「從一種藥人人吃,到人人吃適合自己的藥!」Taiwan Biobank 助攻臺灣精準醫療
本文轉載自中央研究院研之有物 ,泛科學為宣傳推廣執行單位。
Taiwan Biobank 的重要性 每個人長期的健康狀況,皆是遺傳基因加上生活型態與環境因子長期綜合下來的結果。「臺灣人體生物資料庫」(Taiwan Biobank),期望透過結合生活習慣、環境因子、臨床醫學與生物標幟等資訊,建立屬於臺灣本土的人體資料庫,為國人量身打造「精準醫療」與「精準健康」的基礎。
從精準醫療到精準健康
為什麼有些人年紀輕輕沒有三高也會中風,卻也有人菸酒熬夜樣樣來卻不曾罹癌?你身邊一定也有些怎麼吃也吃不胖的朋友,或是號稱喝水也會胖的夥伴。每個人長期的健康狀況,皆是遺傳基因加上生活型態與環境因子互相綜合的結果。
2012 年成立至今的「臺灣人體生物資料庫 」(Taiwan Biobank),宗旨即期望透過結合生活習慣、環境因子、臨床醫學與生物標幟等資訊,建立屬於臺灣本土的人體資料庫。
Biobank 的基本價值會出現在「精準醫療」,或者是「精準健康」。
「所謂精準醫療,是說你生病了以後幫你治好;精準健康進一步做到預防,讓人盡量不要生病。」Taiwan Biobank 主持人李德章說明。
中研院生物醫學科學研究所李德章博士,同時也是臺灣人體生物資料庫主持人,說明臺灣人體生物資料庫最重要的願景即為促進國人的精準醫療與精準健康。 精準的關鍵:了解個別遺傳變異
精準醫療的重要面向:即透過對於基因、代謝的理解,個別化調整治療用藥。除了許多癌症的標靶藥物可經由基因型擇選治療方案,藥物在人體內的效應與代謝相關,受多基因調控影響,有極大的族群或是個體差異。
李德章舉出教科書的經典案例,白種人的血壓的常用有效藥物為 β 受體阻斷藥( ß-blockers)以及血管張力素轉換酶抑制劑(ACE inhibitors),而非洲裔卻需改採鈣離子通道抑制劑(calcium channel blockers)方可見效。2015 年發表的研究也指出,許多常用藥物實際只有少數比例的病患有反應,如精神用藥「千憂解」(Cymbalta、Duloxetine)僅有九分之一的患者可見效。
上一個世紀是一種藥所有人吃;因為精準醫療,二十一世紀的用藥就會變成每個人吃適合自己的藥物。
上圖為 2015 年美國常用藥物在病人身上實際發揮療效的比例示意圖:每當一人有效(藍色),仍有許多人無效(灰色)。精準醫療不只是針對症狀施以平均用藥,還能依照個體的情況用藥。Nature ) 除了影響用藥的效果,基因變異也與許多疾病的未來風險有很高的關聯。臺北榮民總醫院在 2020 年正式發表的研究,就發現了臺灣族群中特有的腦中風基因突變——在 NOTCH3 基因上的 R544C 突變,可能造成遺傳性的腦部小動脈血管病變,會增加 11 倍發生腦部小血管阻塞性中風的機會。由臺灣生物資料庫提供的背景資料,推估臺灣約近百分之一的人,即近 20 萬人帶有這個突變。
此外,臺灣 2010 年痛風的患病率為 6.24%,相對於世界平均 4%,是罹病率最高的國家之一。臺灣人痛風比例這麼高,究竟是受到哪些基因的影響?過去痛風遺傳研究主要以歐美族群為主,少見針對亞洲人的基因遺傳研究。近年來,研究人員終於可透過臺灣人體生物資料庫大量比對,破解與痛風相關的遺傳因素。
在人體生物資料庫中進行比對、確認族群的遺傳特徵,才能針對族群特性,對於生活方式提出調整建議,防範於未然,這就是「精準健康」的奧義。
老化臺灣,如何活得好?
特別是日趨人口老化的臺灣,精準健康的概念更形重要!衛生福利部 2018 年的統計,國人健康平均餘命達 72.3 歲,但不健康平均存活年數高達 8.4 年,許多人晚年長期慢性疾病纏身。如果未來能找到臺灣人癌症、阿茲海默症等慢性病的高風險族群,調整其生活型態,有助於延遲其發病時間、延緩病情進展。
有些疾病不太可能治癒,如阿茲海默症,可是如果這個病發生的時間能夠延遲個十年,對社會、對個人的影響就很巨大。
此外,如何調整生活型態,降低疾病的發生,也可以從人體資料庫找到答案。以運動改善肥胖來說,許多研究指出:基因遺傳與肥胖、代謝症候群有很強的關聯。那麼,藉由運動真的能夠協助控制體重嗎?
臺灣大學、國家衛生研究院及台北榮總研究團隊透過臺灣的數據指出,經由後天培養運動的習慣,可有效降低因為先天基因而造成的肥胖風險。研究甚至可更細緻回答到每個人最有效的運動種類,諸如慢跑、爬山、國標舞、健走及散步等等。
隨著臺灣人體資料庫逐步完善與逐年追蹤,更多有關臺灣國人健康的重要資訊可望逐漸挖掘出來。
我們的任務就是想辦法把它作出夠高品質的資料,讓大家很放心的去使用。
打造最高品質生物資料庫
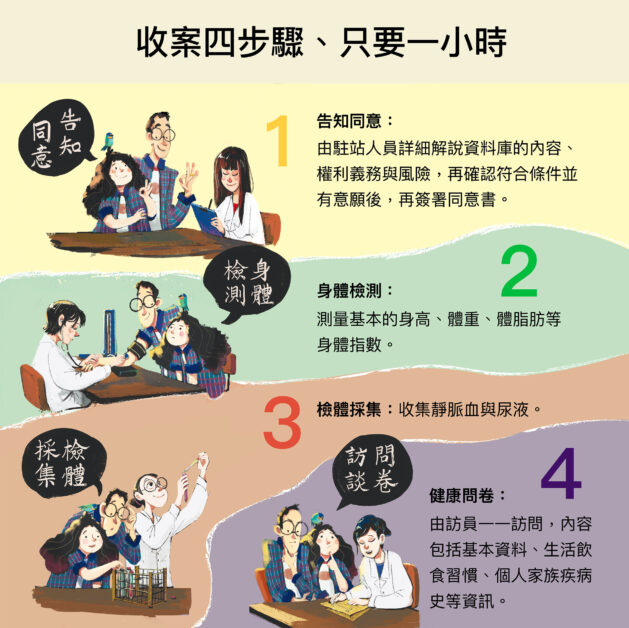
然而,這些夢幻研究均必須仰賴資料庫收集巨量、高品質的檢體。臺灣人體生物資料庫主要收集 20 歲以上具有臺灣國籍的自願參與者,總目標為 20 萬人,目前已經累積超過 14 萬人的資料,並完成 3 萬名第一次追蹤的資料。
以上是臺灣人體生物資料庫收集檢體的四步驟。「民眾可收到自己的檢查報告嗎?」答案是不會主動提供。因為資料庫收集資料以生物醫學研究為目的,不會主動提供檢測結果,但如果特別有要求,則會在兩個月內提供檢驗數據以茲參考。 收集到的檢體後續會經歷分裝、部分儲藏部分送檢、各種基本檢驗、送交抽取 DNA、進行基因定序 等工作。目前已經完成了 2000 位全基因體定序資料,由此開發專為國人設計的全基因體定型晶片 TWB2,並完成超過 10 萬名全基因體定型。到目前為止資料庫的數據總資料量已高達 1.5 PB,檢體儲存數量也已經超過三百萬管。
珍貴的檢體裝在冷凍管,部分儲存在攝氏零下 180 度液態氮冷凍桶中,檢體總數量已達三百萬管。 所有資料在進到資料庫之後就採去個資化管理,個資數位檔案以保密形式儲存於實體隔離機中。只有必要的時候才會在監督單位「倫理委員會」審核同意下,由第三方提供金鑰部分解密以取得必要資料,確保個資的隱密性。整體資料安全與隱私步驟,獲得德國評價協會 TUV NORD 個人隱私保護管理(ISO29100)與資訊安全管理系統驗證(ISO27001)兩項認證。
「這麼大量的收案量,最大的挑戰是什麼?」由於收案需要充分的說明、徵得受試者同意,挑戰在於「科普」,尤其是早期民間對於遺傳、基因的科學觀念不太普及,在收案階段說明就需要煞費苦心,還要使用臺語等民眾慣用的語言解說,對收案第一線人員就是個考驗。「早期到鄉鎮開說明會,一般民眾大多數不了解基因,不少人認為我們是詐騙集團哩!」但用心經營的成果,讓後續繼續響應追蹤的民眾日益增多。
臺灣人體生物資料庫收集案件需要充分的說明,並徵得受試者同意。 這些年辛苦收案、累積資料,也開始反應在研究發表上。截至 2021 年統計,已經結案的釋出檢體總數接近 20 萬管,釋出的資料超過 1 億人次。國際成果發表也逐年增加,截至 2020 年底已累計達 203 篇,2020 年更是大爆發國際發表達到 86 篇之多。
這是政府提供出來的,應該算是系統基礎建設,建設好以後就要盡量讓大家來用。
因為數位資料的特性,就在於累積越大使用越多,則其分析的成本效益越大。李德章初估資料庫完成 2021 件全基因體定序的成本約為 1.2 億元,而今數位釋出全基因體定序的資料已高達 16 萬人次,如果全數由使用者自行分析完成,其成本將高達近 99 億元,成本效率實際相當驚人。
臺灣生物資料庫 3.0,啟動!
生物資料庫現在的階段將從 Biobank 2.0 逐步轉為 3.0,重點在於怎麼讓資料庫永續,讓民眾感受到資料庫的貢獻。在達到品質與數據的累積之後,讓收集的資料可以作出回饋。因此接下來的重點目標,還包括跟國家高速網路與計算中心合作,讓研究人員可以在平台上便利進行分析的工作。現在臺灣生物資料庫網站已有提供一些公開資料 ,所有人都能夠進行查詢、了解國人的一些健康基本資訊統計,登入後更可獲得更多的資料。
達到質與量之後的 Biobank 3.0 ,重點是怎麼讓大家用、獲得回饋。
李德章表示,未來有機會,當然還希望可以在經費許可下,收集更多樣多元的資料。像是近期才加入採樣內容的糞便檢體、正在討論是不是可以加入穿戴裝備累積生活習慣的資料、有經費的話也希望能完成更多 DNA 甲基化的表觀遺傳學資訊,甚至於補充收羅新住民下一代的遺傳資料。
臺灣生物資料庫的這些累積,都將為臺灣精準醫療、精準健康的未來,奠定無以倫比的重要基石。
延伸閱讀