文/新媒體世代 | What’s Next for New Media
當社群媒體逐漸融入日常生活,社會科學家們開始關心社群媒體對網路民眾可能造成的影響。雖然網路有助於人們看到更多元化的資訊,但是社群媒體獨有的運算機制(algorithm)卻可能選擇性地決定民眾看到的資訊內容,而著名的「過濾氣泡現象」(Filter Bubble)和「回聲室效應」(Echo Chamber)也應運而生 [1]。
「過濾氣泡」理論主張運算機制會依據網路民眾先前的網路行為(像是按讚、點擊和搜尋紀錄),決定民眾能夠看到的文章,網路媒體像是臉書和 Google 可以藉此來避免民眾看到和價值觀不符,或不感興趣的內容,導致民眾身處多同質性高的言論環境中;而「回聲室效應」則描述網路民眾更容易接觸到和自己意識形態相似,或是價值觀相符的資訊,進而使得民眾得到的網路訊息越來越趨單一化。

許多學者表示,暴露於多元言論和價值觀的機會,對於民主社會養成有正面影響,包括提高民眾對政治事件的興趣、增加對不同言論立場的包容性,以及提升政治知識等;而處在過高的同質性言論環境,則可能會造成像是態度極化等負面影響。然而也有學者指出,處在異質性的人際網絡中(network heterogeneity),部分個體可能會為了避免衝突而降低參與某些政治活動的意願 [2]。
普遍來說,學者們對於網路媒體運算機制可能造成的影響,像是「過濾氣泡現象」和「回聲室效應」,都有諸多疑慮和批評。
然而,社群媒體的運算機制和相關數據大多是不公開資訊,進行運算機制實質影響的研究並不容易且不常見,因此當臉書研究員前幾天在《科學》(Science)期刊發表一篇最新報告「臉書上具多元意識形態的新聞與評論接觸」(Exposure to ideologically diverse news and opinion in Facebook),探討民眾臉書社群網絡組成,以及「用戶個人選擇」與「臉書運算機制」對民眾接觸對立政治立場文章的影響,該篇文章隨即在學術圈以及媒體產業界引起一陣熱烈討論。[3]
研究背景與重要發現
在提出這篇研究報告的相關評論前,先來細看重要的研究背景與發現。
研究背景:
- 研究樣本包括在 2014 年 7 月 7 日到 2015 年 1 月 7 日半年期間,在個人檔案上填寫政治立場的 1010 萬名 18 歲以上的美國活躍臉書用戶(每周需至少登入 4 天),以及約 23 萬筆有關「硬」新聞(像是全國新聞、政治和全球事務新聞等)的連結分享,而每則連結都需要在這半年期間,被至少 20 個前述回報個人政治立場的臉書用戶分享。
- 研究將用戶回報的政治立場轉換成五點量表(-2:非常民主;+2:非常保守),由於只有 9% 的 18 歲以上美國臉書用戶填寫政治立場,且其中只有 46% 填寫政治立場的用戶其立場可以被轉換成五點量表,因此最終研究樣本大約只有所有美國臉書用戶的4% 。
- 每則「硬」新聞連結的政治立場,是透過計算所有該則新聞分享者政治立場的平均值而得,該數值被稱為「內容對齊」(A 值; content alignment),正值代表分享文章立場趨保守派立場,而負值則表示分享新聞偏自由派立場。舉例來說,政治立場偏共和黨的 Foxnews.com 其 A 值為 +.80,而被認為偏民主黨的 Huffington Post 的 A 值為 -.65。
研究發現:
- 研究樣本分享「硬」新聞的行為呈現極化現象,越容易被鮮明政治立場民眾分享的文章(極大或極小 A 值),也就是文章立場越認為越接近自由派或保守派時,分享次數越高。偏保守派文章的分享次數,也比偏自由派文章來得高。
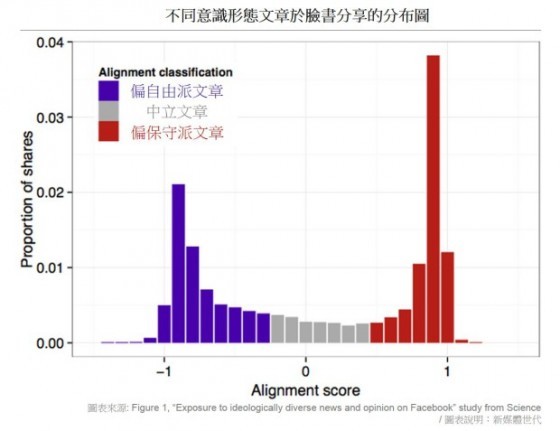
- 研究發現臉書用戶交友情況呈現同質性現象(homophily),政治立場偏自由派用戶的臉書朋友網絡中,有更高比例是同樣傾向自由派的用戶,反之亦然。
- 研究分析用戶在四種狀況下看到(或點閱)的「交叉內容」(cross-cutting content),也就是和用戶政治立場對立的新聞文章。
- 四種情況包括「隨機」(如果用戶能隨機看到所有臉書平台上的內容)、「潛在」(臉書好友們分享的所有內容)、「暴露」(經臉書運算機制調整後,出現在動態牆上的內容),以及「挑選」(用戶自行點擊文章連結)。隨著情況從「隨機」轉變為「潛在」、「暴露」以及「挑選」,用戶接觸的「交叉內容」比例也逐漸下降。換句話說,用戶的臉書交友圈、臉書運算機制,以及個人點擊選擇,都會逐項降低用戶看見的「交叉內容」比例。
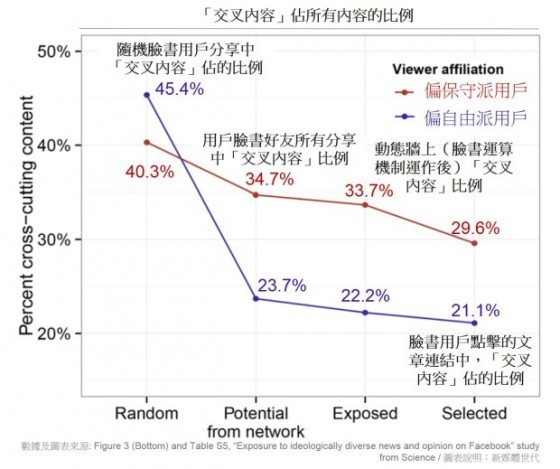
- 當處在「隨機」情況,用戶看見「交叉內容」比例最高(偏自由派用戶可以看見約 45% 的偏保守派內容,而偏保守派用戶可以看見約 40% 的偏自由派文章);如果考量用戶只能看見自己所有臉書朋友的分享內容(「潛在」情況),偏自由派用戶看見的偏保守內容下降為 24%,而偏保守派用戶可以看見約 35% 的偏自由派文章。這也表示,偏自由派用戶其臉書好友中,只有 24% 會分享對立立場(偏保守派)的文章,而偏保守派用戶的臉書朋友中,有較高比例(35% )會分享偏自由派立場的文章。
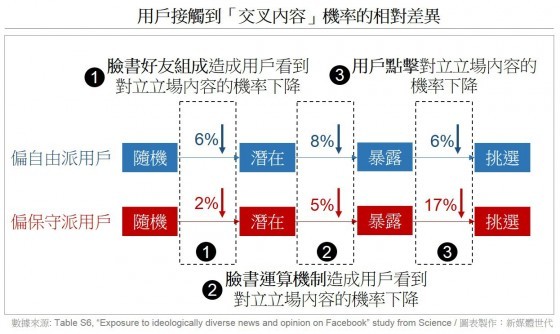
- 該研究也分析四種情況轉變時,用戶看到「交叉內容」機率的變化:臉書機制對於自由派立場民眾的影響(8%)比對於保守派民眾的影響(5%)來得大;而個人點擊選擇對於保守派立場民眾的影響(17%),則比對於自由派民眾的影響(6%)來得大。
- 該研究也證實文章在動態牆的排序,確實會影響文章被用戶點擊的機率。排序在臉書動態牆前面的文章,遠比下面的文章有更高的閱覽機會。臉書研究者也在文章中表示:「用戶在動態牆上看到文章的順序由許多因素決定,包括用戶拜訪臉書的頻率、他們和特定朋友的互動頻率,以及用戶過去多常點擊特定網站的連結。」
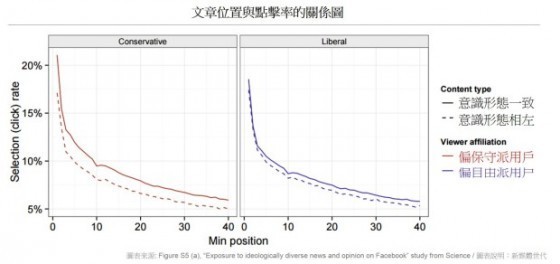
- 整體而言,臉書用戶樣本平均只會點擊動態牆上 7% 的「硬」新聞內容。
該研究指出,和社會普遍對網路民眾「只會和意識形態相近者互動」的想像不同,研究結果證實民眾不是只會接觸到和自己立場相近的文章,社群媒體(臉書)還是會讓民眾閱讀到部分政治不同立場的新聞文章。研究也表示,「或許不意外地,我們的社群網路組成,是限制我們在社群媒體上看見多元內容最重要的因素。」[註1]
臉書研究員們為這篇研究報告下了個總結:「最後,我們的結果確切地顯示出,在臉書上的平均狀況而言,個人選擇比起運算機制,更容易限制用戶看見挑戰個人價值觀的內容」,以及「我們的研究結果建議,要讓個人在社群媒體有暴露於對立意識形態觀點的機會,用戶個人有首要及最關鍵的掌控權。」[註2]
社會科學家們的評論
這篇文章可以說是難得的透過臉書實際數據,來回答社會學家長久以來關心的社群媒體研究課題。只是,重要的研究價值雖然並引起眾多關注,卻也引來部分學者批評。
像是密西根大學傳播學系副教授克里斯提· 桑維(Christian Sandvig)發表一篇標題為「臉書的”這不是我們的錯”研究」,抨擊臉書研究中不合理之處,以及不尋常的論述包裝。北卡羅來納大學教堂山分校資訊與圖書館學系助理教授澤奈普· 圖費克吉(Zeynep Tufekci)也在網誌中寫道「我讀過很多學術研究文章,通常作者都會想方設法地突顯重要發現。然而(臉書的)這篇研究,卻盡可能地透過迂迴的言語和不相關的比較,來隱藏研究發現」。而「過濾氣泡現象」提出者伊萊·帕李澤(Eli Praiser)也立即對這篇研究做出回應,雖然用詞相較之下和緩許多,但是文中仍點出不少該研究不足之處。[4]
為什麼臉書的研究文章會讓學者們產生這些批判呢?最重要的關鍵問題在於,研究最後總結表示「個人選擇」比起臉書的「運算機制」,更應該為臉書上的「過濾氣泡現象」和「回聲室效應」來負責。

學者們表示這樣的說法並不恰當,原因包括:
- 伊萊·帕李澤表示,雖然研究證實用戶的「臉書社群組成」和「個人點擊」,都會降低用戶看到內容的多元性,但是臉書選擇強調這兩者比起「運算機制」扮演更重要的角色,似乎有些言過其實。他強調如果「臉書運算機制」的影響,和「社群組成」以及「個人點擊選擇」的個別影響相似,其實就已經是個嚴重問題。
- 此外,如果比較臉書用戶在不同情況下看到「交叉內容」的機率,對於立場偏保守派的民眾而言,「運算機制」(5%)的確比起「用戶選擇」(17%)的影響來得低,但是對於立場偏自由派的民眾而言,「運算機制」(8%)比起「用戶選擇」(6%)的影響來得高。因此臉書研究的總結並未真實反映結果。
- 學者們都指出,其實將「個人選擇」與「運算機制」做比較是非常不恰當且不合理的,因為兩者同時發生且存在明顯的回饋循環(feedback loop)關係。用戶個人做出的點擊選擇是基於臉書篩選後的結果,而臉書篩選的演算法則又是以用戶臉書使用紀錄為基準。更恰當的研究結果描述應該是,「個人選擇」和「運算機制」都會加強用戶的同質化資訊吸收。
- 澤奈普· 圖費克吉認為,早在網路普及之前,學者們就開始針對個人會透過選擇性暴露(selective exposure)來挑選立場一致的言論及避免相左立場觀點的現象,進行深入研究。但是臉書運算機制會造成資訊選擇單一化的現象,卻是很重要的新發現,也不該被忽略。且「個人選擇」與「運算機制」間更適合的描述應該是加成而非比較關係,而學者們也應該著重於此加成關係的深遠影響。
此外,學者們表示研究員在結論中指出這些結果反映臉書上的「常態」,卻忽略此篇「研究樣本的特殊性」。在個人檔案上註明政治立場的樣本條件並不尋常,這些用戶相較一般臉書觀眾,可能政治意識形態特別強烈鮮明,或是對政治特別熱衷且積極。這些樣本的特殊性也解釋為什麼此篇研究最後樣本數,只佔所有臉書用戶的極小比例。
而學者們也點出其他的潛在研究限制,包括「硬」新聞連結的政治立場,是由文章分享者的立場,而不是依據文章來源的政黨傾向,或文章內容分析來決定(不過研究發現,此種計算方式得到的結果,很接近大眾平常對這些新聞媒體的政治立場認知),以及臉書「運算機制」隨時都在改變的特性(延伸閱讀:臉書更改運算機制?掌握 5 個核心法則加上 15 個 Dos and Don’ts),也會降低該篇研究結果的通則性。臉書研究員在文章中也表示,他們對於接觸和點擊文章的定義並不完善,像是有些文章的重要結論已經摘要在動態牆上,用戶並不需要透過點擊就可以看見。
延伸想想:臉書研究的一堂課
當然,臉書願意進行研究並且公開分享成果的行為是值得鼓勵的,無論對於研究者、廣告商還是一般大眾來說,這些內部研究發現都可說是非常珍貴且重要,許多學者和廣告商們長久的疑問和猜測,也終於透過臉書的內部研究解開了部分謎團。
像是研究指出,對於少數會表明政治立場的臉書用戶,除了個人選擇(「好友組成」和「連結點擊」)外,臉書「運算機制」也被證實在某種程度上,會些微地降低用戶閱覽新聞的多樣性。平均來說,這些臉書用戶只會點閱臉書牆上不到一成的「硬」新聞(也就是超過九成的硬新聞連結都不會被用戶點擊),而政治立場越鮮明甚至極端的文章,被用戶分享的機率也更高。此外,動態牆上的新聞排列順序,也被證明確實會影響點閱機率且差異極大。
雖然臉書的研究成果提供非常多重要發現,只是,當商業公司提出學術發表時,也會被用更嚴格的眼光來審視,這也是為什麼學者們會提出諸多個人觀察和批判,希望幫助民眾更正確且深入地去解釋研究結果。
最後也不妨思考看看,是不是真的如臉書在研究最後總結,用戶個人(而非運算機制)該為臉書「過濾氣泡」現象負首要責任呢?
——————————————————————————–
- 註1:Perhaps unsurprisingly, we show that the composition of our social networks is the most important factor limiting the mix of content encountered in social media.
- 註2:Finally, we conclusively establish that on average in the context of Facebook, individual choices more than algorithms limit exposure to attitude-challenging content… Our work suggests that the power to expose oneself to perspectives from the other side in social media lies first and foremost with individuals. (請參考文章最後一段的首句與末句)
參考資料:
- [1] Praiser, E. (2011). The Filter Bubble: What the Internet is Hiding from You. New York, NY: The Penguin Press; Sunstein, C. (2007). Republic.com 2.0. Princeton, NJ: Princeton University Press.
- [2] Kwak, N., Williams, A. E., Wang, X., & Lee, H. (2005). Talking politics and engaging politics: An examination of the interactive relationships between structural features of political talk and discussion engagement.Communication Research, 32, 87-111; Mutz, D. C. (2002). The consequences of cross-cutting networks for political participation. American Journal of Political Science, 46, 838-55; Mutz, D. C., & Mondak, J. J. (2006). The workplace as a context for cross-cutting political discourse. The Journal of Politics, 68, 140-155; Stroud, N. J. (2010). Polarization and partisan selective exposure. Journal of Communication, 60, 556-576.
- [3] Bakshy, E., Messing, S., & Adamic, L. Exposure to ideologically diverse news and opinion on Facebook. Science. DOI: 10.1126/science.aaa1160.
- [4-1] The Facebook “It’s Not Our Fault” Study. Social Media Collective [MAY 7, 2015]
- [4-2] How Facebook’s Algorithm Suppresses Content Diversity (Modestly) and How the Newsfeed Rules Your Clicks. Medium
- [4-3]Did Facebook’s Big New Study Kill My Filter Bubble Thesis? Medium
——————————————————————————————————
本文轉載自新媒體世代 | What’s Next for New Media
新媒體世代是由一個大眾傳播博士班學生和另一個關心新媒體的夥伴