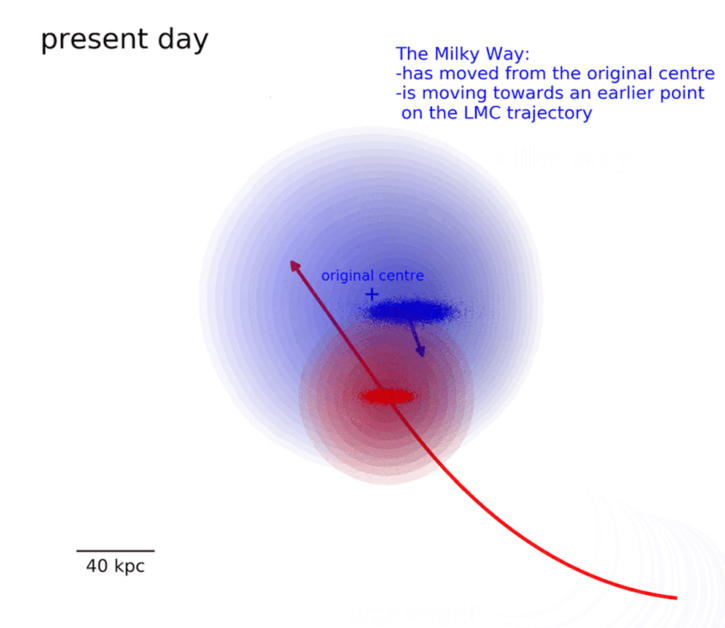
來自愛丁堡大學的天文學家 Michael S .Petersen 與 Jorge Peñarrubia 近期在自然 (Nature) 期刊中,針對銀河系與大麥哲倫星系 (The Large Magellanic Cloud) 的交互運動,有了新的發現。這份最新的研究指出受到大麥哲倫星系重力場的影響,銀河盤面發生偏移,透過測量銀暈(銀河系的主要部分向外延伸,大致成球形的結構)上不同類型恆星的運動,發現銀河盤面正朝著大麥哲倫星系過往的軌跡方向移動,這個觀測結果與數值模擬的模型相符。
圖1. 系外行星系統。母恆星受到系外行星重力場影響而有些微偏移質量中心的圓周運動,紅色圈是母恆星的軌道,藍色圈是系外行星軌道,此系外行星系統質量中心在正中央。由於系外行星與母恆星亮度對比太大不易直接觀測,因此藉由精確測量母恆星的反應運動,可以間接推測此系統是否有行星的存在。模擬動畫/Movie of a star’s reflex motion
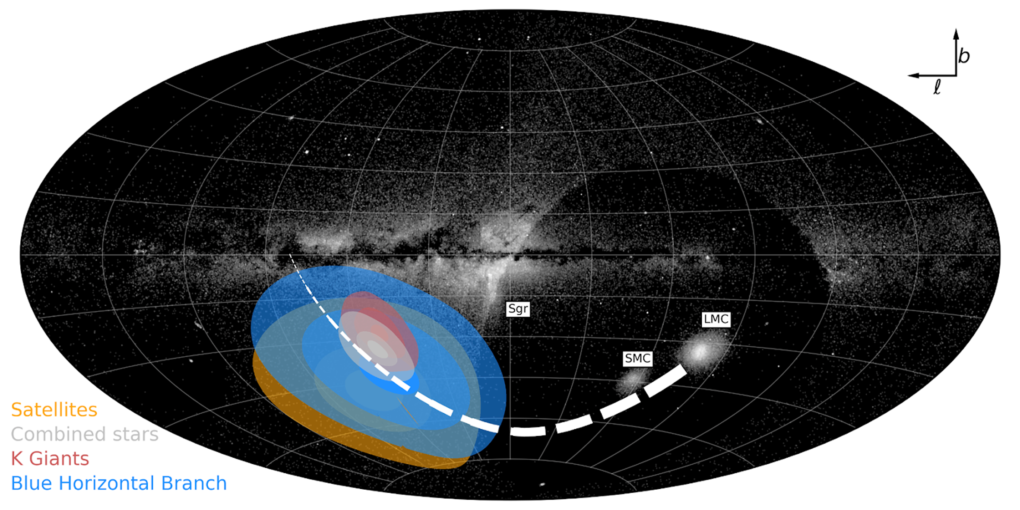
那如何藉由反應運動的測量來分析銀河盤面與大麥哲倫星系的交互運動呢?天文學家 Petersen 等人利用銀暈上的 K 型巨星 (K Giants)、藍水平分支星 (Blue Horizontal Branchs) 和衛星星系來分析銀河盤面的移動速度。這三個分類中,資料樣本數量龐大的亮星來源 K 型巨星,擁有較精確的自行運動測量數值,有助於將盤面移動速度限縮在較小的範圍內,如圖 3 紅色區域所示。
圖3. 銀河系盤面運動方向投影圖。陰影輪廓由淺至深分別表示 67%、90%和 95%銀河盤面運動方向的機率,不同顏色表示不同星體推估出來的機率分佈,淺灰色是綜合統計結果、紅色是 K 型巨星 (K Giants)、藍色是藍水平分支星 (Blue Horizontal Branchs)、橘色是衛星星系 (Satellites)。黑白背景是 Pan-STARRS DR1 和 Gaia DR2 的RR天琴變星的密度分佈圖。LMC是大麥哲倫星系,周圍兩個質量較小的衛星星系分別是:小麥哲倫星系 (SMC) 和人馬座矮星系 (Sgr) ,白色虛線表示大麥哲倫星系過去的運動軌跡。圖/Detection of the Milky Way reflex motion due to the Large Magellanic Cloud infall