編譯/莊霈淳|成功大學心理系學生,PanX 實習生
成功是什麼?對科學家們來說,賺不賺大錢不一定是重點,但自己努力大半輩子的研究成果,若不被世人所接受,那可不是「藍瘦,香菇」就能形容的辛酸了。
少年得志的科學家並不少,像是達爾文(Charles Darwin)、瑪莉‧居禮(Marie Curie)、愛因斯坦(Albert Einstein),都在三十歲前就發表了奠定自己科學影響力地位的學說,成為該領域重量級的人物。
但有些科學家就沒那麼幸運了。例如電腦科學之父圖靈(Alan Turing)在戰後遭受迫害、統計大師費雪(R. A. Fisher)則在學術生涯中受到另一位統計先驅皮爾森(Karl Pearson)打壓。他們所做的貢獻,一直要到晚年甚至是在他們過世之後,才重新被世人重視且讚揚。

這些科學家的生命故事,看似都是毫無關聯的個案。但是,一個人的學術生涯是否飛黃騰達、或鬱鬱不得志,究竟能不能用模型預測呢?
論文的引用像是買樂透?
2016 年 11 月,一份發表在《科學》(Science)期刊上的論文,研究者為了回答「如何以模型預測科學家影響力」的命題,分析了多個領域的科學家所發表的論文。
如果說要定義一篇論文的影響力,該用什麼方法將影響力量化?在這篇論文中,研究者將影響力的參數設定為 C10,也就是一篇論文出版十年後的總引用數。
讓你猜猜,科學家一生中最具影響力的論文,會出現在他學術生涯的哪個階段?
一般來說,我們會設想到了學術生涯的後期,科學家會隨著學識的累積和研究經驗成熟,產出更好的研究,而這現象應該會反映在論文引用的數量上——也就是科學家越後期的研究論文,被他人引用的次數應該會更多。不過要讓你失望了,此研究的預測模型並沒有偵測到這個趨勢。
研究者發現,科學家們的高引用次數著作是隨機出現在他們學術生涯中的。可能是初次發表的論文就獲得了極高引用數,或是在學術生涯中期、甚至是最後一篇發表的論文,這種隨機性出現在不同學科、不同職業生涯長度、著作是獨自發表的或是與其他學者聯名發表的科學家身上。
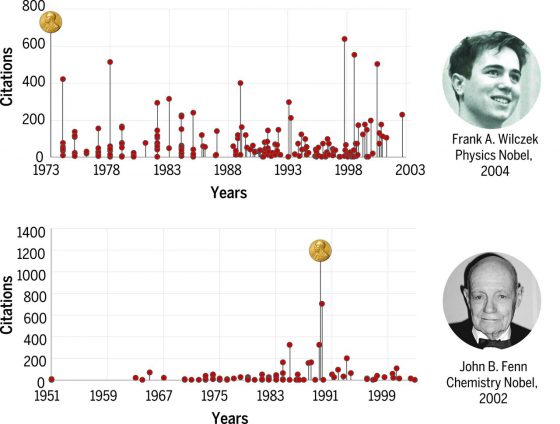
匈牙利中歐大學(Central European University Budapest Hungary)教授羅伯塔.辛納屈(Roberta Sinatra)告訴 Science 的記者:「科學論文本身比較像是樂透彩券,能被多少人引用幾乎是靠運氣。所以發表越多論文,就像是買越多張樂透彩券。在你發表論文數量越多的那幾年,你作為科學家的影響力就可能越大。」
不過有些情況是,研究人員不僅發表論文數量相同,連發表的期刊都相去不遠,但其中偏偏有人的論文就是可以被更多人看到,得到更多引用數。這時候就不能僅用買樂透的運氣來解釋了。
要成為廣為人知且備受肯定的科學家,可能是做了具有開創性的實驗,懂得與其他研究成員共同合作,且能很清楚的闡述自己的研究內容。雖然常常聽到有些人,被詢問是如何取得這般成就時,會以自謙的語氣回答:「沒有啦,運氣好而已。」但認真說來,他的成功其實是綜合天時地利人和的結果。
用參數 Q 預測你的學術地位

這份研究分析了 2887 名符合「學術生涯至少 20 年、發表過至少 10 篇論文,且至少每 5 年有一篇論文發表」這組條件的科學家們。並將這個綜合「天時地利人和」的科學家成功因素,定為參數 Q,講白了點 Q 指的就是個體差異,特別是:口才、團隊合作能力、創作力等能力。研究團隊結合隨機性參數和固定性因素,搭建出預測學術生涯論文影響力的 Q 模型。
研究者表示,透過這個 Q 模型,他們有 80% 的機率能準測預測一個有 20 篇論文、10 年論文發表經驗的科學家 ,第 40 篇發表論文能獲得的引用數。
美國密西根州立大學(Michigan State University)的心理學教授札克.哈布瑞克(Zach Hambrick)如此評論這個預測模型中的參數 Q:
「Q 參數非常有趣,因為它可能涵蓋了一些人們的確擁有,但並不那麼重視的能力:像是清楚說明的能力。比方說,你可能發表了一篇有意思的數學心理學論文,但如果文章不好讀,你就無法獲得廣泛的影響力,因為沒人明白你在說什麼。」
不過也有人懷疑,與其說這個參數 Q 是科學家的個人技能因素,也有可能是科學家的背景、種族、甚至是非理性群體思維和潮流效應等外在因素。
這會是個幫科學家打分數的方式嗎?
艾倫人工智慧研究所(Allen Institute for Artificial Intelligence)的計算機科學家歐倫.伊茲歐尼(Oren Etzioni)認為,對於充斥著各種衡量科學家成就的工具的現代,這份研究著實提供了一份具有價值的參考。
不過當 Science 記者詢問辛納屈自己的 Q 參數時,她說她還沒有達到 20 篇論文的門檻,因此也沒有計算過自己的 Q 參數。至於未來到達了預測門檻,是否會計算自己的 Q 參數,辛納屈也坦白說自己將不會計算。
那麼如果是你,你想知道自己的 Q 參數嗎?
原始論文:
- Roberta Sinatra et al., Quantifying the evolution of individual scientific impact, Science 04 Nov 2016: Vol. 354, Issue 6312, DOI: 10.1126/science.aaf5239
參考資料:
- When It Comes to Success, Age Really Is Just a Number
- Hey scientists, how much of your publication success is due to dumb luck?