
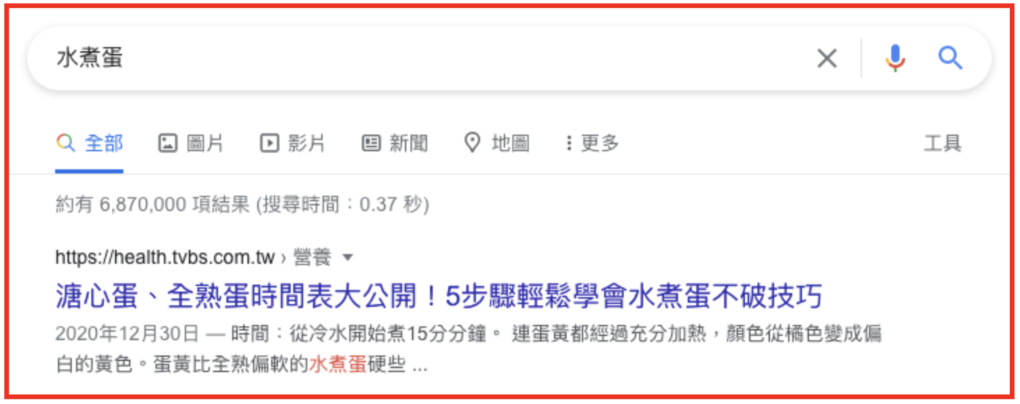
打開 Google 輸入「水煮蛋」,Google 會知道,你是想了解「水煮蛋的煮法」,並且快速地給出你想要的答案。
或是只輸入「麵包店」,Google 就會自動推測,你是想找附近的麵包店。因此會依照你的網路所在位置,優先提供附近麵包店的資訊。
能有以上更方便的搜尋方式,和更能滿足使用者需求的搜尋結果,都是蜂鳥演算法加強「語意判讀」和更理解「搜尋意圖」的功勞。
搜尋引擎的基本原理,分別是爬文(Crawling)、收錄 (Indexing)和排名(Ranking)三步驟。首先必須透過爬文蒐集資料,再把這些資料收編和儲存進 Google 的資料庫,最後則是網站經營者或 SEO 專家最關心的排名步驟──也就是 Google 如何決定哪些資料要優先推薦給使用者。
而演算法就像是為上述整個過程套上一個公式,不同公式能導出不同計算過程和結果,連帶影響 Google 給出的搜尋結果,比如「咖啡因演算法」改變了網頁收錄的方式,「熊貓演算法」則大大提升網頁內容品質。那,蜂鳥演算法帶來哪些影響呢?
蜂鳥演算法:讓「搜尋意圖」判斷更進化
蜂鳥演算法(Google Hummingbird)是Google 演算法歷屆演變中,相當重要的變革之一,因為它並非只針對舊有的演算法做出些微調整,而是一口氣替換掉演算法的核心,不過也同時保留了部分舊有演算法的元素。
在蜂鳥演算法出現以前,Google 本來只會從搜尋字串中抓出幾個關鍵字,判斷各個字詞字面上的意思,再從資料庫中找出有關鍵字詞的資料。例如:使用者搜尋「水煮蛋 時間」,Google 可能會從資料庫中撈出同時有提到「水煮蛋」和「烹調時間」的網頁,再排序推薦給使用者。
反過來說,如果使用者想知道水煮蛋需要煮多久才會熟,直接搜尋「水煮蛋需要煮多久才會熟」如此直白語句,未必找得到答案,因此使用者可能必須將問題先切成幾個關鍵字,轉換成 Google 看得懂的語言,如「水煮蛋 時間」,或是推測可能要看水煮蛋食譜才能解決問題,而改搜尋「水煮蛋 食譜」或「水煮蛋 步驟」。
簡單來說,使用者會需要配合搜尋引擎能理解的語言來提問,才能找到需要的資訊。但如果搜尋前,還得先思考要打什麼關鍵字才能找到答案,豈不是很麻煩嗎?
Google 搜尋引擎秉持的理念是,要提供最相關的資訊給使用者,且讓使用者花越少時間在搜尋越好。換句話說,就是要讓使用者在最短的時間內獲得想要的資訊──「速度」跟「精確度」是兩大重點,而蜂鳥演算法的出現大大改善了這兩個問題。
蜂鳥雖然體型嬌小,卻以翅膀振動速度飛快和敏捷行動力出名,而蜂鳥演算法正如其名,希望帶給使用者的搜尋體驗能是快而精準。
但要如何做到?最重要的關鍵是,要能更了解使用者想要找什麼樣的資訊、使用者為什麼要搜尋該關鍵字,也就是要判讀所謂使用者的「搜尋意圖」。
搜尋意圖(Search Intent)是什麼?
簡單來說,搜尋意圖就是使用者搜尋的「目的」,可以是想知道關鍵字是什麼意思、想要購買商品、想找到某個網站等。蜂鳥演算法正式運行以後,我們已能更準確地從搜尋結果頁面,來推測使用者的搜尋意圖。
舉例來說,搜尋關鍵字「演算法」,搜尋結果第一頁會出現有關演算法的介紹,因此可以推測使用者,使用者搜尋「演算法」,應該就是想了解演算法是什麼。

再看一下關鍵字「水煮蛋」,搜尋結果第一頁上的內容大多是在介紹「水煮蛋的煮法」,諸如水煮蛋要煮多久等等,而非水煮蛋的營養成分等知識性內容。也就是說,Google 猜測,查詢「水煮蛋」的使用者,最想知道的是「水煮蛋怎麼煮」,而不是有關水煮蛋的知識。

判斷搜尋意圖未必是件容易的事,但對執行搜尋引擎優化(SEO)來說卻很重要。因為 Google 會提供給使用者的是和搜尋意圖最相關的資訊,因此正確掌握搜尋意圖,正是做好 SEO 的第一步。
以水煮蛋為例,如果你經營的網站,寫了一篇水煮蛋「營養成分的介紹文章」。但因為搜尋「水煮蛋」的使用者,比較想了解的是水煮蛋的「製作方式」,所以 Google 很可能不會把你的文章排得太前面。
蜂鳥演算法如何幫助 Google 更精確地判斷搜尋意圖?
在蜂鳥演算法推出前,Google 先推出了語音搜尋的服務,用口語表達的方式即可以執行搜尋。比起文字輸入搜尋,語音搜尋的用語更為自然、口語化,比如以文字搜尋時,使用者可能會輸入「水煮蛋製作」,但使用語音搜尋時,卻可能會說出較為口語的「水煮蛋怎麼做」。
此時,如何解讀使用者的搜尋字詞變得相當重要,而蜂鳥演算法帶來最大的改變是從字詞上的辨識,進階成為「語意上的解讀」。
也就是說,Google 本來只會根據關鍵字提供對應的資料給使用者,但蜂鳥演算法的導入,卻讓 Google 開始學會讀取上下文。能將所有輸入的字詞融為整體作判斷,並參照彼此間的關聯性去推測更深層的意涵,而非單單只是把搜尋字詞看成是有很多關鍵字集合的字串。
比如搜尋關鍵字「明天天氣」,若只抓取字面上的關鍵字,搜尋引擎可能只會判斷使用者想知道天氣,所以會提供各縣市天氣預報。但是加入語意上的判讀後,Google 會將「明天天氣」此搜尋字詞理解為「使用者想知道所在區域的明天天氣狀況」,便會在使用者有授權的情況下,自動參考使用者的位置資訊,進而提供使用者所在位置的天氣資訊。

蜂鳥演算法對搜尋引擎優化(SEO)的影響?
如果蜂鳥演算法只是強化了Google 對於搜尋字詞的理解能力,那麼對於網頁在搜尋結果的排名,理論上來說應該沒有直接影響?
但實際上,蜂鳥演算法雖然沒有改變影響排名的因素,但對於網站流量的成效和 SEO 執行策略方面卻有帶來一些改變。
1.流量可能變少
在蜂鳥演算法導入的前一年,Google 推出了「知識圖譜」(knowledge graph)功能。它結合了語意分析和資料蒐集,事先彙整了一些使用者可能需要資料,只要使用者一搜尋相關關鍵字,Google 就能從資料庫中提取資料,提供現成的知識圖譜,讓使用者的疑問能快速被回答。使用者甚至不需要點入任何搜尋結果就能得到答案,例如搜尋「強尼戴普幾歲」:

從搜尋結果最上方及右側的知識面板,就能立即得到強尼戴普的年齡和其他相關資訊,甚至不需要點入維基百科查看。
這對於使用者來說當然是好事,畢竟搜尋問題能立刻得到答案,還不需要自己一一點入網站彙整需要的資訊。相反的,對於網站主來說,語意理解加知識圖譜的出現卻會是個威脅,因為辛苦策劃了網頁內容,卻可能吸引不到點擊/流量。這時候的網頁排名競爭,相當於要競爭的對手不只是其他網站,還有 Google 本身。
2.長尾關鍵字更受歡迎
因為語音搜尋服務的推出,使用者的搜尋字詞開始越來越口語化,而這些口語化的搜尋字詞,是屬於搜尋量較少、非主要搜尋字詞的長尾關鍵字。本來在蜂鳥演算法推出以前,Google 比較不擅長將這類長尾關鍵字和相對應的網頁內容串連在一起,SEO 操作上較少選擇長尾關鍵字作為要操作的目標關鍵字。在蜂鳥演算法導入之後,Google 的關鍵字語意判讀能力提升,才能逐漸辨識這些長尾關鍵字的搜尋意圖。
SEO 策略能如何因應蜂鳥演算法調整?
延續前一段提到蜂鳥演算法對 SEO 的影響,可以了解蜂鳥演算法與網頁排名指標較沒直接關係,網站主沒辦法針對特定因素進行優化,因此只能將重心放在優化網頁內容,增加搜尋引擎將網站推薦給使用者的機會。
1.多發布優質內容
針對網站主題多發布相關的原創內容,網站內容越豐富,越有機會解答使用者的問題。
2.加強文章的廣度
文章內容題材涵蓋範圍越廣,越能解決使用者可能會有的疑問。能一文解決使用者所有疑問的文章,有較高的機會被Google 認定為優質內容,進而推薦給使用者,而使用者也可能透過搜尋不同疑問接觸到同一篇文章。
3.善用長尾關鍵字
上段有提到蜂鳥演算法讓長尾關鍵字越來越受歡迎,代表使用者會更容易透過搜尋長尾關鍵字而接觸到相關網頁。網站主可以善用蜂鳥演算法能理解長尾關鍵字語意的特性,挑選適合的長尾關鍵字作為 SEO 的操作目標,或許反而能因為長尾關鍵字競爭程度相對小、搜尋意圖相對明確的優勢,讓網頁更有機會獲得好排名。
以上三個策略,都是著重在「如何用內容增加網頁曝光」的機會,所以最後還是老話一句,當你不曉得 Google 演算法革新帶來什麼影響、不知道該如何因應改變時,只要記住:持續提供優質內容、解決越多使用者的問題,就是做好 SEO 的最高原則。
蜂鳥演算法對搜尋引擎使用者的影響
蜂鳥演算法是 Google 用來判斷搜尋意圖的一大利器,透過精準掌握搜尋意圖,達到能快速提供使用者有用資訊的效果。Google 對關鍵字的理解,從初階的「詞彙」辨識,進階到「語意」上的解讀。因此,Google 更加清楚理解,使用者對搜尋引擎提出的問題,究竟是在問什麼,以及使用者預期想得到的答案又是什麼。
Google 彷彿真的知道,在電腦前輸入關鍵字的你我在想些什麼。例如正想自製早午餐的你,搜尋「法式吐司」,Google 會馬上告訴你,做出好吃法式吐司的方法。搜尋「最佳燒烤店」,Google 會找出離你最近的高評價燒烤店資訊(而不是依照「最佳燒烤店」字面上的意思,列出全世界最高分的燒烤店)。
藉由蜂鳥演算法的幫助,Google 大神不只有問必答,提供的答案也一點都不馬虎,能確實幫助使用者解決問題。
從蜂鳥演算法對使用者的影響來看,基本上是有益無害。蜂鳥演算法能將多樣化的使用者問題和網頁提供的資訊,更精準地連接在一起。並加入知識圖譜、本地資訊等貼心服務,優化使用者體驗。不僅可以讓使用者使用更人性化的用詞搜尋,得到的搜尋結果往往也更符合所需。
不過,蜂鳥演算法在語意判讀的精準度能否更提升,精準度是否會因不同語言而有差異?仍是值得持續觀察的問題。
參考資料:
- Google Hummingbird – Moz
- Searcher Intent: The Overlooked ‘Ranking Factor’ You Should Be Optimizing For – Ahrefs
- SEO 搜尋引擎優化 – JKL SEO
- 搜尋引擎原理 – JKL SEO
- Should You Change Your SEO Strategy Because of Google Hummingbird? – Neilpatel
- 什麼是長尾關鍵字?流量不是最多但非常重要的 SEO 觀念! – dcplus




































