
- 文/廖英凱|非典型的不務正業者、興致使然地從事科普工作、科學教育與科技政策研究。對資訊與真相有詭異的渴望與執著,夢想能做出鋼鐵人或心理史學。
Take Home Message
- AI 雖然能協助遏止違法或侵權的言論,但一般大眾卻無法得知其評斷的機制,已於無形中造成傷害。
- AI 的資料庫誤差,將造成演算法對文化或族群產生偏見等;而深度學習的演算法因處理龐大的資料,常使研究者或運用 AI 的機構無法理解與回溯 AI 的決策原因。
- 歐盟、美國、聯合國等組織已相繼研擬 AI 的規範與監管方式。
- 臺灣仍須再制定 AI 相關的監管辦法,以因應科技的發展及變遷。
「你今天被祖了嗎?」
眾所皆知目前社群網路最大的平台臉書(Facebook),為遏阻違法或侵權的言論,會判定某些言論違反其「社群守則」而隱藏。不可否認,違法與侵權言論在社群網路上造成了嚴重的傷害,不過有時候這些隱文的原則,似乎與政治或特定議題有關。時不時也有朋友提到,一則再平凡不過的貼文或照片,卻莫名其妙地被宣告違反社群守則。於是乎在去(2021)年時,網友們開始把臉書創辦人祖克柏(Mark Zuckerber)的姓氏,變成了諷刺臉書封鎖文章標準混亂的話梗:你被「祖」了嗎?
想當然爾如臉書等社群媒體,是仰賴著演算法自動判斷一則貼文是否違規。除了針對文字與圖片的內容分析以外,其他例如被檢舉的數量、帳號的活躍程度、帳號的發文模式、商業價值等,都成為演算法評估一則貼文是否違規的依據,彷彿法官在定罪犯人時不只依據犯罪行為,也會權衡犯人及其社會狀態一樣。然而,我們看得到法官的決策過程與理由,但卻從來沒有機會搞清楚,到底演算法發生了什麼事情,才會宣告一則平凡的貼文違規。
雖然大家平常遇到這種貼文被刪的情況,通常也就是重新打篇文章貼個圖發發牢騷,就這麼過去了。但這個時不時可見的神祕隱文事件,其實就是我們生活中,人工智慧(artificial intelligence, AI)已經持續帶來隱性傷害的頻繁案例。
AI 的傷害跟以往想像的不一樣
自工業革命以降,人類其實蠻迅速地就提出對科技發展副作用的深層反思。例如人類史上第一部科幻作品,1818 年由英國作家雪萊(Mary Shelley)所著作的《科學怪人》(Frankenstein),即是以一個具有擬人思維的人造生命為主角的科幻驚悚作品。伴隨著機器的發展,1956 年達特矛斯會議(Dartmouth Summer Research Project on Artificial Intelligence)上,與會專家提出「artificial intelligence」一詞,認為機器的發展將可像人一般具有學習、理解、適應的能力。
隨著 AI 技術上的演進,人們對 AI 的樂觀與悲觀態度,也愈發分歧。對於 AI 發展所帶來社會的影響,依其態度可以分為:對科技抱持樂觀者,相信「強 AI」的問世可以使電腦與人有相同甚至超越人類的思考能力,並為人類解決大部分問題,帶來更理想的明天,在電影動畫等作品中不乏這類理想的人工智慧角色;重視科技實用者,傾向認為 AI 是以輔助人類的角色,解放人類的勞力工作而能開創更多科技應用的可能;重視科技發展脈絡者,則認為 AI 只是科技發展中的一個流行詞(buzzword),只有尚在發展中,尚未充分掌握的技術才會被視為 AI。與科技領域相對,在人文社會領域中則較常出現對 AI 發展的反思,例如研究 AI 對人類勞力取代後所創造的弱勢衝擊;或更甚者認為強 AI 的不受控發展,將會導致人類文明的毀滅。這些不同立場的觀點,均揭示了人類看待 AI 對社會影響的多元與矛盾預測。
儘管當代影視作品和學術研究,都對 AI 會造成什麼樣的傷害有興趣,但 AI 帶來的傷害早已出現多年而默默影響著人類社會。2018 年在《自然》(Nature)期刊上的一則評論,介紹了一張身披白紗的歐美傳統新娘和印度傳統新娘的組圖,而演算法在看待兩張新娘照片時,會將前者判斷為「新娘」、「洋裝」、「女人」、「婚禮」等,但將後者判斷為「表演」和「戲服」。在這個案例中,AI 或演算法設計本身其實並沒有獨鍾哪一種文化,但因為演算法的訓練來自於既有圖庫,而圖庫中的圖片來源和圖片的詮釋註記,與真實世界的樣貌出現落差,使人工智慧就如真人一般,憑藉著片面不完整的學習資料,產生了對族群與文化的偏見(偏誤),而演算法可能更無法自覺與反思自我產生的偏見(圖一)。

除了資料庫的誤差而導致演算法對文化或族群的偏見以外,「深度學習」(deep learning)的演算法因處理龐大的訓練資料、分析資料,也常使研究者或使用 AI 服務的機構,無法理解與回溯 AI 決策的具體原因。例如亞馬遜公司(Amazon.com, Inc.)仰賴演算法全自動判斷大量受僱員工的工作狀態,並以此決定他們的績效與裁員與否。儘管這種做法能大幅縮減決策時間,並減少人資成本,但也因此發生數起亞馬遜員工因系統過失而被降低績效,或是員工績效良好卻被無故裁員,更申訴無門的矛盾事件。這與將 AI 應用於人資的初衷似乎有點相悖,演算法或許可以避免人為決策時,因涉及個人喜惡偏好而作出不公允的判斷,但卻也造成了另一種不公允也無從理解緣由的傷害。
誰來規範 AI?
既然 AI 的傷害已然出現,自然也應有對 AI 的監管與規範機制。例如歐盟執委會(European Commission)在 2019 年 4 月公布「值得信賴的人工智慧倫理指引」(Ethics Guidelines For Trustworthy AI),強調人工智慧應為輔助角色,尊重人類自主、避免傷害、維護公平、具有可解釋性,且能受到監管並回溯決策過程,以避免演算法的黑箱決策,作為歐盟成員國在訂定 AI 相關規範的上位依據。2019 年 5 月,經濟合作暨發展組織(Organisation for Economic Cooperation and Development, OECD),提出 AI 發展的原則應有永續精神以造福人類與地球,能尊重民主與法治、人權與多元性,兼顧透明度、課責機制等原則。美國白宮科技辦公室在 2020 年 1 月發布的「人工智慧應用的管制指引」(Guidance for Regulation of Artificial Intelligence Application),也強調衡量風險避免傷害、公平無歧視、透明度、重視科學實證、立法過程應兼顧公共參與等,作為美國政府各機關在訂定與人工智慧相關規範的指導原則。聯合國教科文組織(United Nations Educational Scientific and Cultural Organization, UNESCO)則在去年 11 月,發布《人工智慧倫理建議書》草案(Draft text of the recommendation on the ethics of artificial intelligence),作為會員國訂定 AI 相關法律與政策時,可依循的通用價值觀、原則和行動框架。
國際上重要的原則指引,也同等地體現在民意對 AI 治理的期待,臺灣師範大學教授李思賢、劉湘瑤、張瓅勻等人針對臺灣 1200 位民眾的調查發現,臺灣民眾對 AI 的應用最在意的是避免傷害,其次則是透明度與公平性,相對最不在意的是隱私。調查亦發現民眾明確偏好以公民審議和立法機關來制定嚴格傾向的規範,這反映了民眾對新興科技的擔憂與對透明治理的期待,也呼應了國際組織的指引方向(圖二)。
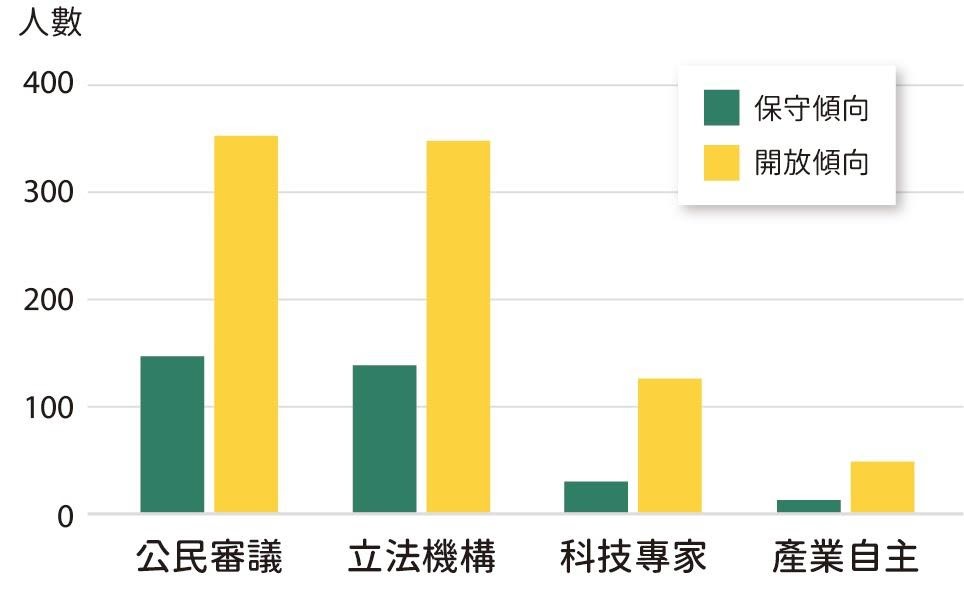
然而,國際上的重要指引與民調結果,卻也讓我國在相關規範的設計上略顯矛盾。例如調查研究顯示,雖然民眾最期待以「公民審議」和「立法機構」來訂定 AI 相關規範,但現今國內外相關規範的研擬與討論,仍是以由產官學組成的研究與應用社群為主,例如科技部自 2017 年起,開展多場 AI 倫理議題的研究計畫與論壇工作坊等,並於 2019 年 9 月提出《人工智慧科研發展指引》,明訂 AI 科研的核心價值與指引,使科研人員在學術自由與創新發展的同時,也能兼顧 AI 發展的方向。
但科技部並非產業的主責機關,所訂定的指引僅能提供科研人員更好的方向,對已產生傷害的業界應用仍然鞭長莫及。儘管 2018 年 11 月立法院曾通過初具 AI 倫理精神的《無人載具創新實驗條例》;2019 年 5 月,時任立法委員許毓仁等人也提出《人工智慧發展基本法》修法草案,作為政府兼顧人工智慧產業發展和倫理規範的法律基礎,但該草案的相關修法討論並未被積極延續,作為國家更上位看待 AI 發展的治理框架,於立法體制和公民審議機制中均尚未開展高強度的討論。
AI 對今日生活的便利已無遠弗屆,而 AI 所帶來的傷害,雖微小、難以察覺,但也已經出現,對應的倫理指引與規範在國際也蔚成趨勢,但臺灣仍在牛步,或許國家在看待 AI 發展時,必須開始將這些規範視為迫切的基礎建設。
如同歷史上所有科技進展一般,科技帶來的進步與災變往往是隱性與持續的,直到人們已慣於新興科技的進步,發現科技的受害者已經出現,才驚覺世界已經完全改觀。
延伸閱讀
- James Zou and Londa Schiebinger, AI can be sexist and racist — it’s time to make it fair, Nature, Vol.559, 324-326, 2018.
- 人工智慧之相關法規國際發展趨勢與因應,https://www.ndc.gov.tw/nc_1871_31998。
- 《人工智慧發展基本法》草案,https://pse.is/3w9rrf。

- 〈本文選自《科學月刊》2022 年 1 月號〉
- 科學月刊/在一個資訊不值錢的時代中,試圖緊握那知識餘溫外,也不忘科學事實和自由價值至上的科普雜誌。







































