
- 作者|盧彥森,目前任職於 德國于利希研究中心 能源與氣候研究所
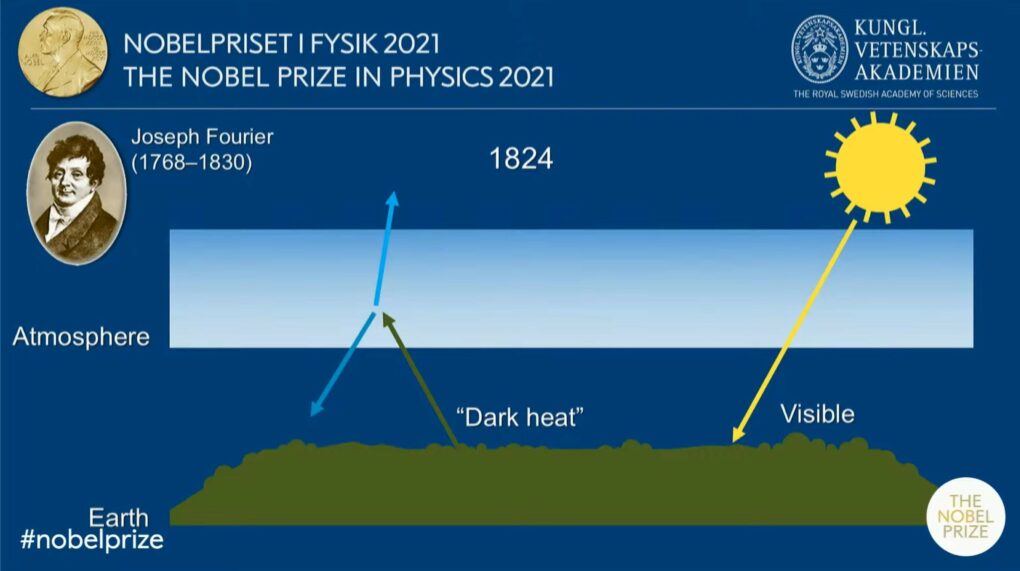
第一個地表模型的開發者——真鍋淑郎
在大氣科學領域中,有一部份專業領域統稱為「氣象模擬」,其中,有一門名為「地表模式」的領域,是專門算地表上各種物理、化學、生物作用的行為。
在做這些模擬的研究者中,有個很有名的日本名字,叫做 Manabe,他的論文會一直出現在大家眼前,也就是(只有我們在乎的)《 Manabe 1969, CLIMATE AND THE OCEAN CIRCULATION I : THE ATMOSPHERIC CIRCULATION AND THE HYDROLOGY OF THE EARTH’S SURFACE 》[1],最近因為大量的報導,我才知道原來他名字的漢字是——真鍋淑郎,也就是第一個地表模型的開發者,而在 2021 年時,他拿下了諾貝爾獎。

地表模式(Land Surface Model)在大氣模擬中有舉足輕重的地位,可以算地面是怎麼跟大氣作反應的,像是降水是怎麼被樹冠層截流、土壤水是怎麼變成地表逕流跟地下水、水是怎麼靠蒸散發回到大氣中;還有太陽光怎麼被地面或葉面吸收、能量怎麼被蒸散發作用給吸收、地面上的溫度增加或減少了多少,還有太陽輻射是有多少返回大氣層。
而真鍋淑郎的地表模式,則涵蓋了一大部份的物理反應,供美國國家海洋暨大氣總署(NOAA)的 Geophysical Fluid Dynamics Laboratory 的全球大氣模型使用。

不過學界是殘酷的。在那個電腦比房子貴的年代(房價在 1960 年的中位數約為$11,900,CNBC報導),真鍋順便背了個學界的鍋,像是:你的模型是不夠真實的、你的土壤濕度估算不夠物理……等因為電腦計算跟理論發展還不夠成熟,所以尚未發展的物理與計算方法。
後來的論文也會稱真鍋的地表模式是水桶模型(因為其計算土壤濕度的方法宛如水桶一樣,滿了就去除,而非經土壤中水流方法流走的)。但無論如何,第一個地表模型,基本上就是真鍋與他在普林斯頓的好夥伴們發展出來的。因此,真鍋的地表模型也在後來的論文中,尊稱為第一代的地表模式,建立起祖師爺等級的封號(Sellers et al., 1997)。
水桶模型後,百家爭鳴的地表模式大戰
雖然第一代的地表模式,土壤當做水桶,地上也沒有植物,更不要說可以進行光合作用或是碳排放來研究二氧化碳是怎麼搞壞我們的人生,但也讓後續的第二代地表模型有了出發點。
1980年後,在個人電腦逐漸普及後,地表模式也開始百家爭鳴,其中真鍋的身影也就只存在各家論文的引用中了。後來再出現時,則是在地表模式大戰——PILPS(Project for the Intercomparison of Land-surface Parametrization Schemes)[2]。這個計畫中,以水桶模型這個稱號出現。基本上始於 1995 年的 PILPS 計畫,就是利用荷蘭的 Cabauw 量測站測到的氣象狀況,來驗證各家第二代的地表模式中,誰才是最強的。

當然結果就是,沒有誰家最強。
更重要的是,雖然地表模式都比真鍋的模型更複雜了一點,但是有個東西是沒有人考慮到的:光合作用。
當時各家的蒸散發公式,主要都是用Jarvis的葉面氣孔參數化公式做考量[3],所以也沒有真的考慮到二氧化碳、水、太陽之間的直接關聯。而做出這個關連性主要公式——Farquhar等人[4] 的二氧化碳同化作用公式,才在 1980 年時正式發表,離他同事 Berry 拿去演化成植物氣孔跟光合作用的連動公式[5],還有七年。而在地表模型大戰中發表的模型,其實都長得 87% 像。
在 1997 年時,NASA 的 Sellers等人[6],與多位同樣是地表模式的作者與植物氣孔模擬專家,在《Science》期刊中,登高一呼:我們要有能夠計算生態跟複雜物理的模型!畢竟在 PILPS 的大戰中,沒有真正的勝者,也沒有真正的輸家,甚至我們的真鍋大哥在水文計算上也沒有輸[2]!
所以在 2003 年,集合了 PILPS 大戰中和解的部份朋友們,第一支集眾人之力誕生的通用地表模式(Common Land Model)上線了[7],這支從 1998 年開始寫的程式,過了近五年後才發表,算是第三代地表模式的代表作。
而這個第三代中,植物終於開始有了它的意義,這植物的葉子終於可以隨四季生長了,也會行光合作用了,土壤也增厚到兩公尺多了,土壤也會依不飽和水流公式往下滲流,也可以計算堆雪了。其中最重要的,就是那光合作用公式的應用。
持續再精進與貢獻
之後的地表模式,就一直著重在地面植物的改良,讓植物越來越真,從一開始的沒有植物,到會蒸發水,再到會跟二氧化碳互動,以及跟氮交互作用,計算植物的農作產出,一步步朝著更精細的方向前進。
當然地表模式也有很多需要改良的地方,首先是地表模型是假設地表跟大氣是一維方向的互動,而土壤中水流也是只會向下滲流,如果要計算真正的水流,就必須要進行三維的地下水流動,這就是另外一個耗資源的計算。另外植物也不是真的植物,植物被假設只有四片葉子,還只有一層。
英國的「JULES」模型曾報告說他們做了個多層葉冠層的模型,最後只能淡淡的說因為計算資源耗太兇,所以沒算完 [8]。更甚者,地底下的根是「死」的,一年四季,不生不滅、不垢不淨,持續地在只有兩公尺厚的土裡,把水吸到植物中行光合作用(Pitman, 2003)[9]。
所以無論如何,地表模型不僅不死,其勢更烈,因為有太多的東西可以靠地表模式來計算,像是人類對地球表面的影響、化合物排放,也都可以靠地表模式計算其對大氣的影響,就連地下水模型也都要拜託地表模式處理複雜的地表水文狀況[10]。
從 1969 年到 2021 年,無數的改良與改版,還有兩次的超級地表模式大戰(第二次利用 Rhône 流域量測結果[11]),都增加了人們對大氣系統的了解,並且一步步改善天氣預報的準確度,而其中的功臣之一,當然是真鍋博士在 1969 年,比 Unix 更早發表的地式模型,所以的確功不可沒,而現在地球科學的眾多估算中,地表模式解決了很多的水文與能量問題,更遑論對氣候變遷的計算,才能在1975年提出二氧化碳加劇溫度上升的研究[12]。拿下諾貝爾獎,不僅僅是贊同真鍋博士的功勞,更是對大氣模擬界的慰勞吧。
參考資料
- Manabe S. (1969). CLIMATE AND THE OCEAN CIRCULATION 1: I. THE ATMOSPHERIC CIRCULATION AND THE HYDROLOGY OF THE EARTH’S SURFACE. Mon. Weather Rev. 97:739–774.
- Pitman, A. J., Henderson-Sellers, A., Desborough, C. E., Yang, Z. L., Abramopoulos, F., Boone, A., … & Xue, Y. (1999). Key results and implications from phase 1 (c) of the Project for Intercomparison of Land-surface Parametrization Schemes. Climate Dynamics, 15(9), 673-684.
- Jarvis PG. (1976). The Interpretation of the Variations in Leaf Water Potential and Stomatal Conductance Found in Canopies in the Field. Philos. Trans. R. Soc. Lond. B Biol. Sci. 273:593–610.
- Farquhar, G. D., von Caemmerer, S. V., & Berry, J. A. (1980). A biochemical model of photosynthetic CO 2 assimilation in leaves of C 3 species. Planta, 149(1), 78-90.
- Ball JT., Woodrow IE., Berry JA. (1987). A model predicting stomatal conductance and its contribution to the control of photosynthesis under different environmental conditions. In: Progress in photosynthesis research. Springer, 221–224.
- Sellers PJ., Dickinson RE., Randall DA., Betts AK., Hall FG., Berry JA., Collatz GJ., Denning AS., Mooney HA., Nobre CA., Sato N., Field CB., Henderson-Sellers A. (1997). Modeling the Exchanges of Energy, Water, and Carbon Between Continents and the Atmosphere. Science 275:502–509
- Dai Y., Zeng X., Dickinson RE., Baker I., Bonan GB., Bosilovich MG., Denning AS., Dirmeyer PA., Houser PR., Niu G. (2003). The common land model. Bull. Am. Meteorol. Soc. 84.
- Best MJ., Pryor M., Clark DB., Rooney GG., Essery RLH., Ménard CB., Edwards JM., Hendry MA., Porson A., Gedney N., Mercado LM., Sitch S., Blyth E., Boucher O., Cox PM., Grimmond CSB., Harding RJ. (2011). The Joint UK Land Environment Simulator (JULES), model description – Part 1: Energy and water fluxes. Geosci Model Dev 4:677–699
- Pitman AJ. (2003). The evolution of, and revolution in, land surface schemes designed for climate models. Int J Clim. 23:479–510.
- Kollet SJ., Maxwell RM. (2006). Integrated surface-groundwater flow modeling: A free-surface overland flow boundary condition in a parallel groundwater flow model. 29:945–958.
- Boone A., Habets F., Noilhan J., Clark D., Dirmeyer P., Fox S., Gusev Y., Haddeland I., Koster R., Lohmann D. 2004. The Rhone-Aggregation land surface scheme intercomparison project: An overview. J. Clim. 17:187–208.
- Manabe, S., & Wetherald, R. T. (1975). The effects of doubling the CO2 concentration on the climate of a general circulation model. Journal of Atmospheric Sciences, 32(1), 3-15.





































{kind=link}