- 作者:王浤齡、陳玟蓉、高珮珊/台北市立大同高級中學
「數感盃青少年寫作競賽」提供國中、高中職學生在培養數學素養後,一個絕佳的發揮舞台。本競賽鼓勵學生跨領域學習,運用數學知識,培養及展現邏輯思考與文字撰寫的能力,盼提升臺灣青少年科普寫作的風氣以及對數學的興趣。
本文為 2021 數感盃青少年寫作競賽/高中組專題報導類佳作之作品,為盡量完整呈現學生之作品樣貌,本文除首圖及標點符號、錯字之外並未進行其他大幅度編修。
在拍照時,我們總是希望能夠自然地呈現出最漂亮的自己,但這是一件何其困難的事情。法國傳奇攝影師——羅伯特・杜瓦諾曾說:「如果我知道如何拍出好照片,那我每次都會拍出好照片了。」然而有沒有什麼拍攝方法,可以讓照片中的身材比例變得更完美呢?
有一天,我和一群朋友到某間知名服飾店逛街,試穿今年流行的秋冬款,並拍照片比較看看,選出較適合自己的衣服。在過程中,我發現一個問題:「為什麼在店家試穿時,全身鏡映照出的自己總是比照片中好看?」
嘗試幾次後,我們發現這是因為自己的身材比例,在鏡子與照片中的呈現是不一樣的,服飾店內的全身鏡,總是使腿的比例看起來比較長。

於是我們開始好奇,拍照時要如何拍攝出如同店裡的全身鏡具有長腿效果的方法,以及,是什麼原因讓這間服飾店內的全身鏡會有這樣長腿的效果呢?
上網搜尋之後,發現在這個社群軟體發達的時代,網路上有許多人分享不用俢圖軟體,就能「拍」出完美比例的文章或是教學影片,其結論是:「把手機或相機傾斜一個角度,就可以讓人的腿在照片中的比例變長。」然而,所謂的「傾斜一個角度」到底是幾度,卻沒有網站提供。
事實上,每個人身高比例皆不相同,取景的遠近都不一樣,甚至使用的拍攝器材也不 盡相同,使這個「角度」也會因情況而有所不同。因此,我們試著用所學的數學工具,去推論出不同人在拍照時,手機應該要傾斜幾度才能達到想要的長腿效果?
關於服飾店內全身鏡有長腿效果的原因,我在觀察這些鏡子後,發現它們都有傾斜(如圖一),而且與地面都是夾 80 度。這個傾斜角度到底有什麼樣的用意呢?我們試圖去解開這個業界沒有說出來的秘密。

首先,我們先解釋物理上的「成像原理」。人的眼睛之所以能看到物體、相機可以拍到畫面,都是因為物體反射的光線,進入到眼睛內的視網膜、或是相機裡的底片後所成的「像」。
成像的原理與國中理化所教的凸透鏡成像原理相同,是由三條光線所交會而成的像(圖二),其中平行光通過透鏡後會穿過焦點,而穿過焦點的光通過透鏡後會成為平行光,交會處就是成像地點;並且第三條穿過透鏡的直線光也會與前兩條相交,因此可以由物距與像距算出成像縮放的倍率。
如果我們在成像位置放一個平面,當成像的平面與物體是平行時,像會與實物相似,但是上下顛倒;但是如果把成像平面傾斜一個角度的話,成像的比例就會因為傾斜的角度,而 與實物的原比例不同。
我們想要研究相機傾斜角度對照片中人物的身材比例的影響。
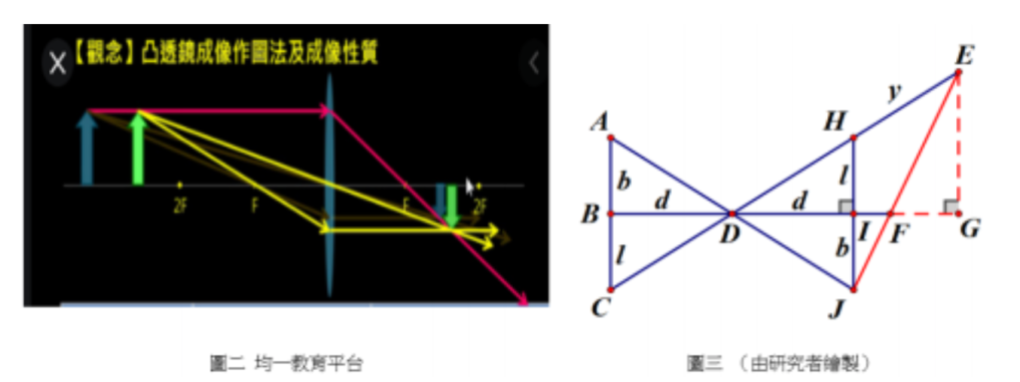
考慮拍攝時,相機高度與被拍攝者的肚臍位置相同,如上面圖三所示,點 D 為相機的焦點,物體反射的光線直線穿過 D點,在另一側的平面上呈現一個倒立的像。
把 \( \overline{AC} \) 當成為一位站立著的被拍攝者, \( \overline{AB} \) =b 為被拍攝者的頭頂到肚臍的長度,即為身長;而 \( \overline{BC} \) =l 為被拍攝者的肚臍到腳底的長度,即為腿長; \( \overline{BD} \) =d 為被拍攝者與相機的距離。
當成像平面垂直地面時,若把像距等比例放大到等於物距時(即是 \( \overline{DI} \) =d ),則 \( \overline{HJ} \) 會是一個全等的倒立像,即 \( \overline{HI} \) =l 為像的腿長、 \( \overline{IJ} \) =b 為像的身長。
若把成像平面傾斜一個角度,轉成 \( \overline{EJ} \) , 則像的身長會被拉成 \( \overline{IJ} \) → \( \overline{FJ} \) ,像的腿長會被拉成 \( \overline{IH} \) → \( \overline{FE} \) 。
接下來,我們將推導出一條公式,可以算出相機該傾斜幾度,才能讓被拍攝者的身長及腿長呈現我們所想要的比例。
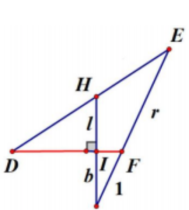
假設在照片中,身長比腿長的比例為 \( \overline{FJ} \) : \( \overline{EF} \) =1 : r,先求出 \( \overline{HD} \) : \( \overline{HE} \) 。
如圖四,我們利用「孟氏定理」, ΔJEH 被直線 \( \overline{FD} \) 所截的線段比為
\( \frac{\overline{JI}}{\overline{IH}} \) ✕ \( \frac{\overline{HD}}{\overline{DE}} \) ✕ \( \frac{\overline{EF}}{\overline{FJ}} \) =1 \( \Rightarrow \) \( \frac{b}{l} \) ✕ \( \frac{\overline{HD}}{\overline{DE}} \) ✕ \( \frac{r}{1} \) =1,則 \( \frac{\overline{HD}}{\overline{DE}} \) = \( \frac{l}{br} \) 。
又因為圖三中, \( \overline{IH} \) // \( \overline{EG} \) ,所以 \( \frac{l}{br} \) = \( \frac{\overline{HD}}{\overline{DE}} \) = \( \frac{\overline{DI}}{\overline{DG}} \) = \( \frac{d}{\overline{DG}} \) \( \Rightarrow \) \( \overline{DG} \) = \( \frac{bdr}{l} \)
\( \overline{IG} \) = \( \overline{DG} \) – \( \overline{DI} \) = \( \frac{bdr}{l} \) -d
因為 ΔEFG ≈ ΔJFI,所以 \( \frac{\overline{IF}}{\overline{FG}} \) = \( \frac{\overline{FJ}}{\overline{EF}} \) = \( \frac{1}{r} \) ;可推得:
\( \overline{IF} \) = \( \frac{1}{(1+r)} \) ✕ \( \overline{IG} \) = \( \frac{1}{(1+r)} \) ✕ \( \left ( \frac{bdr}{l}-d \right ) \)
因此,若相機傾斜的斜率為 m,則
\( m=\frac{\overline{IJ}}{\overline{IF}}=\frac{b}{\frac{1}{(1+r)}\left ( \frac{bdr}{l}-d \right )}=\frac{(1+r)lb}{rbd-ld} \)
從這個公式可知,我們只要知道以下數據,代入公式之中即可算出相機的斜率:

若圖中 \( \overline{AJ} \) 的斜率與 \( \overline{CH} \) (原文使用的是雙箭頭線段符號,但公式表中找不到,所以就先以線段符號代替)的斜率分別令成 mb 與 ml ,則相機傾斜的斜率公式可用斜率簡化表示為
\( m=\frac{(1+r)m_{b}m_{l}}{rm_{b}+m_{l}} \)
我們根據此公式進行以下實作。
拍攝工具為 iPhone 手機,被拍攝同學的身體數據如下表一:

我們設定畫面高度與人物身高的比例黃金比例(約為 1:0.618),而由〈物距計算器〉網站,可算出此畫面下的拍攝距離為 144.7 公分。並且,我們希望拍攝出的身長與腿長也是黃金比 例,即 \( r=\frac{1}{0.618}=1.618 \)。
由表一,因為 mb = -身高 / 物距 = \( \frac{-67.5}{144.7} \),ml = 腿長 / 物距 = \( \frac{95.5}{144.7} \),所以帶入公式可得:
\( m=\frac{(1+1.618)\times \left ( \frac{-67.5}{144.7} \right )\times \left ( \frac{95.5}{144.7} \right )}{1.618\times \left ( \frac{-67.5}{144.7} \right )+\left ( \frac{95.5}{144.7} \right )}\approx 8.538 \)
因此,拍攝時手機傾斜的斜率約為 8.538,換算成角度:
\( 8.538=tan\theta \Rightarrow tan^{-1}(8.538)\approx 83.3^{\circ} \)
所以手機在拍攝這位同學時應該要傾斜 83.3°。
下圖是手機傾斜前後拍照出來的照片效果對比:

從右圖看得出來,照片中的腿部確實有拉長的效果,其比例為 1 : 1.84,但並非是當初我們給 定的黃金比例。這個原因是來自於 iPhone 手機鏡頭視角的限制,當手機傾斜時,放在腰部的高度,被拍者會無法全身入鏡。所以,我們將手機高度降低至能夠完全拍攝到整個人,因而導致加大拉長效果。
因此,我們建議在拍攝時,若需要降低手機高度,則手機與地面夾角,要比原計算出來的角度更接近 90° 一點。
接下來,我們利用研究的結果去計算,各個年齡層與性別的人在拍照時,身長與腿長在照片中要呈現黃金比例,手機適當的傾斜角度分別為幾度。
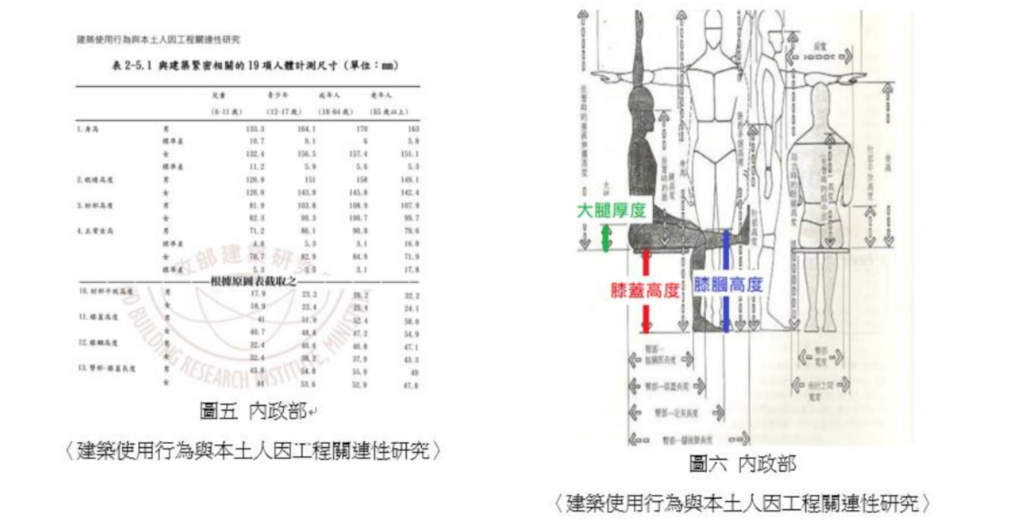
下圖五,是內政部〈建築使用行為與本土人因工程關連性研究〉指出的 19 項人體計測尺寸中的部份數據;而下圖六,則是將圖表的數據進行以下的計算,去推論一般人平均的身長與腿長。
- 膝蓋高度 − 膝膕高度 = 大腿厚度
- 坐高 − 大腿厚度 = 身長(頭頂到肚臍)
- 身高 − 身長 = 腿長
把各個年齡層與性別的平均身長與腿長整理成下表二。最後,我們各別將數據代入公式計算得出,不同人在拍照時,手機的傾斜角度,如下表三所示。
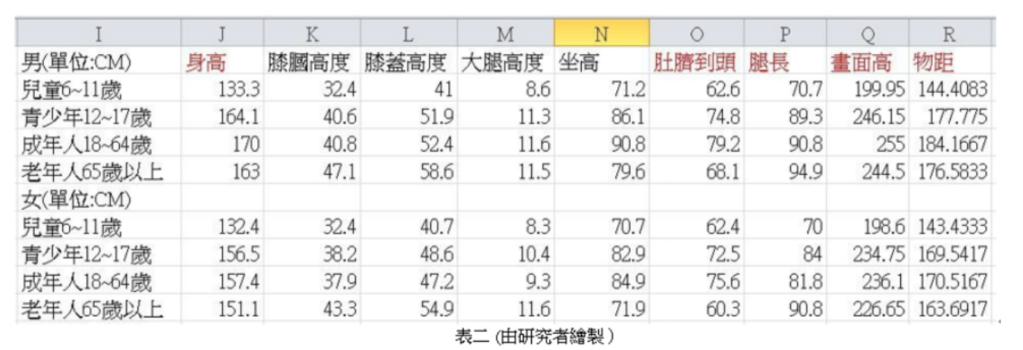
表格三中,65 歲以上的民眾要拍出黃金比例的手機角度比較垂直,是因為數據的統計有將駝背也考慮進去,導致統計出的結果,相對其它年齡層來說腿的比例較長。但普遍來說, 在未滿 65 歲的各個年齡層拍照時,手機傾斜角度分布在 65 ~ 70° 之間。

然而,考慮到手機傾斜時又要全身入鏡,需要降低手機拍攝的高度,會更加拉大腿長的比例,因此,一般人在拍照時,若想讓身長比腿長接近黃金比例的話,我們建議:
手機與地面的夾角以「70°」為最佳。
服飾業內不能說的秘密,全身鏡傾斜 80° 的原因!
在前文中,我們想探討第二個問題,是服飾店的全身鏡為什麼都與地面夾 80°。其斜置的原因,明顯是要讓腿看起比較長,但為何不用其它的角度而恰好是 80° 呢?
斜鏡面會產生仰視效果,讓人感覺鏡中的人像向後仰,使腿的視覺效果變長。事實上, 長腿效果與我們研究的主題一致,同樣是實物(鏡中後仰的人像)與成像平面(視網膜)不平行,因此後仰角度與視覺比例的關係,符合前文推論的公式。
如下圖七所示,全身鏡傾斜 80° 後,由於鏡子和直立的人夾角 O 為 10°,因為鏡射原理,鏡子和像的夾角也為為10°, 所以像會傾斜 70°,且 ∠ACD = ∠AOB = 10° 。
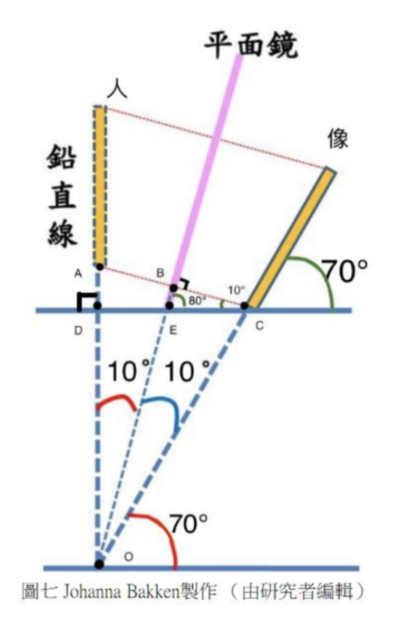
實際到店家測量全身鏡前的走道寬度,約為 78 公分。也就是一般民眾會站在距離約 78 公分的位置使用全身鏡,即 \( \overline{DE} \) = 78,則
78+ \( \overline{EC} \) = \( \overline{DC} \) = \( \overline{AC} \) cos(10º)
\( \Rightarrow \) 78+ \( \overline{EC} \) = 2 \( \overline{BC} \) cos(10º)
\( \Rightarrow \) 78+ \( \overline{EC} \) = 2 \( \overline{EC} \) cos(10º)
因此,可以算出 \( \overline{EC}=\frac{78}{2cos^{2}(10^{\circ})-1}\approx 83 \)
所以當我們照鏡子時,眼睛與成像的距離為 78+83=161 公分。若成年女性(平均身長 75.6 公分、 腿長 81.8 公分)使用服飾店的全身鏡時,看到鏡中自己的比例(腿長 / 身長)為 r,則
\( \frac{(1+r)\times \left ( -\frac{75.6}{161} \right )\times \left ( \frac{81.8}{161} \right )}{r\times \left ( -\frac{75.6}{161} \right )+\left ( \frac{81.8}{161} \right )}=tan(70^{\circ})\approx 2.747 \)
\( \Rightarrow \) r ✕ [(-0.4696) ✕ 0.5081+2.747 ✕ 0.4696] = 0.4696 ✕ 0.5081 + 2.747 ✕ 0.5081
\( \Rightarrow r=\frac{0.4696\times 0.5081 + 2.747\times 0.5081}{ [(-0.4696)\times 0.5081+2.747\times 0.4696] }=\frac{1.63435446}{1.0.5138744}\approx 1.565 \)
這個結果非常接近黃金比例。
用其它年齡層與性別的數據去計算,也可得到 r ≈ 1.618 ± 0.05
因此,我們發現服飾店會在店內全身鏡會斜置 80° 的原因,很可能是因為要讓顧客認為穿上自家的衣服後,會讓比例接近於黃金比例,以提升購買慾望。
結合我們計算的數據和實作的結果,可以得出一些結論:大多數的人拍攝時,如果想要拍出身體的比例接近黃金比例,手機需要傾斜的角度大約為 65° ~ 70°。若將傾斜時,可能會把手機高度降低的因素考慮進去,則是以 70° 為最佳角度。
下次拍照時,不妨也將手機傾斜成 70°,或許會有意想不到的效果!
參考資料