你知道為什麼 Microsoft Windows 的選單列放置在視窗上,而 Apple Mac OS X 的選單列放在螢幕的最上方嗎?你知道為什麼 Mozilla Firefox 瀏覽器左上角的「回到上一頁」和「到下一頁」兩個按鈕的大小不一樣嗎?其實費茲定律(Fitts’ Law)都已經在許多使用者介面裡面偷偷運作了!
費茲定律(Fitts’ Law)是心理學家 Paul Fitts 所提出的人機介面設計法則,主要定義了游標移動到目標之間的距離、目標物的大小和所花費的時間之間的關係。費茲定律目前廣泛應用在許多使用者介面設計上,以提高介面的使用性、操作度和效能。費茲定律長得就像下面這個公式:
其中 T 代表所花費的時間,a 是系統一定會花費的時間,b 是系統速率,D 代表啟始點到目標之間的距離,而 W 則是目標物平行於運動軌跡的長度。看起來一點都不討喜,對吧?我們可以用下圖來簡化一下費茲定律的意思:
至於 Windows 和 Mac OS X 的選單位置的差別呢?Windows 將選單位置放置在視窗標題的下方,如果滑鼠要從視窗內移動到選單上,這個選單的上下間距是非常狹窄,所以比較不容易點選到正確的按鈕。而 Mac OS X 則將選單放到螢幕的正上方,由於滑鼠移動到螢幕邊界的時候,會被螢幕邊界限制而停下,因此可以將選單的高度(也就是費茲法則中的 W)視為無限大,所以使用者所花費的時間減少,效率也就提昇了。
Cowan, B. R., Branigan, H. P., Obregón, M., Bugis, E., & Beale, R. (2015). Voice anthropomorphism, interlocutor modeling and alignment effects on syntactic choices in human-computer dialogue. International Journal of Human-Computer Studies, 83, 27-42.
Branigan, H. P., Pickering, M. J., Pearson, J., McLean, J. F., & Brown, A. (2011). The role of beliefs in lexical alignment: Evidence from dialogs with humans and computers. Cognition, 121(1), 41-57.


 你知道為什麼 Microsoft Windows 的選單列放置在視窗上,而 Apple Mac OS X 的選單列放在螢幕的最上方嗎?你知道為什麼 Mozilla Firefox 瀏覽器左上角的「回到上一頁」和「到下一頁」兩個按鈕的大小不一樣嗎?其實費茲定律(Fitts’ Law)都已經在許多使用者介面裡面偷偷運作了!
你知道為什麼 Microsoft Windows 的選單列放置在視窗上,而 Apple Mac OS X 的選單列放在螢幕的最上方嗎?你知道為什麼 Mozilla Firefox 瀏覽器左上角的「回到上一頁」和「到下一頁」兩個按鈕的大小不一樣嗎?其實費茲定律(Fitts’ Law)都已經在許多使用者介面裡面偷偷運作了! 其中 T 代表所花費的時間,a 是系統一定會花費的時間,b 是系統速率,D 代表啟始點到目標之間的距離,而 W 則是目標物平行於運動軌跡的長度。看起來一點都不討喜,對吧?我們可以用下圖來簡化一下費茲定律的意思:
其中 T 代表所花費的時間,a 是系統一定會花費的時間,b 是系統速率,D 代表啟始點到目標之間的距離,而 W 則是目標物平行於運動軌跡的長度。看起來一點都不討喜,對吧?我們可以用下圖來簡化一下費茲定律的意思: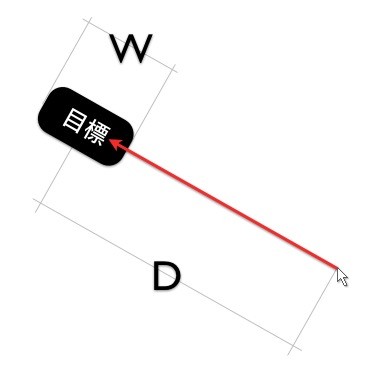 用圖來解釋,就是當 D(啟始點到目標之間的距離)越長,使用者所花費的時間越多,而當 W(目標物平行於運動軌跡的長度)越長,則花費的時間越少,使用效能也比較好。
用圖來解釋,就是當 D(啟始點到目標之間的距離)越長,使用者所花費的時間越多,而當 W(目標物平行於運動軌跡的長度)越長,則花費的時間越少,使用效能也比較好。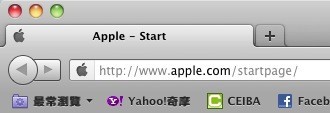 至於 Windows 和 Mac OS X 的選單位置的差別呢?Windows 將選單位置放置在視窗標題的下方,如果滑鼠要從視窗內移動到選單上,這個選單的上下間距是非常狹窄,所以比較不容易點選到正確的按鈕。而 Mac OS X 則將選單放到螢幕的正上方,由於滑鼠移動到螢幕邊界的時候,會被螢幕邊界限制而停下,因此可以將選單的高度(也就是費茲法則中的 W)視為無限大,所以使用者所花費的時間減少,效率也就提昇了。
至於 Windows 和 Mac OS X 的選單位置的差別呢?Windows 將選單位置放置在視窗標題的下方,如果滑鼠要從視窗內移動到選單上,這個選單的上下間距是非常狹窄,所以比較不容易點選到正確的按鈕。而 Mac OS X 則將選單放到螢幕的正上方,由於滑鼠移動到螢幕邊界的時候,會被螢幕邊界限制而停下,因此可以將選單的高度(也就是費茲法則中的 W)視為無限大,所以使用者所花費的時間減少,效率也就提昇了。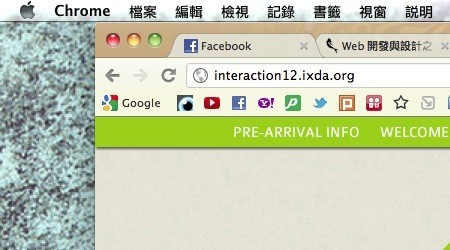 果然惡魔住在細節裡,對吧!
果然惡魔住在細節裡,對吧!







































