


編按:《學生為什麼不喜歡上學?》這本書以認知心理學研究成果為根基,歸納出大腦如何學習和記憶,並提供了教師如何應用這些認知原則於教學現場的方法。
記憶力取決於知識量
說到知識,具備越多知識的人,知識增長得也越快。運用同樣的基本方法,許多實驗都確認了背景知識對記憶的好處。
研究者請一些具備專業領域知識的人(比如說橄欖球或舞蹈或電子電路),以及另一些不具備任何專業知識的人來做實驗。所有人都會讀到一則故事或一篇短文,內容很簡單,即使對該領域不擅長的人也能理解,也就是說他們可以告訴你每句話代表的意思。但到了隔天,有背景知識的人比沒有的人記得的內容要多出許多。

你可能會認為,這個結果是因為注意力造成的。如果我是籃球迷,我會樂於閱讀籃球相關內容,也會讀得特別仔細;相反地,若我不是球迷,我就會覺得無聊。在其他的研究中,研究者請受試者學習對他們來說新鮮的主題(比方說百老匯音樂劇),一半受試者學很多,一半只學一點點。之後研究者請受試者閱讀其他有關該主題的新事實,然後他們發現「專家群」(也就是之前學很多的人)學習新知學得更快更好,勝過那些「新手」(之前只學一點點的人)。
我知道這個主題,所以我記得更好!
為什麼對主題稍有瞭解後,更容易記住內容?我之前說過,如果你對特定主題知道越多,就越容易理解該主題的新訊息。舉例來說,懂棒球的人比不懂的人更容易理解關於棒球的故事。事情有意義,我們會比較有印象。
下一章會對歸納推論更深入討論,但為了讓你先有概念,請讀以下兩段短文:
運動技能學習是執行熟練動作能力的改變,這些動作能達到環境中的行為目標。神經科學界有個根本且未解的問題,就是有沒有獨立的神經系統來代表習得的連續運動技能反應。用腦成像及其他方法來定義該系統,需要詳細描述為了特定的排序任務要學習的確切內容是什麼。
戚風蛋糕將傳統蛋糕所用的奶油換掉,改用植物油。烘焙界有個根本且未解的問題,就是何時烤奶油蛋糕、何時烤戚風蛋糕。以專家品嚐會及其他方法來回答這個問題,必須詳細描述理想中的蛋糕有哪些特色。
第一段落擷取自一篇學術研究論文。7 每個句子都可以理解,如果你花點時間,就能看出句子之間的關聯:第一句提供定義;第二句提出問題;第三句闡述在解決問題前,必須先描述正在研究中的事物(技巧)。
第二段段落是我模擬第一段短文結構所寫的,每一句的結構都是一樣的。
你覺得到了明天再來回想,你會對哪一篇比較有印象?

第二段段落較容易理解(因此較易記住),因為你可以將內容和已知的事物連結起來。經驗告訴你,好吃的蛋糕滑順有奶油香,而非植物油的油膩,所以有些蛋糕改用植物油這個事實就足夠引起你的注意了。同樣地,最後一句提到「理想中的蛋糕有哪些特色」,你能想像蛋糕的特色可能是鬆軟、濕潤等等。
請注意,這些結果和理解無關;儘管缺乏背景知識,你也能理解第一段段落,不過少了點廣度和深度。那是因為當你有背景知識時,儘管不自覺,你的大腦也會將你所閱讀的內容,和你對該主題已知的資訊連起來。

幫助記憶的關鍵就是這些連結;記住東西基本上就是給記憶提示。當我們想起和目前正試著要記起來的事物有關的東西時,就是在記憶裡搜索。因此,當我說:「想想你昨天讀過的短文」,你會對自己說:「嗯,跟蛋糕有關」,然後自動地(也許完全不自覺),關於蛋糕的訊息開始閃過你的腦海——是烤的……有糖霜……生日派對……用麵粉、蛋、奶油做的……突然之間,那個背景知識(蛋糕是用奶油做的)為回想起短文提供了立足點:「啊哈,是關於棄奶油改用植物油來烤的蛋糕。」把短文中的這些句子加入你的背景知識,會讓短文更容易理解,也更好記。但是啊,運動技能的短文卻孤立無援,獨立於任何背景知識之外,所以之後比較難想起。
不只金錢,「知識」也是富者越富
長期記憶中存在事實型知識使得獲取更多事實型知識更容易,這個背景知識的最後效應值得多加思考。你能持有的訊息量多寡,端賴你已經具備的訊息量。所以,如果你具備的訊息量比我多,那你能獲得的就比我更多。
為了讓這個概念更具體(但讓數字清楚可辨),假設你的記憶中有一萬筆事實,但我只有九千筆,我們各自記住一定比例的新事實,比例多少視個人記憶中原本有多少而定。你可記得你聽聞之新訊息的百分之十,但因為我長期記憶中的知識較少,我只能記住百分之九的新訊息。假設我們兩人每個月都接觸五百則新訊息,表 2-1 顯示了十個月之後我們兩人長期記憶中所有的訊息量。
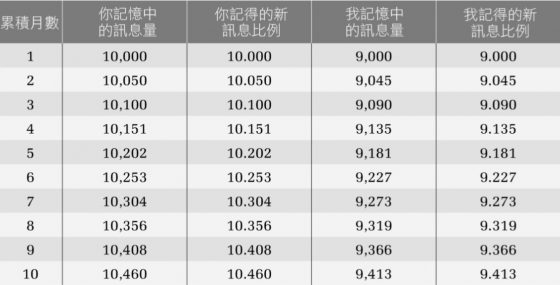
十個月之後,我們之間的差距從 1000 筆訊息拉大成 1043 筆訊息。因為長期記憶中儲存內容越多的人,學習就越容易,所以差距只會越來越大。我要迎頭趕上別無他法,只能接觸比你更多的事物。就拿求學來說,我得努力趕上,但執行起來很難,因為你以持續增加的速度在拉大我們之間的差距。
前例中的數字當然都是我編的,但基本觀念正確無誤——富者越富。我們都知道豐饒物產哪裡可以找到,如果你想接觸新單字與新觀念,你要從書本與報章雜誌裡找,學生流連忘返的電視、電玩與網路(比如社交網站、音樂網站等等)多半都是沒有幫助的。研究者悉心分析學生閒暇時間會接觸的許多內容,書籍、報紙、雜誌對於學生認識新觀念與新單字格外有幫助。
知識才是比想像力更重要
我在本章一開始引用了愛因斯坦的名言:「想像力比知識更重要。」希望現在你已經相信愛因斯坦是錯的。
知識更重要,因為知識是想像力的先決條件,或至少是引發解決問題、作出決策與創造力之想像力的前提。其他名人也曾發表過知識無用之類的 言論,見表 2-2:
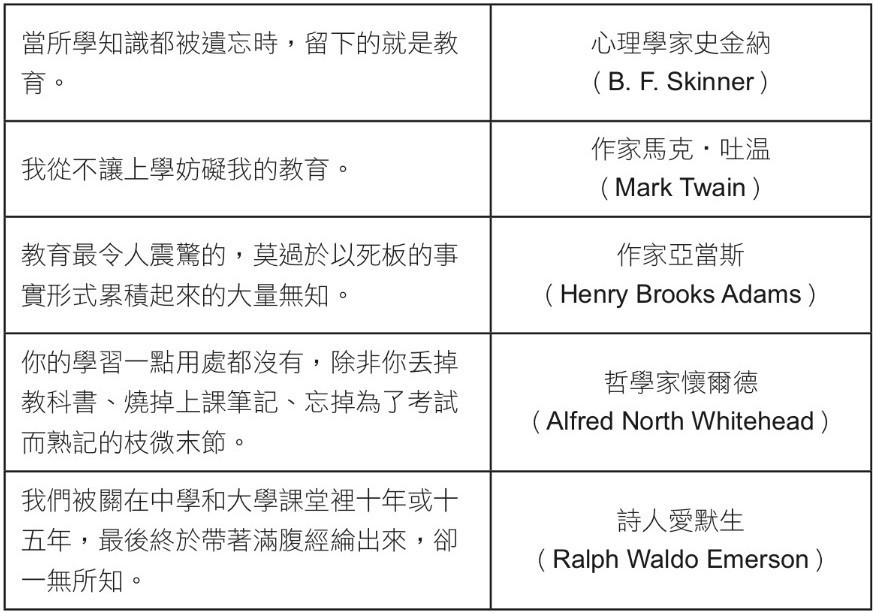
我不知道為什麼一些偉大的思想家(他們毫無疑問相當博學)那麼喜歡詆毀學校,視學校為只讓學生進行無用知識背誦的工廠。我想我們應該把這些看法視為反諷,或至少是趣談,且我不需要傑出、能力過人的智者告訴我(和我的孩子)得到知識是多愚蠢。
正如我在本章所言,最高階的認知過程——邏輯思考、問題解決等等——都和知識密不可分。確實,沒有能力使用知識,空有知識也是枉然;但同樣地,沒有事實型知識絕對不可能有效運用思考能力。
在此我引用一句西班牙諺語,提出與表 2-2 語錄不同的見解: 「Mas sabe El Diablo por viejo que por Diablo」。大致是說:「魔鬼之所以是魔鬼,並非因為有智慧,而是因為有年紀。」這句話強調經驗很重要,由此推斷知識亦然。

本文摘自《學生為什麼不喜歡上學?:認知心理學家解開大腦學習的運作結構,原來大腦喜歡這樣學》,久石文化,2018 年 12 月出版。



































