文/陳民峰|現職國小教師,關心生態、教育、動保議題,喜愛科學小知識。目前為到國語日報科學版、聯合報鳴人堂、人文主義工坊作家。
色盲是一種無法分辨部份或所有顏色的疾病,色盲患者通常從小就以為自己辨認的顏色是正確的,往往到長大已後才會發現與別的人所認識的色彩不同。
在《應天雜記》曾經記載一個趣事:明朝皇帝朱元璋上朝前,揮毫畫出一幅雄雞報曉圖,上面一頭雄雞昂首。再提上《雞叫》一詩「一叫一勾勾,兩叫兩勾勾,三叫日出滿天紅,驅散殘星月朦朧」。圖中的公雞雞冠比太陽大、比太陽紅,宛如君王志大功高。
隨後,朱元璋上朝時公佈出來,獲得百官喝采。朱元璋心滿意足的給愛臣徐達。徐達見了馬上奉承:「這隻雄雞的大黑冠看起來多威風!」
朱元璋與眾臣十分驚訝,頓時默聲!當庭信口胡說乃為欺君之罪,徐達膽敢開這種性命攸關的玩笑?朱元璋相信年幼就相處在一起的好友,應該不會這般胡鬧,隨即岔開話題。
過了沒多久,朱元璋生病時突然發現五味具失,突然想到:若是罹患疾病,也可能導致六色具失。徐達認紅為黑的事情,或許是罹患眼疾,朱元璋驚恐差點錯怪臣子。朱元璋後來詢問太醫曹春民「徐達視色不明」是否為眼疾,太醫沒有給予答案,也沒有進行研究。
關於色盲發現的故事不會這樣一直帶過。
道爾吞的色盲理論
400 年後,提出著名「原子說」的科學家道爾吞(John Dalton)誕生了。或許大家比較少知道的是:道爾吞其實本身是個色盲,歷史上明確提出色盲的現象,寫出第一篇關於色盲的論文。

故事是這樣的,1792 年道爾吞到一間很小間的新大學任教,因為要接觸到植物學,所以要跟花朵與葉子的顏色打交道。道爾吞受到恩師果夫影響,教學時很喜歡跟學生討論,此時發現他所認識到的顏色與學生似乎有點不太一樣,因此開始史上第一個研究「色盲」的研究。
道爾吞認為:患有色盲的人也難以察覺自己有色盲,何況其他人能夠察覺?
面對這難以說明的主題,道爾吞便以自己作為例子作為說明。道爾吞透過科學方法與人口做研究,1794 年發表了《關於顏色視覺的特殊例子》。對於色盲進一步描述「色盲看見藍色或紫色的物體時,會當作相似的顏色。但能夠區別藍色與黃色是不同的」

論文提到了道爾吞的哥哥也是色盲,因此推測色盲可能是會遺傳的。並且做了下列結論「色盲的成因,是眼睛中的水樣液無法吸收紅色光所致」。
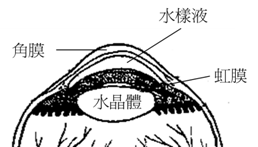
道爾吞希望他顏色辨認的問題能夠查明,自願死掉以後,請人取出他的眼球給後世研究。死後的解剖發現,道爾吞的眼球水樣液並不是藍色而是正常透明的,並不是他的眼睛替他戴上了有色的眼鏡。
之後世界各地也將色盲稱為「道爾吞症」。

色盲之謎:眼睛中感色細胞出問題了!
但色盲怎麼一回事?色盲之謎在後世才有解答。
科學家發現眼睛中有兩種細胞:負責感覺亮度明暗的桿狀細胞、負責感覺顏色的錐狀細胞。其中錐狀細胞又有三種,分別感應紅、綠、藍三種顏色。當基因出了問題,使得其中一種顏色靈敏度減少很多,成為色盲了。

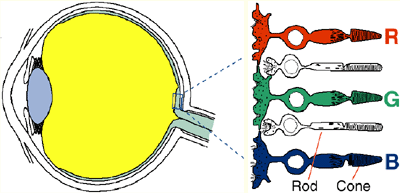
1995 年科學家對道爾吞的眼球進行 DNA 研究,發現道爾吞的基因使得他的眼睛不太能感覺綠色光,屬於第二型色盲,在他的眼裡,紅色、黃色、綠色都差不多。道爾吞原本以為他看不見紅色光,實際上他反而看不見綠色光,將紅綠色混為一彈。才會認為他的世界色彩是被眼睛裡的水樣液搶走了呢!
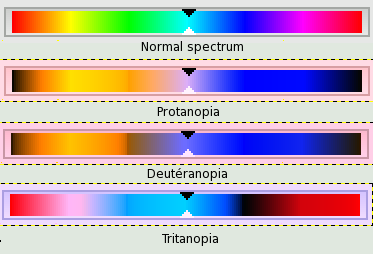
為什麼色盲遺傳比例高?
儘管色盲者在「生活」上可能有些不適應,在「生存」上卻沒有影響。理論上不好的遺傳基因換逐漸被掏選掉,罹患遺傳疾病者應該越來越少,但是色盲的罹患者比率卻相對其他遺傳疾病高,這是個很奇怪的現象。(延伸閱讀:《為什麼要相信達爾文》)
後來科學家也對於各物種進行基因分析。
絕大部分哺乳動物也只能看到兩種顏色,我們回顧生物演化的過程,人類祖先(還不是靈長類的時候)早期夜裡活動,需要的並非顏色辨認,而是更高程度明亮的辨別。色盲者損失了色彩,卻換得黑暗中對光線更敏感,在生理上並不見得吃虧。
有個小趣事紀錄到:二次世界大戰時部份國家專收色盲者,因為色盲者擅於昏暗中行動,並且面對敵軍偽裝有更高的識別力。這或許也能說明我們人類在文明時代以前罹患色盲的人們更能在夜間行動,也間接解釋了為什麼現在色盲基因能夠持續遺傳的比率偏高。
後記補充:
有朋友看到此文章以後跟我討論幾個問題,回應如下:
Q:我有色盲的朋友,他們辨認顏色是根據明亮辨認的。但是我認為色盲使得明亮辨認度增加不是必然結果。
A:這就牽扯到一個問題了:「色盲的光線明暗判斷是否是受到後天訓練影響?」我認為應該會受到後天訓練影響。
文中有提起道爾吞的恩師果夫,果夫三歲時罹患天花導致後天性失明,卻能將嗅覺與觸覺發揮到極致,可以辨認周遭三里內許多植物。因此道理,我認為色盲者在面對明亮變化會敏感,也能可受到後天訓練影響。
但怎樣知道是不是因為後天影響呢?這部分很難做實驗說明。因為小孩子辨認顏色的發展優先於語言,而小孩子能夠跳脫自我中心,體會到自己認識的顏色與別人不同,也是到有語言發展以後的事情。不過有個明確的例子是「全色盲」或者「全色弱」,他們適應黑暗時幾乎不太需要轉換錐細胞和桿細胞。
Q:二戰有許多色盲患者反而被派上軍營,這會不會導致色盲患者大量戰死而使得色盲基因流傳減少?
A:以國家來看有可能,以全世界來看可能影響不大。至少女性帶有色盲基因者不但不容易顯示出來,即使女性色盲患者也不會上戰場。
Q:優生學的概念會影響色盲基因遺傳嗎?
A:優生學的概念大概會影響,所以遺傳疾病使得他們被「人擇」。這也是科技發達以後要進階面對的人倫問題。有些不致命的遺傳疾病都是近代才被發現的,所以優生學的概念對於遺傳疾病或許有影響,但這種人擇壓力也才要起步而已。
本文轉載自蜜蜂老師ㄟ蜂窩。
參考資料:
- 朱元璋,維基百科
- 朱元璋,逆輓詩《雞叫》,百度百科
- 原子理論,維基百科
- 張文亮,道爾頓與化學原子論,科學發展 2002 年 4 月,352 期
- Dalton, Extraordinary facts relating to the vision of colours, London : Cadell and Davins
- 眼的構造及機能
- Jeremy Nathans, Genetic Studies Endow Mice with New Color Vision, Howard Hughes Medical Institute, MAR 23 2007.
- 靈長目彩色視覺的演化,維基百科
- M. J. Morgan, A. Adam, and J. D. Mollon, Dichromats Detect Colour-Camouflaged Objects that are not Detected by Trichromats, Proceedings B, Volume 248, issue 1323, 22 June 1992, DOI: 10.1098/rspb.1992.0074