日 ,頁12。
- 網路安全所助理研究員 吳宗翰,「歐盟公布草案禁止 AI 用於社會評等」,國防安全雙周報。



































