


作者:潘人豪助理教授,元智大學大數據與數位匯流創新中心
「人道援助」,乍聽這個詞,或許大家腦海中浮出的,是穿著白袍的醫生坐在簡陋環境裡義診,也可能是大批穿著制服協助難民撤逃的軍人們,又或者是寫著UN(United Nations)聯合國的白色四輪驅動越野車奔馳在災區中進行調查支援。有沒有曾經想像過,雲端計算、大數據應用,這樣的前端資通訊技術,也有可能應用在人道援助的場域中呢?
這幾年雲端技術、大數據應用的蓬勃發展,早已深入每一個人日常生活中,更不用說在各個商業領域的前端應用。然而在這樣全球火熱且全面關注的議題中,卻鮮少有人意識到,大數據也同時悄悄的應用到人道援助、國際合作領域中。
每當我們撥出一通電話、購買某個商品、使用社群媒體,甚至僅僅打開網頁瀏覽,都在不知不覺中產生大量資訊,加上自動化感測裝置的連續資料,無論是從政府單位或是私人企業產生儲存,這些無數的大數據資訊源與其交互組合可解釋的問題幾乎可以涵蓋各種議題,而當今的人道援助、國際合作機構,便是企圖利用各種大數據資訊或雲端計算科技,解決當下所面臨的問題,給予目標族群(vulnerable communities)更快速、有效的援助服務。
然而對於這樣的大數據、雲端服務應用,其實並不是近幾年大數據技術流行才有的,早在2007年,位於東非的肯亞(Kenya)共和國因為俱爭議總統大選後的全國性暴動,種族對立衝突造成超過一千三百人喪生與三十五萬人被迫離開家園躲避內亂。


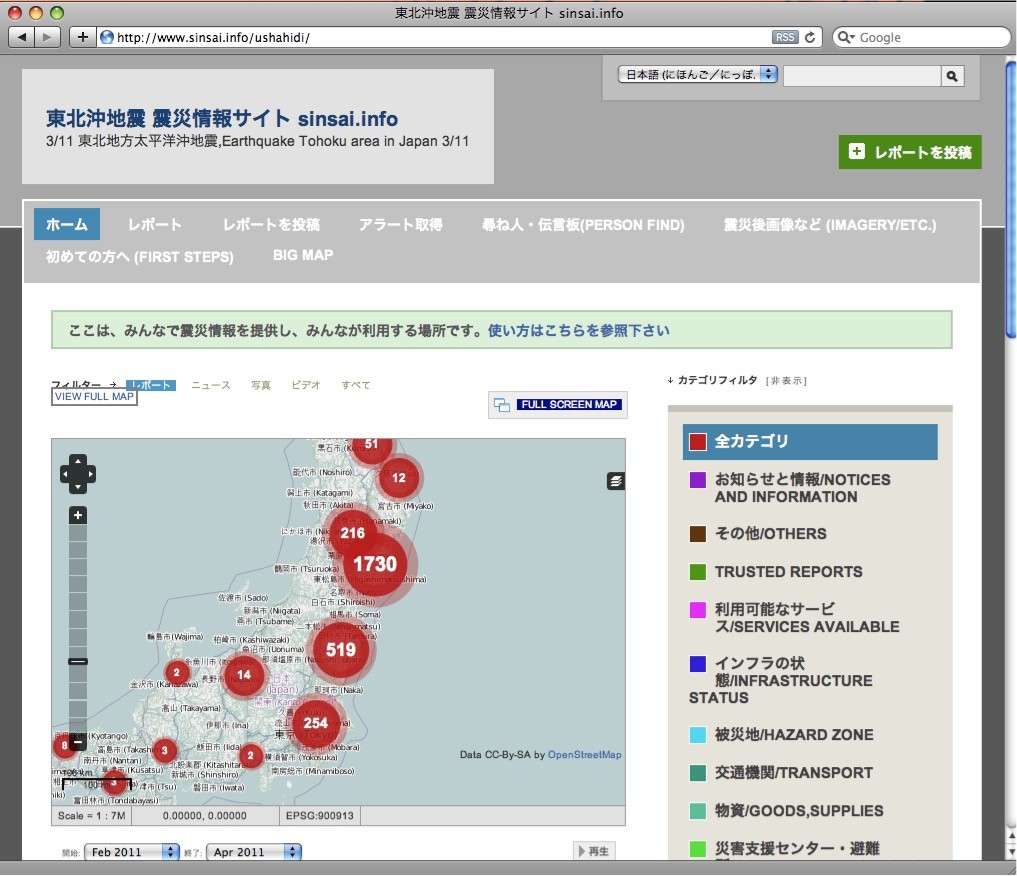
而在肯亞內亂當時,一群當地程式設計師與網路團體開發出名為Ushahidi計畫,Ushahidi為肯亞當地Swahili語言的證言(testimony)之意,Ushahidi計畫發展出一個網路平台,使用者可以透過手機SMS(Short Message Service)簡訊或網站進行暴力事件通報,隨後Ushahidi平台利用Google map進行地理位置標定,藉此跳脫國內媒體受控制或失去機能的狀態,直接由人民發聲向國際尋求援助,也因為Ushahidi的通報與傳播,國際組織得以快速動員進行人道援助救援與物資提供。
2008年後Ushahida計畫也擴展為國際人道援助平台,企圖提供全球進行事件通報與群眾標記(crowdmapping),並運用於諸多國家,如美國亞特蘭大(Atlanta)犯罪事件追蹤、印度(Republic of India)與墨西哥(United Mexican States)選舉結果的提報追蹤,甚至是2010年海地(Republic of Haiti)大地震與2011年日本東北大地震(2011 Tōhoku earthquake and tsunami)的事件追蹤標記。
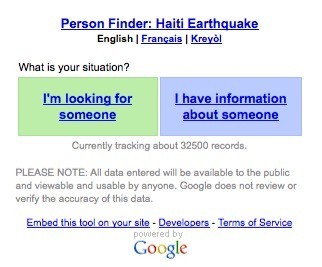
此外針對急難應用與災害救援事件,Google藉由其所擁有的計算資源,結合其自家Google App Engine分散計算引擎與儲存架構,以及Picasa 影像平台,於2010年時針對中美洲海地地震提出了Google Person Finder服務,針對災區進行災民尋找與通報服務;該服務後續亦提供之後2010智利(Chile)大地震、2011年日本東北大地震,甚至是前年(2013)於菲律賓造成嚴重災情的海燕颱風等災害救援。而Google Person Finder在2011年日本東北大地震期間曾創下高達六十萬姓名資訊紀錄的規模,堪為短時間內人道援助資訊蒐集彙整之成功案例。
(Image from : Wikipedia)
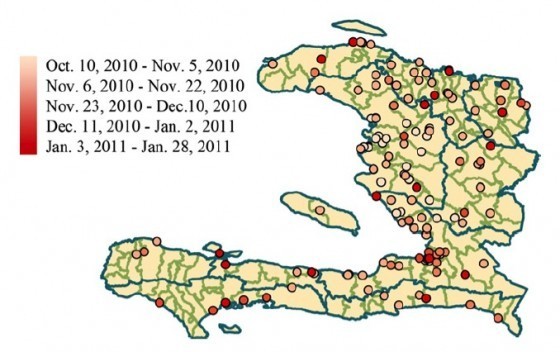
同樣透過大數據群眾標記進行人道救援案例,還有哈佛醫學院Rumi學者,透過社群媒體進行對傳染疾病傳播於地理位置擴散標定的流行病學研究,該研究發表於2012年American Journal of Tropical Medicine and Hygiene期刊,該作者透過自動網路媒體調查平台HealthMap,針對海地自2010年10月20號爆發霍亂(Cholera)疫情開始100天,紀錄由網路平台HealthMap、Twitter所產生之社群網路與關鍵字”Cholera”相關訊息,並透過訊息自動標定其地理位置,藉由時間推演與地理資訊標的,進一步對照海地政府公共衛生部(Ministère de la Santé Publique et de la Population, MSPP)提供之實際通報個案數據。
其結果發現網路數據的呈現與地理位置分布,符合MSPP所提供之事後通報個案資料分布與趨勢,證明透過社群媒體進行大數據資料探勘之方法,可以以低成本的方式進行傳染性疾病早期偵測,並達到快速反應與提早實施防疫策略之使用,針對醫療發展落後、醫療資訊蒐集傳遞機制不健全之國家 實為一個創新的應用。
(圖片來源 doi:10.4269/ajtmh.2012.11-0597)
發展中國家的公共衛生改善與發展,直接影響該國家人民的生存條件與健康條件,目前各國雖透過社群媒體大數據探勘技術企圖進行早期偵測,但如同文獻與相關報導中所提及,因為城鄉差異過大,資訊能力素養不齊,資料過度集中於高人口密度區域如首都太子港(Port-au-Prince)造成評估上的誤差與偏鄉地區的低估。


該區正爆發霍亂疫情病患擠滿霍亂隔離病房(因病患隱私,未拍攝內部照片)
上述之偏差狀況,由筆者近幾年數度至海地進行人道援助計畫時可得到驗證,今年七月筆者與桃園醫院國際衛生中心再度訪問海地北部Artibonite省之偏鄉Saint-Michel-de-l’Attalaye地區時,遭遇該區域爆發嚴重霍亂疫情,然而時隔2010初次爆發至今已將近三年之久,卻仍無法有效控制疫情散布,原因除了當地缺乏公共衛生工程礎建設、民眾公共衛生教育素養不足外,當地醫療機構僅使用紙本文件進行病患診斷紀錄,缺乏病患追蹤、主動式訊息通報機制,導致衛生單位無法立即獲取第一手疾病資訊以進行疫情防堵,亦是主要原因之一。
因此如何導入全國醫療資訊傳遞網路,由政府端建立真正醫療大數據平台,進行即時傳染性疾病事件通報、監控、追蹤機制,才是治標治本之道。

大數據小辭典:
- 群眾外包(crowdsourcing):此為《連線》(Wired)雜誌記者Jeff Howe於2006年發明的一個專業術語,用來描述一種新的商業模式透過網際網路上的使用者所組成的群體,進行創意的發想、工作執行與技術問題解決等。參與群眾外包成員,針對特定執行項目大多僅收取小額報酬或無償提供服務,因此建立了一種新的勞動結構。
- 群眾標記(crowdmapping):透過網際網路、行動裝置,群眾使用者可以於平台上標記任何虛擬化事件資訊,包含文字、影像、視訊多媒體、地理資訊、健康醫療紀錄等等,為群眾外包 (crowdsourcing)的延伸應用。常見的群眾標記服務多與地理資訊系統整合,提供具備地理位址之事件資訊。
- 社群網路(Social Network):是為一群擁有相同興趣與活動的人連結而成的線上社群。針對這類社群所提供的類服務往往是基於網際網路並為用戶提供各種聯繫、交流的互動通路,如電子信件、即時訊息服務或線上網路平台等。常見社群網路平台Facebook, Twitter, Plurk, Google+, LinkedIn, 人人網, 新浪微博, 騰訊微博, Instagram等等。
- 社群媒體資料探勘(Social Media Mining):社群媒體資料探勘是透過針對社群網物所產生的資料,所進行的資訊擷取、彙整、分析,企圖取得特殊目的、族群的目標模式,透過統計方法、機器學習、網站分析、網路科學等等不同領域的方法,進行對社群網路資料所產生的龐大數據資料尋找其有意義的應用資訊與現象。
- 社群網路分析 (Social Network Analysis):有別於社群媒體資料探勘,社群網路分析主要過社群網路上每個使用者與其彼此間的關聯性透過電腦科學中的圖學理論、網路理論,將社群網路的事件關聯轉化為圖學上的節點與線段連接,藉此便可以使用數據分析方法中針對圖學、網路關聯分析技術進行判斷,找出其中的群聚、分類、特殊事件與趨勢等標的。
想了解更多大數據知識,歡迎訂閱元智大學大數據匯流電子報




































-2-497x628.jpg)




