


- 文/慕容峰│從事數位鑑識工作多年,在分析證物的過程中,彷佛側耳傾聽證物娓娓道來一般,同時審慎客觀地仔細分析察看,即便是旁枝末節也不輕易放過,浸淫其中而樂此不疲。
說起數位鑑識(Digital Forensics),多數人是丈二金剛摸不著頭,搞不清楚它是什麼來著。但只要提及熱門的 CSI 犯罪調查影集,大家便能心領神會,甚至還可以憶及相關橋段,引發熱烈討論。
磁碟格式化時會發生什麼事?
沒錯,只要是與電子跡證有關的,便是數位鑑識的範疇。而由於電子跡證具有易遭污染破壞的特性,因此,簡而言之,數位鑑識科學便是用嚴謹的程序及工具,對電子跡證進行提取並加以分析,以還原犯罪事實及手法的科學。
而在一椿涉及犯罪的調查案件中,任何具有儲存電子跡證的儲存媒體,例如手機、硬碟、隨身碟、CD/DVD、記憶卡等等,皆是不可輕忽的證物。以下且讓筆者以 Windows 平台為例,來為各位說明磁碟格式化的奧秘。
各位應該都有將硬碟或隨身碟進行磁碟格式化(disk formatting)的經驗,如下圖所示。
在真正開始進行前,還會彈出一個視窗讓使用者進行確認:
只見不一會兒功夫便完成格式化,會彈出如下圖的確認訊息。
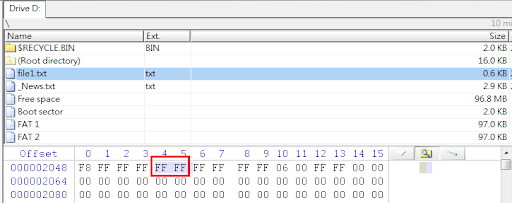
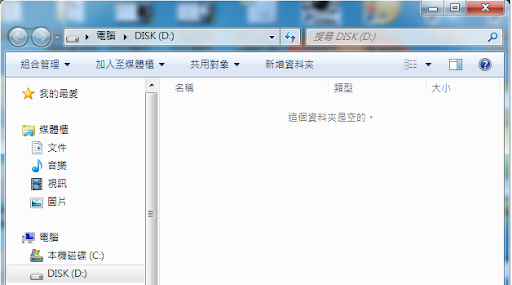
被格式化後的分區之中,其原有的內容竟已不復存在,成了空空如也的狀態,如下圖所示。
由於格式化一個硬碟分區的效果,看起來就像是轉瞬間刪除掉該分區裡的資料夾及檔案一般。因此,在進行格式化前,使用者應該都會先確認已做好備份工作的前置作業,才會放心地進行格式化。
磁碟如何存放資料?「檔案系統」的秘密
在這看似已空無一物的硬碟分區之中,其實背後還藏著秘密。在此先賣個關子,且容我先為各位說明傳統硬碟與資料的關係。當使用者在電腦上建立檔案輸入內容時,傳統機械式硬碟如何儲存數據呢?由物理層面來看,是因為磁頭於磁盤上繪出正負極磁性不同的「圖畫」所致,這些便是使用者所儲存在硬碟中的資料。因此,要傾刻間徹底清除硬碟裡的所有資料,就必須要「消磁」。
而從邏輯層面來看,硬碟存放資料與「檔案系統」(Filesystem)有所關聯。舉凡你在檔案總管之中進行資料夾或檔案的增刪修改,皆是在檔案系統的機制下進行。我接下來以圖書館的書目館藏來做比喻,大家應該有到圖書館借書的經驗,通常到了館內,來到「檢索區」使用電腦進行書目館藏的查詢,便可知道你想要借的書是否在館內,且是位於哪個區域的哪個架上。這些書是依循一定規則經過分類編目的,而能快速地查找到其所在位置則是索引(Index)的效果。
如同圖書館裡的大量館藏受館藏系統管理,儲存在硬碟中的檔案,也受到檔案系統管理。而使用者只要透過檔案總管,就像使用館藏系統一樣便能輕鬆進行相關操作。簡而言之,檔案系統有維護著一個表格,存放著目前有哪些資料夾或檔案,及其名稱與所存放的位置等資訊。
各位可以想像一下,若此刻館藏系統因故關閉無法使用,你要如何才能找到想借的書呢?也許有人會說,很簡單啊,問館員或自己到處逛,應該也可以找的到。把此情境搬到電腦之中,就如同把前述檔案系統所維護的那張「表」給拿掉,此時檔案總管中還能看到目前有哪些資料夾或檔案嗎?答案絕對是否定的。
如此一來,各位便可以理解了,磁碟格式化的效果就如同把圖書館的館藏系統關閉,讓你無法藉由系統進行查詢了。而此時雖然看似什麼書都查不到了,但其實書還在架上並沒有不見。因此,硬碟分區格式化之後,只是失去了記錄相關資訊的目錄罷了,資料本體仍存放在原處。
各位可能或多或少都曾有過不慎將存有資料的裝置進行格式化的經驗,現在聽了上述解說,你便可以了解到要對遭到格式化的儲存裝置進行資料救援,並非難如登天,關鍵就在於找回檔案系統維護的那個「表」即可。只要有了那個目錄,想找到格式化前登記在案的那些資料夾和檔案,就輕而易舉不費吹灰之力了。
找回檔案配置「表」,就復原了檔案!
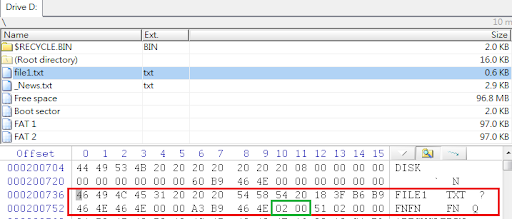
至於如何找到那張「表」?聰明的讀者應該已經猜到它肯定是個檔案才是。沒錯,而不同檔案系統的管理機制有所不同,其代表檔案配置的表也不同,以 NTFS 檔案系統而言,那張表叫做「MFT」;而 FAT 檔案系統的表則叫 FAT(File Allocation Table)。
也許有人會說他根本沒在檔案總管中看過這些檔案,的確,這配置表是屬於系統保護檔案,無法藉由檔案總管存取,但仍可透過鑑識工具或資料救援工具進行存取。
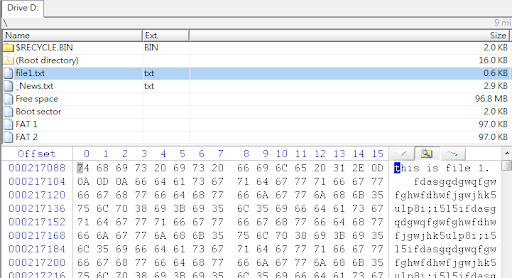
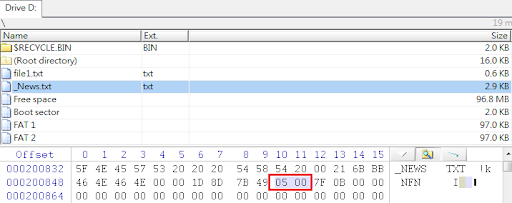
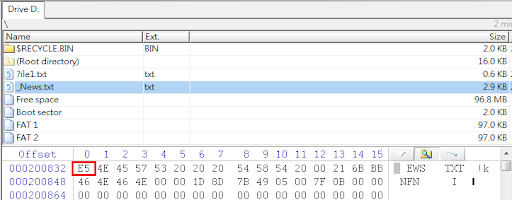
我們再把焦點拉回前述我們已完成格式化的隨身碟,儘管看似空無一物,沒有任何檔案或資料夾存在其中,但經以專業工具進行回復,竟能順利找到那些代表檔案配置的「表」了,如下圖所示。
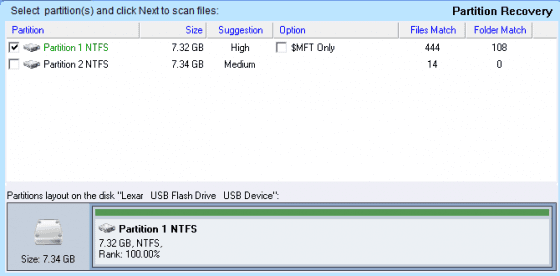
也許有讀者會感到好奇,找到的表不只一張,那究竟哪個表能讓我們回復出最多的資料呢?專業回復工具會把可回復資料最多的表列為最高優先,如上圖的分析結果所示。
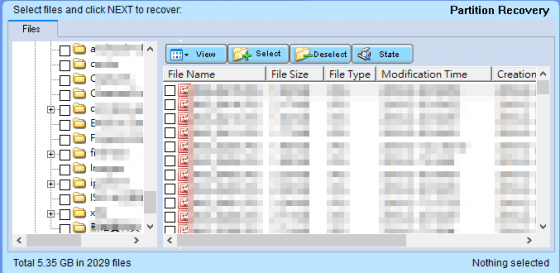
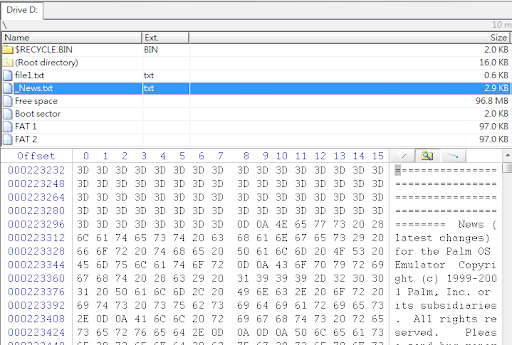
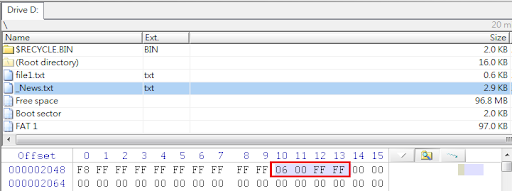
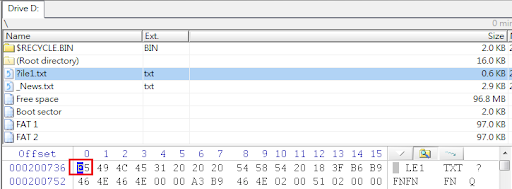
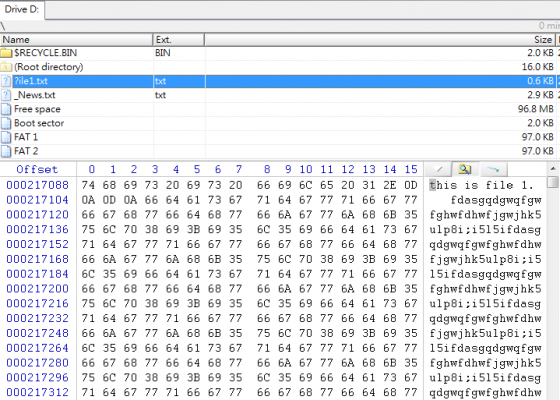
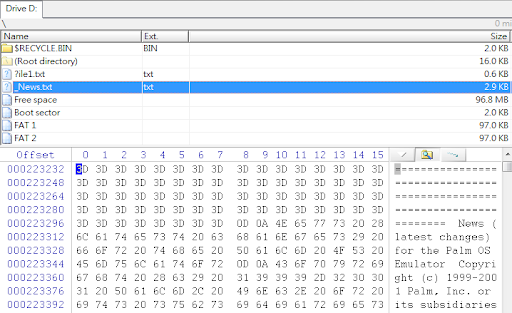
接下來我們就來看看這張表能否按圖索驥找出那些仍然存在的資料夾及檔案,果然沒有令我們失望,分析結果如下圖所示。只要挑選欲回復的資料夾或檔案加以匯出,便可完成資料救援工作了。
在一椿電腦犯罪調查案中,若鑑識人員發現證物電腦的整顆硬碟或特定分區,裡頭竟是空無一物,便會合理懷疑可能是遭到有心人士進行格式化等滅證行為發生。為了找出與案情相關的線索,以還原犯罪事實及手法,鑑識人員便會採用專業鑑識工具進行資料還原,再對還原出的檔案內容進行分析,釐清相關案情。
數位鑑識是門嚴謹的科學,各位應該聽過一句俗諺「The footprint in the sand shows where you have been.」這與常言道:「凡走過必留下痕跡」毫無二致。至此相信各位對數位鑑識科學應有了進一步的認識,下回將為各位進一步說明檔案刪除的奧秘,敬請期待。
參考資料:
- 維基百科──數位鑑識
- 維基百科──磁碟格式化
- 維基百科──檔案系統
- microsoft──Master File Table
- microsoft──FAT File System



































{kind=link}
{kind=link}