


- 作者/甘魯生 教授
2017 年 7 月在物理的研究與發現上有了重大的進展: 由台裔教授王康隆博士領軍的 UCLA 研究團隊,偵測到了馬約拉納費米子(Majorana Fermion)。解答了物理 80 年來的一個懸念,證實了一個匪夷所思的觀念,給將來可能的應用帶來了無窮的遐思和希望。王康隆教授表示:
「最重要的就是推進量子電腦的發展,現在有的電腦是線性、序列性的計算,但量子電腦是可以同步執行,因此又稱為『糾纏式的演算法』,所以計算速度會更快!」[註一]
那是一個什麼觀念呢?我們必須把時空拉回 89 年前起。1928 年英國理論物理學家保羅.狄拉克(Paul Dirac)(1933 年諾貝爾物理獎得主)利用 Dirac formula 成功解釋了費米子的性質,並預測有反物質的存在。在宇宙之中物質—反物質會一對對存在且物質和反物質的特性是一模一樣唯一的差別只有電荷是相反的。比如說:電子是物質,帶有一個負電荷;那麼它的反物質就帶一個正電荷。果不其然卡爾.戴維.安德森 (Carl David Anderson) 在 1932 年發現了正子,之後很多夸克的反物質陸續也被發現。這一觀念很快被人們所接受並牢牢記住:正和反物質必須由二個粒子才算完整。
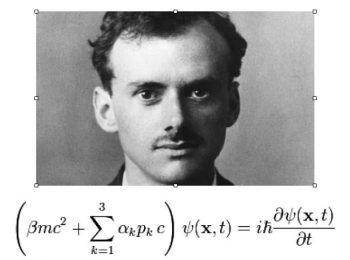
埃托雷.馬約拉納(Ettore Majorana )是一位義大利的理論物理學家,他在 1937 年預測了有一種費米粒子是正反粒子的合體,它不含電荷,被稱為「馬約拉納費米子」。截至上個月為止,馬約拉納費米子(即正反物質在同一粒子上),這想法仍未獲得實驗上的驗證。然而在 2017 年 7 月 20 日美國科學(Science)刊登了王康隆教授及其研究團隊研究成果,解決了馬約拉納費米子在基礎物理學延續 80 年來一大問題並提出了在應用上的價值。

近來,許多報導沸沸揚揚的討論著這項物理學上的突破及成就能不能得諾貝爾物理獎?王康隆教授說:「從來沒想過!我是做科學研究的人,而做科學的人不會想這個問題,想的只有好好把實驗做好。我認為諾貝爾物理獎是一個機遇,每天想拿獎不好,就不是一個做學問的態度了!就不是為了做物理,而是為了得獎去做!」[註二]
王康隆教授上面的一席話,表現出學者該有的高度與看法:「不為獎而獎,但能得獎也不必太謙虛!」回過頭來看看與基本粒子有關的諾貝爾物理獎歷史,
- 發現電子的約瑟夫.湯姆森(Joseph John Thomsom)得到了1906年諾貝爾物理獎。
- 發現上述正子的卡爾.戴維.安德森( Carl David Anderson) 得到了 1936 年諾貝爾物理獎。
- 預言有介子存在的湯川秀樹得到 1949 年諾貝爾物理獎。
- 發現 J 粒子的丁肇中得到 1976 年諾貝爾物理獎。
- 這世紀以來還有預言三大類夸克(three families of quarks)的小林誠和益川敏英得到了 2008 年諾貝爾物理獎。
- 2015 年瑞典皇家將諾貝爾物理獎証明微中子(Neutrino)有質量(因為它能震盪)的梶田隆章。
以上林林總總的獲獎紀錄可見基本粒子的預測和證實簡直就是諾貝爾物理獎的加工廠嘛!那麼預言有馬約拉納費米子的埃托雷.馬約拉納(Ettore Majorana)有沒有得獎?答案是:沒有!

埃托雷.馬約拉納(Ettore Majorana)這位被恩里科.費米(Enrico Fermi )讚許和伽利略和牛頓同級的天才人物竟然沒得諾貝爾獎?這必須要話說從頭,首先埃托雷.馬約拉納(Ettore Majorana)在 1937 年出版的論文[1],是以義大利文寫的研究論文。語言的問題,對於論文的傳播有很大的影響;另外一個意想不到的事,他在 1938 年 3 月在一次乘船旅行途中神秘失蹤了!雖有各種猜想他到那去了,但至今無解。當時他才 32 歲(1906-1938)。儘管他生命短促,但仍有得諾貝爾的機會。
1932 年伊雷娜.約里奧.居禮(Irène Joliot-Curie)和弗雷德里克.約里奧.居禮(Frédéric Joliot)發現一未知的粒子存在,但他們解釋為伽瑪射線。因為在高能物理中質和能可以互相轉換;但馬約拉納認為是一中性而且質量和質子相近的粒子才能解釋 Irène Joliot-Curie 和 Frédéric Joliot 的結果。這粒子就是後來被稱為中子的粒子。當時,費米要馬約拉納趕快將他的解釋寫成論文,但馬約拉納卻不想這麼做。反倒被詹姆斯.查兌克(James Chadwick)接手並證實為真,因此詹姆斯.查兌克得到了 1935年諾貝爾物理獎。所以說人的命運是性格的產物!
理論學家利用豐富的知識和嚴謹的邏輯做出驚世的推論固然是一件了不得的成就,但真實與否須實驗的驗証!王康隆教授的實驗設計是將一片超導體和一片磁性拓樸絕緣體(magnetic topological insulator)結合在一起;並在在二片之間加入磁性物質,並放入可變動的磁場中,變動的磁場使得電子在超導二側呈相反方向運動,電子流動速度變慢或停止,也可改變方向。
透過可變動磁場的掃描,王康隆教授的團隊觀察到馬約拉納費米子特殊的量子訊號出現,証實了馬約拉納費米子的存在。看來非常簡單的實驗,但做起來非常艱幸。最困難的部分就是生長單晶層材料和在低溫高磁場下測量數據。再聽聽王康隆教授怎麼說:「這次發現馬約拉納費米子的過程中最困難的就是單晶層的生長!我們用了十幾年的時間從事於分子束磊晶的工作(molecular beam epitaxy),把這個材料優化到現在的程度才有辦法做這個實驗。其他還有困難的地方就是得到這材料測試之後如何分析?材料上分析也是很重要的過程,我們花了很多時間才把結果分析出來。」[註三]
十多年嘔心瀝血的研究,現終有所成。

參考資料
- E. Majorana, Teoria simmetrica dell’elettrone e del positrone. Nuovo Cim. 14, 171–184 (1937)
- 註一:王康隆:「論文定案,我和學生花了近一年」
- 註二:參與學者王康隆:亦陽亦陰叫「太極粒子」更貼切
- 註三:私人通訊

本文摘自《物理雙月刊》39 卷 8 月號 ,更多文章請見物理雙月刊網站。





































{kind=link}