「數據分析」結合「機器學習」,探勘書市商機
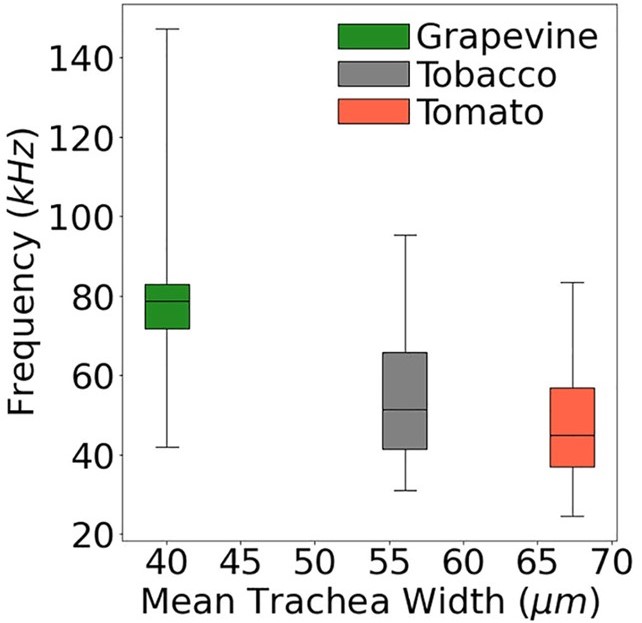
誰在買書?買什麼書?這是規劃出版與行銷計畫時,需考量的因素,過去僅能用專業經驗判斷,現在透過資料分析與機器學習,可以用客觀的科學輔佐主觀的決策。中央研究院資訊科學研究所陳昇瑋研究員,帶領資料洞察實驗室,找出書籍銷售數據中潛藏的商機。
資料科學:先搞懂如何發生,再讓它發生
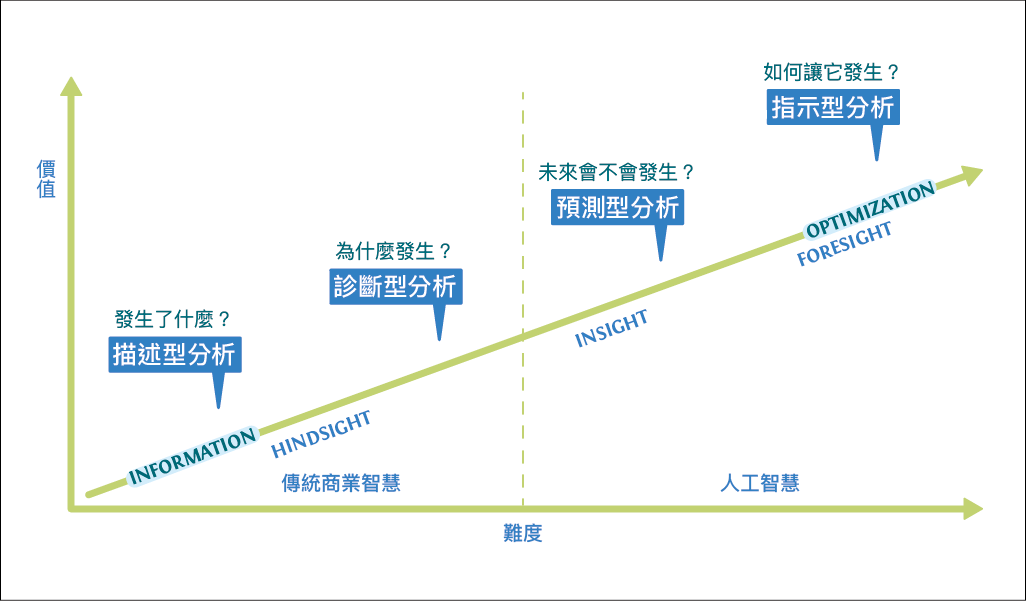
資料分析並非輸入數據、按下 Enter 鍵,就能得到立即性的結果,其工作至少可分為四個層次:
1. 描述:瞭解眼前發生了什麼,例如讀者是什麼樣貌
2. 診斷:用電腦來診斷眼前這件事為何發生,例如某些書籍的銷售為什麼特別好
3. 預測:未來會不會發生某件事,例如預測新書的銷售表現
4. 指示:如何促進某件事在未來發生,例如建置自動薦購系統或上架小工具,幫助提升新書銷售;或是幫書籍做更合適的命名以及封面設計
資料分析跟淘金一樣困難,若沒有以正確的方式使用合適的工具,什麼價值也淘不出來。
分析原始資料就像在砂礫中淘金,雖然不用冒著日曬雨淋的痛苦,但需長時間與電腦折騰,結合數學、統計、機器學習、資料探勘與資料視覺化的專業,整理資料的邏輯,找出隱藏在數據中的含意。若遇到非結構化的資料,在分析前尚需花額外的心力半自動或手動地將之轉換為結構化資料,才能使用分析技術來處理。但正因資料分析可以找出隱藏在數據中的洞察、輔助人類的思維,是一門值得投資心力的科學。
中研院陳昇瑋團隊與博客來合作,將 2014 年 12 月 至 2016 年 3 月間的匿名購書資料,結合政府資料開放平臺的數據,包含各個地區的綜合所得稅申報情況、教育程度、2016 年總統大選得票數等,探討購書行為和讀者生活型態的相關性,將不同購書客群之間的「差異性」數據化,藉以回答誰在買書、買什麼書、什麼書會暢銷……等問題,進而將資料科學的思維引入出版界,讓出版人不用再只是憑著經驗及感覺選書及做書。
什麼人在買什麼書?
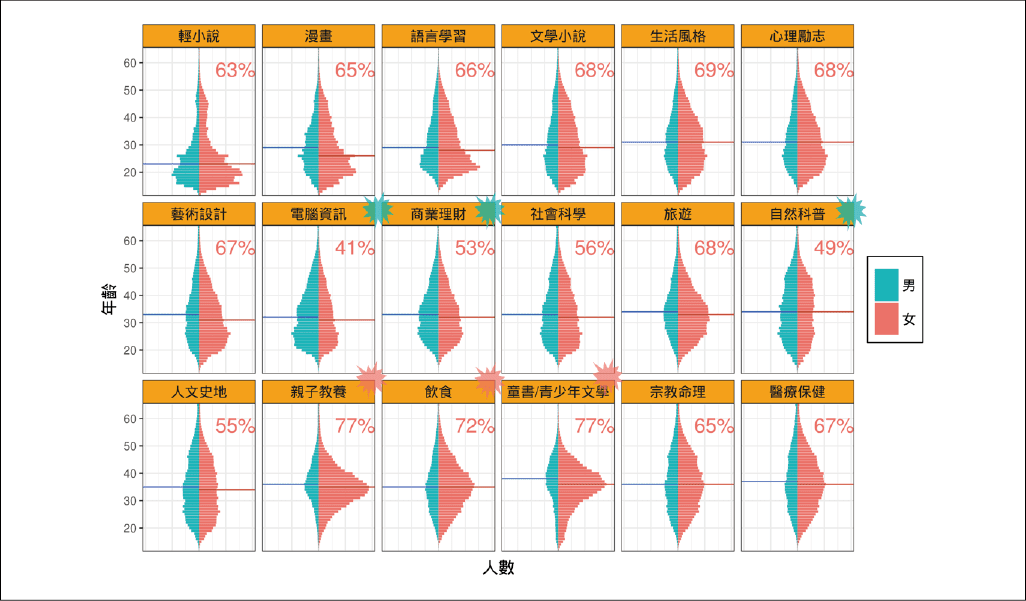
從博客來的匿名消費資料,顯示讀者基本樣貌與購書興趣為:男性較多購買自然科普、電腦資訊和商業理財的書籍,女性較多購買親子教養、飲食、童書和青少年文學。長輩較多購買童書、宗教命理和醫療保健的書籍,而年輕人較多購買輕小說、漫畫和語言學習的書籍。
一樣米養百樣人,一種書也能吸引百種讀者
在規劃出版與行銷策略時,有一個盲點常被忽略:
不能將同一個書籍類別的讀者,都視為同樣一個族群。
過往看銷售報表與會員資料時,經常會把讀者視為只有一種樣貌:例如財經讀者就是白領階級。但陳昇瑋與團隊定義「差異式讀者樣貌分析」,一層一層深入子類別探勘資料,證實同一個書籍類別亦存在「多重客群」。
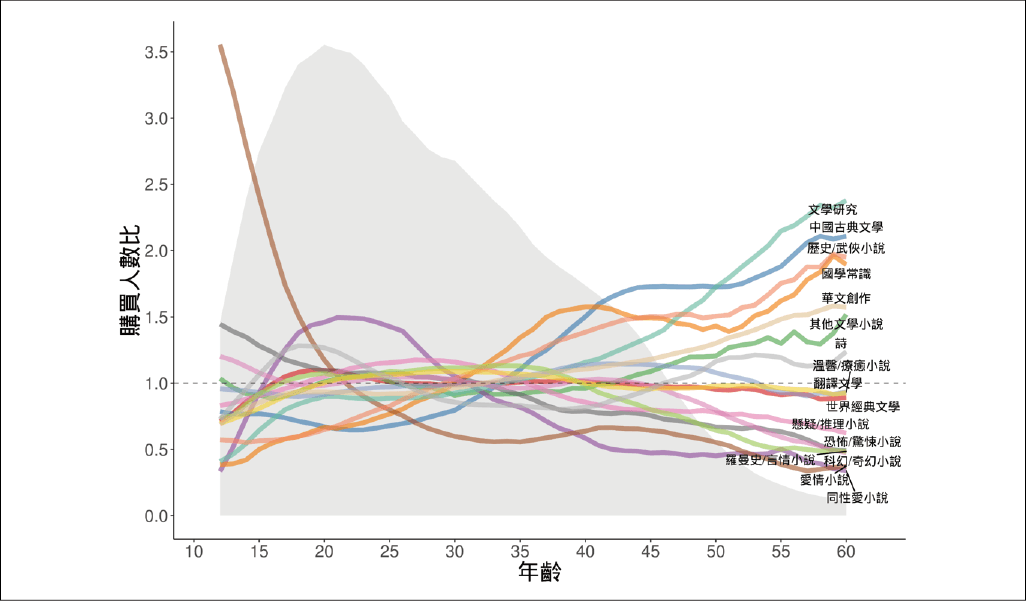
以「小說」這個大類別為例,愛看「小說」的不會只是同一群人,例如都是戴著眼鏡的文青。同性愛小說和愛情小說的讀者主要是年輕人,而歷史武俠和文學研究的小說,讀者群以長輩為主。若進一步深入分析武俠小說中的「金庸」這個子類別,更存在兩種主要客群: 15 歲以下的青少年和 40 ~ 50 歲的中年人。
這反應出一個課題:出版與行銷規劃需更分眾、更精準,無論是溝通的宣傳語言、購買的行銷版位,皆需考慮多重客群的存在。
從購書數據一窺社會現象
世間男女情愛糾葛,李組長眉頭一皺發現事情並不單純,這種社會議題不只在電視劇或新聞中出現,也顯現於購書行為中。
在商業理財的類別,存在許多教導如何成功的書,數據顯示 25 歲以前偏好購買「生涯規劃」類的成功經驗書籍,而 30 歲之後改買如何「致富」的成功指導書籍,顯示 30 歲大關是人生覺悟的交叉點,與其花時間規劃生涯卻前途迷茫,快速致富還比較實際,但也可能因為 30 歲之後除了養自己也要養家人,肩膀壓力更重了。
另一方面,低收入族群偏向購買「投資理財」、「網路創業開店」的書籍,高收入族群則偏向購買「傳記」、「快樂學」的書籍,顯現 M 型社會下兩種不同人生方向與思維,有錢人需要學習如何快樂,而中產階級正朝著累積財富努力。
「外遇離婚」相關的書籍,會購買的族群大多年收入超過 70 萬,年收入越高,購買者越多,箇中含意不便多加著墨。
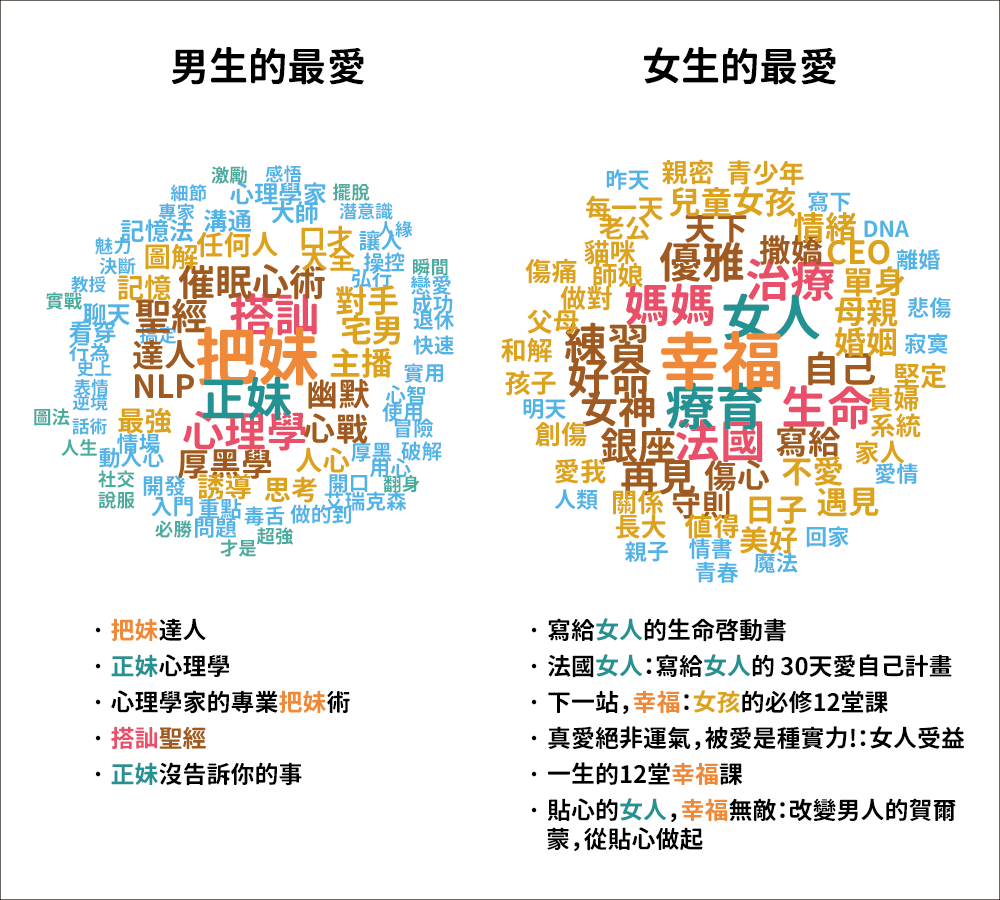
若將男性與女性消費者購買的書籍類別和數量,以書籍關鍵字作成文字雲,明顯看出男女想法大不同。在「心理勵志」這個書籍類別中,男性多關注「把妹、正妹、搭訕」,書中自有顏如玉是從古至今不變的智慧。而女性多關注「幸福、療癒、女人」,顯示現今女人越來越懂得要愛自己,是個樂見其成的社會風氣。
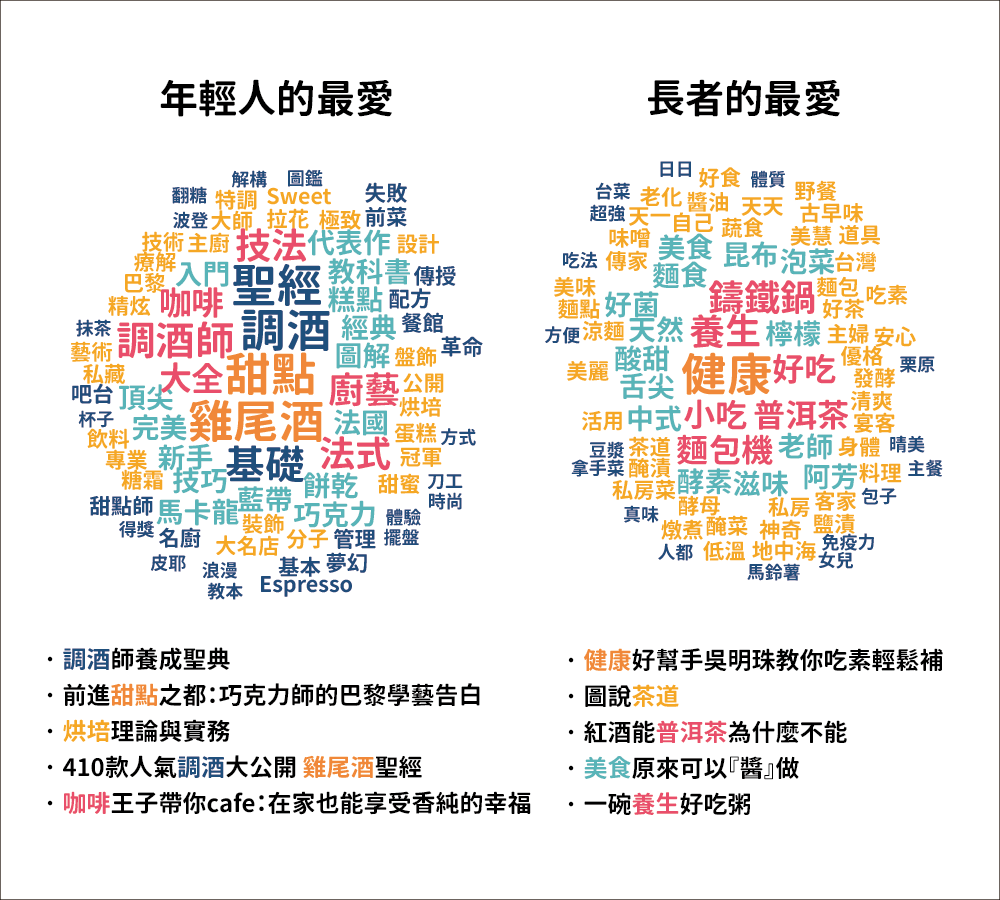
無論是賣書或餐飲業,都值得注意年輕人與長輩的喜好差異。「甜點、雞尾酒、廚藝、咖啡」相關書籍熱銷,與近來市場上年輕族群的甜點學校、咖啡開店熱潮相輔相成。而長輩較喜歡「健康、養生、好吃」相關書籍,對於市場而言,開發同時符合健康及好吃需求的餐飲,是顯著的商機。
「養生」這個書名關鍵字,在「飲食類」受到長輩歡迎,但在「醫療保健類」在銷量上並沒有同樣得到大眾的青睞。
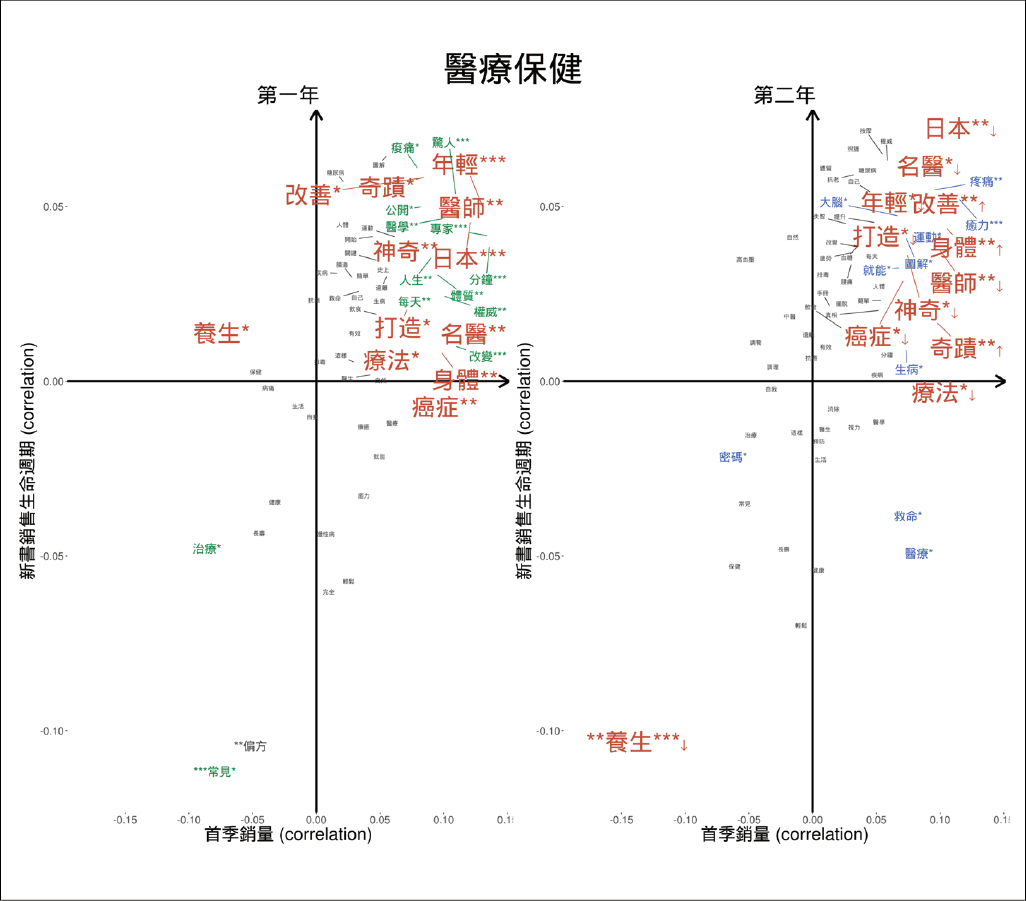
陳昇瑋與團隊以「書名關鍵字」,找出關鍵字與暢銷書之間的相關性。在醫療保健類發現,「養生」這個關鍵字不受到讀者歡迎,反而是「名醫、改善、療法、奇蹟」這類關鍵字能抓住讀者的眼球與荷包。也許這反應出一個醫療保健現況:在一秒鐘幾十萬上下的今日,人們不注重花費時間經營的健康之本──日常養生,而是在症狀出現時追求速效的醫療結果。
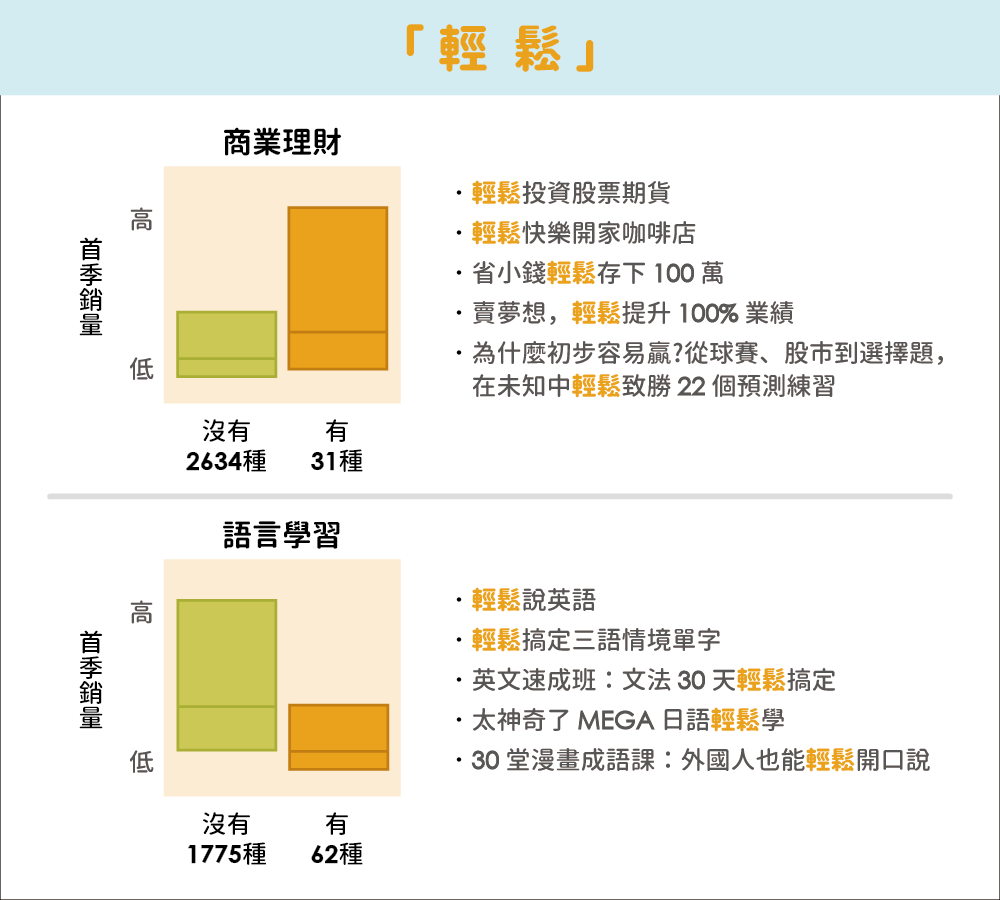
「文字」在不同環境中,會發揮不同力量。同一個書籍關鍵字,在不同書籍類別中,會產生不同的銷售表現。例如,「輕鬆」這個字是行銷時常使用的關鍵字,彷彿在告訴消費者一旦買了這個產品,就能豪不費力地享受好處。對於「輕鬆投資、輕鬆存錢、輕鬆提升業績」這類輕鬆致富的願景,讀者們的想法是「反正我是信了」。但如果在不努力就沒有收穫的語言學習類別,就算告訴讀者「輕鬆說英語、輕鬆搞定文法、輕鬆學日文」,銷量顯示讀者們不會買單。
哪些書會暢銷?除了財神,也能問問電腦
以上內容尚處於資料分析的「描述」和「診斷」階段,真正有意義是分析的第三階段「預測分析」,藉由機器學習技術自動歸納出書籍銷量與各式書籍屬性的相關性,進而建立銷售表現的預測模型。
「機器學習」的作法為,讓程式自動學習哪些因子是重要的,預測某本書成為暢銷書的機率。

在「預測分析」這個工作階段中,陳昇瑋團隊運用「書籍屬性」、「書名關鍵字」及「上市前的市場狀況」來發展暢銷書預測的模型,以文學小說類別測試,其暢銷書的預測準確度可以接近八成。預測分析的最終目的為「指示型分析」,也就是資料分析的第四個工作階段,透過程式的指示提供最佳化建議,例如書名及副標怎麽下、書介如何編排、預覽圖片要放哪幾張、如何訂價及折扣……等等,協助拉近書籍與目標消費者的距離。
有時資料分析的結果很殘酷,會顯示過去在編輯與行銷上的直覺是不符合現實的,有時則能佐證某些觀察的可信度。資料科學及人工智慧技術,並非為了取代人類而生,最重要的觀念是:從經驗導向的世界換位思考,以客觀的資料事實及科學方法,輔助決策的進行,提高決策的正確機率。
現在,無論在出版業、零售業或電子商務領域的你,準備好用「資料科學」突破過往的認知了嗎?
延伸閱讀:
- 執行編輯|林婷嫻 美術編輯|張語辰
![]()
本著作由研之有物製作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位





























-200x200.jpg)