本文轉載自中央研究院「研之有物」,為「中研院廣告」
迎接我們的是什麼樣的未來? 想像 30 年後,生活將發生什麼改變?行政院國家發展委員會於 2022 年 3 月 30 日公布「臺灣 2050 淨零排放路徑及策略」,針對能源、產業、生活與社會轉型提出多項政策,倡導人們逐步展開淨零新生活。中央研究院「研之有物」專訪《臺灣淨零科技研發政策建議書》諮詢委員──中研院經濟研究所蕭代基兼任研究員、臺灣大學國家發展研究所周桂田教授,從與生活最貼近的經濟及社會政策出發,深入剖析臺灣如何在淨零路徑上穩健前行。迎接我們的是什麼樣的未來?一起來關心!
時間來到 2050 年,一覺醒來,生活將發生什麼改變?望向窗外,鄰居的屋頂架設了太陽能板,馬路上一輛輛電動車川流不息。打開衣櫃,穿上隨租隨送的流行服飾。走進早餐店,煎台上的人造雞肉散發迷人香氣。打卡進辦公室,充滿朝氣的一天在高強度木竹構造大樓展開,固碳的木竹建材來自永續經營的森林。
上述情景啟發自行政院國家發展委員會的「淨零生活藍圖」,究竟什麼是「淨零」(Net zero)?推動的原因為何?又將對我們的生活產生什麼影響?
淨零風潮席捲全球,臺灣該如何因應挑戰? 在解開「淨零」謎團之前,我們先來看看聯合國政府間氣候變化專門委員會(IPCC)在 2018 年公布的全球暖化特別報告,當中預測 2030 年左右,地球表面均溫將比工業革命前高出 1.5℃。
如不在 2030 年前有效減碳、發展生質能源與除碳技術,並在 2050 年左右達到「淨零排放」,將引發更劇烈的極端氣候、糧食與水資源短缺、海平面上升等危機,嚴重威脅全人類與自然萬物的生存。
「淨零排放」指的是,在特定時間內,人為產生的溫室氣體(主要為二氧化碳)排放量,與人為移除量相互抵消,達到「淨零」目標。
為此,全球掀起一股淨零風潮,其中以 1994 年生效、多達 197 個締約國的「聯合國氣候變化綱要公約」(UNFCCC)最具指標性,各國領袖定期出席氣候變遷大會,做出減碳承諾,簽定了「京都議定書」、「巴黎協定」等重要協議。
臺灣雖然不是聯合國會員,也無法置身事外,隨著各國紛紛祭出碳邊境稅、綠色供應鏈等政策,出口導向的臺灣必須盡快做出應變。
另一個棘手問題是,臺灣的慣用能源、主要產業多偏向高碳排、高耗能、高汙染性質,養成高度碳鎖定的褐色經濟體質 。產出的低附加價值商品,使勞工的薪資水準難以提升,生產過程造成的環境汙染更會損害人民健康。
淨零轉型政策有助挽救瀕臨崩潰的地球環境,更是臺灣百年難得一遇的經濟綠色轉型契機!
2022 年 3 月 30 日,在眾人的期盼下,行政院國家發展委員會公布了「臺灣 2050 淨零排放路徑及策略 」,預計在 2030 年前編列約 9 千億預算,執行能源、產業、生活、社會四大轉型策略,以及科技研發、氣候法制兩大治理基礎,並輔以十二項關鍵戰略,計畫於 2050 年與世界同步邁向淨零目標。
然而,比較可惜的是,當中並沒有納入「碳定價」制度,也沒有針對「社會公正轉型」提出細緻的規劃,這些都是推動產業轉型、兼顧民眾權益的重要政策。
有鑑於此,中央研究院召集各界專家研擬《臺灣淨零科技研發政策建議書》,其中〈經濟與社會促成因素〉一章由多位經濟與社會學者集思廣益而成。
研之有物專訪中研院經濟研究所蕭代基兼任研究員、臺大國家發展研究所周桂田教授,就經濟與社會政策提出建言。究竟臺灣的產業現況如何?有哪些推動淨零的誘因工具?如何降低淨零轉型對民生的衝擊?
我們必須先面對什麼問題? 臺灣現在比較大的難題是,我們是高碳排的國家。根據臺大風險中心的調查,2019 年臺灣十大溫室氣體排放企業中,有 6 家是石化業、2 家是鋼鐵業,排放總量約 1.034 億公噸,約佔當年度全國溫室氣體總排放量 36.05%。
雖然現在畫出淨零排放路徑,2020 年也宣示發展六大核心戰略產業 ,還是要以 2050 年為新目標,盤點臺灣產業正面臨的困境與價值。
例如石化業除了要思考如何解決高碳排問題,還需討論要留下什麼價值?畢竟在短鏈經濟時代,石化業是各國關注的戰略產業。否則就要形成區域的經濟聯盟,透過各國的資源交換來維持經濟發展。這都有賴針對產業現狀進行問題盤點,才能討論未來的發展藍圖。
周桂田教授指出,臺灣 2050 淨零轉型的首要工作:盤點國內產業的困境與價值。圖/研之有物 如何兼顧淨零轉型與產業發展? 我國政府長期的產業政策在於幫助產業降低生產成本,因此將許多能源價格維持得很低。例如汽油價格調整的原則之一是保持「亞洲鄰國最低價」,讓業者用較低的成本生產物美價廉的商品,保有與他國競爭的優勢。
然而,長年的低價策略卻導致賺得利潤、附加價值也連帶偏低,而附加價值內很大一塊便是薪資,因此人民的薪資水準難以提升,跟過度的產業保護政策脫不了關係。
國家與產業競爭力大師 Michael Porter 在 1991 年提出「波特假說」(Porter hypothesis),他觀察 1970 年代以來,美國、英國、德國、日本等國的環保政策對產業的影響,發現嚴格的環保政策能促使產業創新,不但減少污染,還能提高生產效率與競爭力。
所謂溫室裡的花朵沒有競爭力,有一個發人深省的故事:美國亞利桑那州有一處佔地廣闊的人造溫室「生物圈二號」(Biosphere 2),宛如另一個自給自足的地球。溫室裡有一棵非常高大的樹木,從小到大沒碰過風,導致枝條橫向生長且越來越長,最後支撐不住、硬生生斷掉!
大自然存在各種壓力,會讓樹木為了生存而長得更堅韌。環保政策就是外在壓力,能促使產業思考,如何在環保與減碳成本增加的情況下,發展新的競爭優勢。
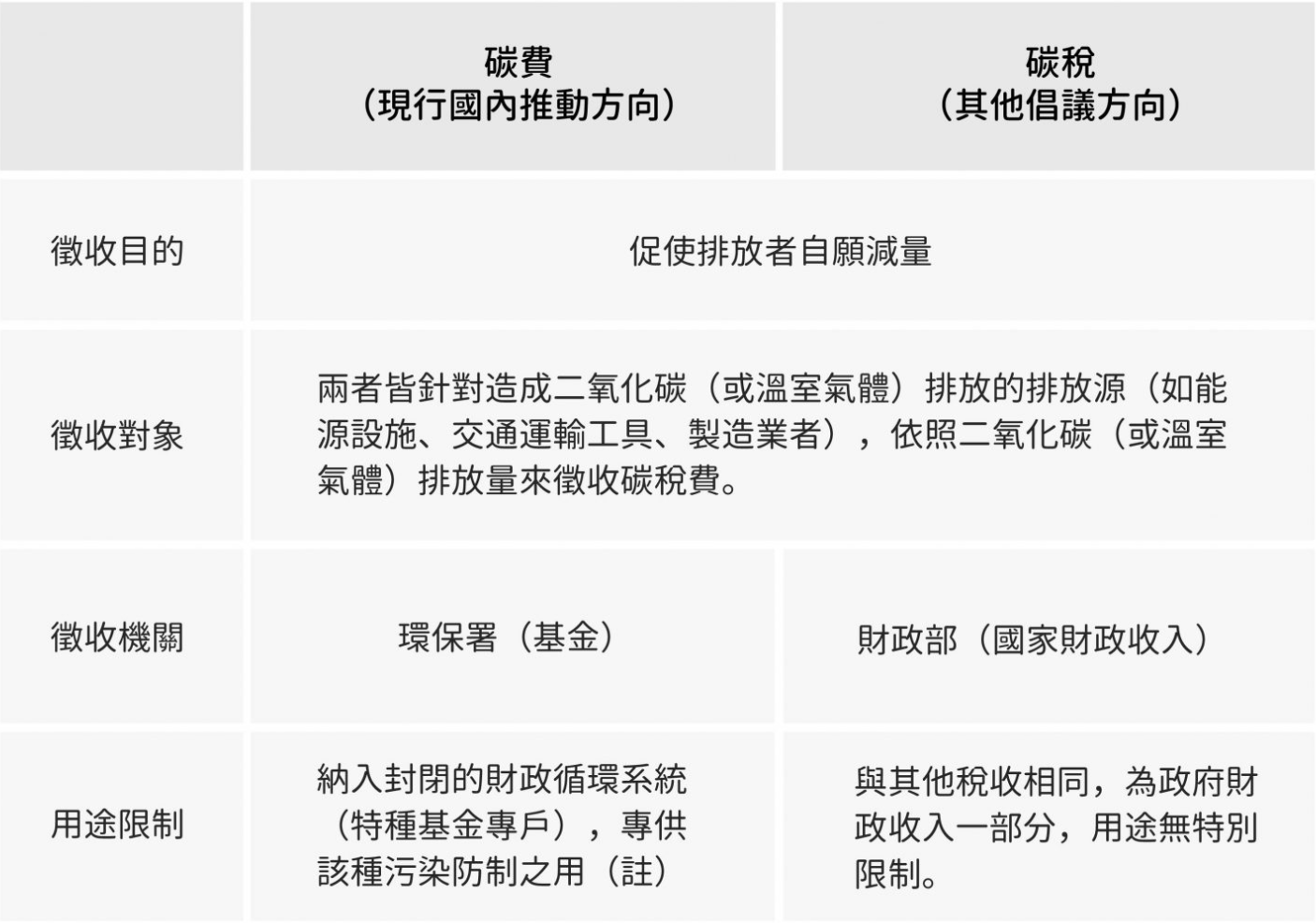
蕭代基教授分析,臺灣產業政策所導致的結構性問題,並舉「波特假說」說明嚴格的環保政策有助產業發展新競爭優勢。圖/研之有物 徵收碳費,但不徵收碳稅——差別是什麼? 國際上常見由政府制定「碳定價」措施,包含:碳稅費、能源稅、碳排放交易等制度,能讓氣候暖化的外部成本轉化成需付費的內部成本,促使企業主動減少碳排量。
我國政府預計 2024 年開始向排放者徵收「碳費」,而原訂徵收的「碳稅」則因財政部有重複課徵疑慮而暫緩。究竟碳費、碳稅有何差別?
首先,兩者的相同之處在於,皆是針對化石能源、商品或服務所產生的碳排放量來課稅,目的為促使排放者自願減量。
不同之處在於徵收機關與用途限制,碳稅由財政部徵收,用途沒有特別限制,為政府財政收入的一部分;碳費則由環保署徵收,只能專款專用於相關污染防治。
照理來說,政府收「費」是為了提供服務,例如收垃圾處理費是為了幫民眾處理垃圾。然而,如今徵收目的是要促使排放者自願減量,為了降低成本壓力,轉而從事綠色投資以推動產業轉型。不應該由政府收了錢去幫排放者做減量,因為政府做不到、也做不好減排!
建議未來要課徵「碳稅」,而不是只收「碳費」。因為碳稅的用途不受限制,能落實污染者付費原則,促使排放者肩負起減碳責任。同時也要完善碳排放交易機制,讓業者可以交易總量管制下的排放額度,增加減碳誘因。
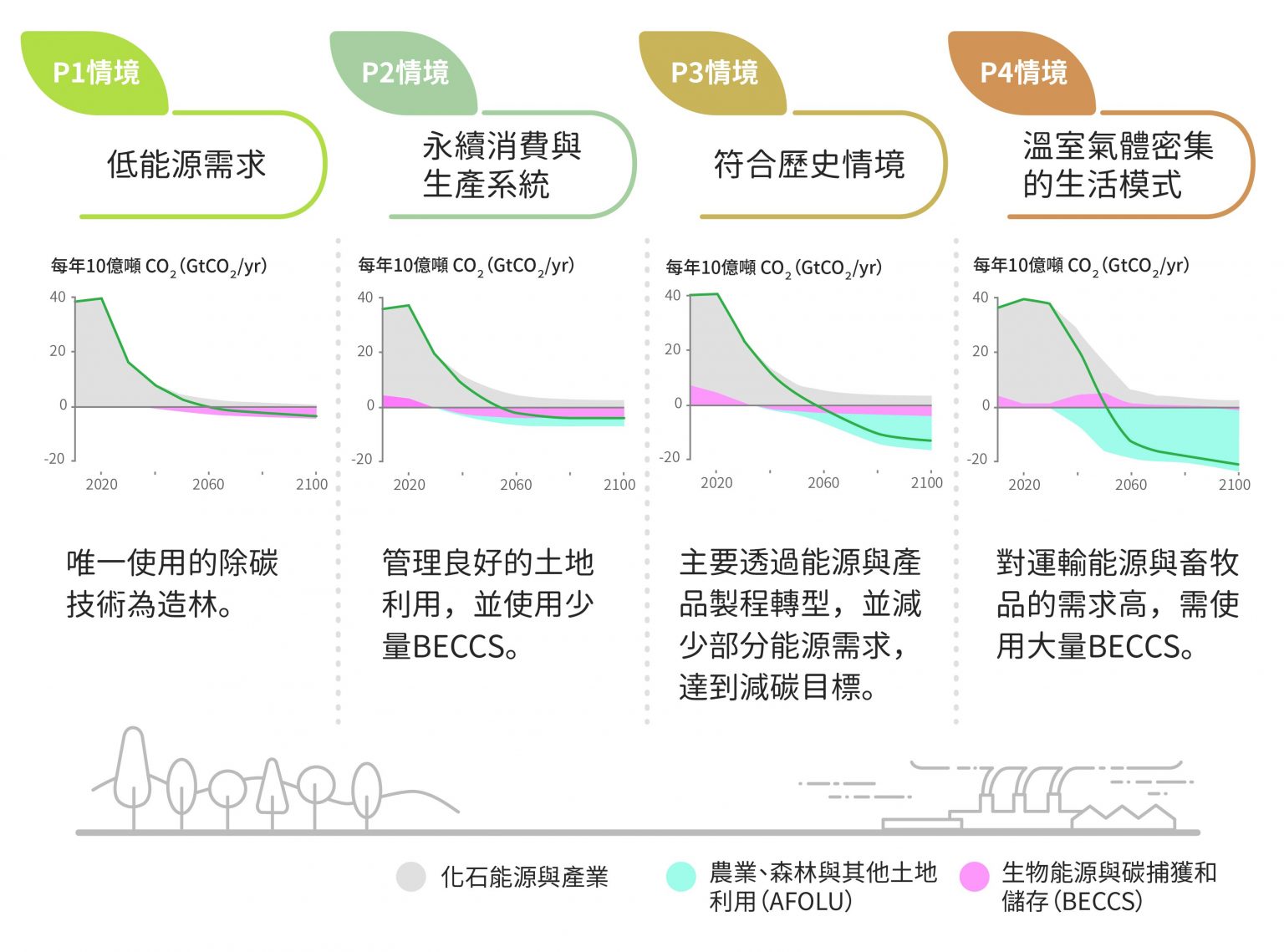
善用「森林碳匯」,不只減碳,更要除碳! 政府除了利用各種政策工具促成排放者主動減少溫室氣體排放量,還要鼓勵大家移除大氣中的溫室氣體,才能達成淨零排放。
現行除碳技術主要有:生物質吸收、自然界無機化學反應、大氣中直接移除。當中最便宜的除碳技術就是「森林碳匯」,透過新植造林、更新造林、永續森林經營,讓植物與土壤發揮固碳功效。
臺灣有多達 60% 土地是森林,應將森林視為再生資源,經營「永續林」。政府可用除碳費帶頭收購森林碳匯,讓業者有誘因將農地改成林場,並在樹木最佳固碳年齡時砍下,同時種植一批新樹,收穫的木材應拿去製成可持久利用的家具和建材。
假設輪伐期是 60 年,我們就能循環經營 60 座森林。而森林生長的過程,對空氣品質、水土保持、生物多樣性等都有莫大好處。
過去 30 年來,政府推行國有林禁伐政策,讓森林健康及永續林經營受到很大限制,連帶影響森林碳匯的預估值。
行政院在「臺灣 2050 淨零排放路徑及策略」中,規劃碳匯將從 2019 年 21.4 百萬公噸成長到 2050 年 22.5 百萬公噸,等於 30 年來只成長 1.1 百萬公噸的碳匯量,是相當保守的做法。如改成經營永續林,加入造林誘因及持久利用木材,應可增加更多碳匯量。
「森林碳匯」是最便宜的除碳技術,臺灣多達 60% 土地是森林,如改成經營永續林、由政府帶頭收購碳匯,有潛力吸引業者投入造林、增加碳匯量。圖為林業盛行一時的阿里山,如今只留下公共藝術追憶過往的林業發展史。圖/研之有物 如何落實淨零轉型政策? 淨零轉型政策的研擬需仰賴「社會強健性知識」(Socially robust knowledge),意指在生產跨領域、高度複雜的政策時,必須讓各領域專業人士參與,賦予政策強健的知識基礎。
英國早在 2008 年依據《氣候變遷法》(Climate Change Act)成立「氣候變遷委員會」,這是一個獨立的監督機關,由自然和社會科學領域的專家組成,有權編列各部會的減碳預算、審查減碳計畫,再送交國會複審。
如成立監督機關行不通,可參考歐盟成立「氣候諮詢委員會」,雖然沒有審核碳預算的職權,卻具備監督和專業諮詢的智庫功能。
我國行政院預計將淨零排放督導工作交給國家永續發展委員會,但為了強化執行力道與效率,建議行政院建立具備預算權的「氣候會報」,由行政院長總指揮各部會,畢竟氣候變遷是需要跨部會一起解決的問題。
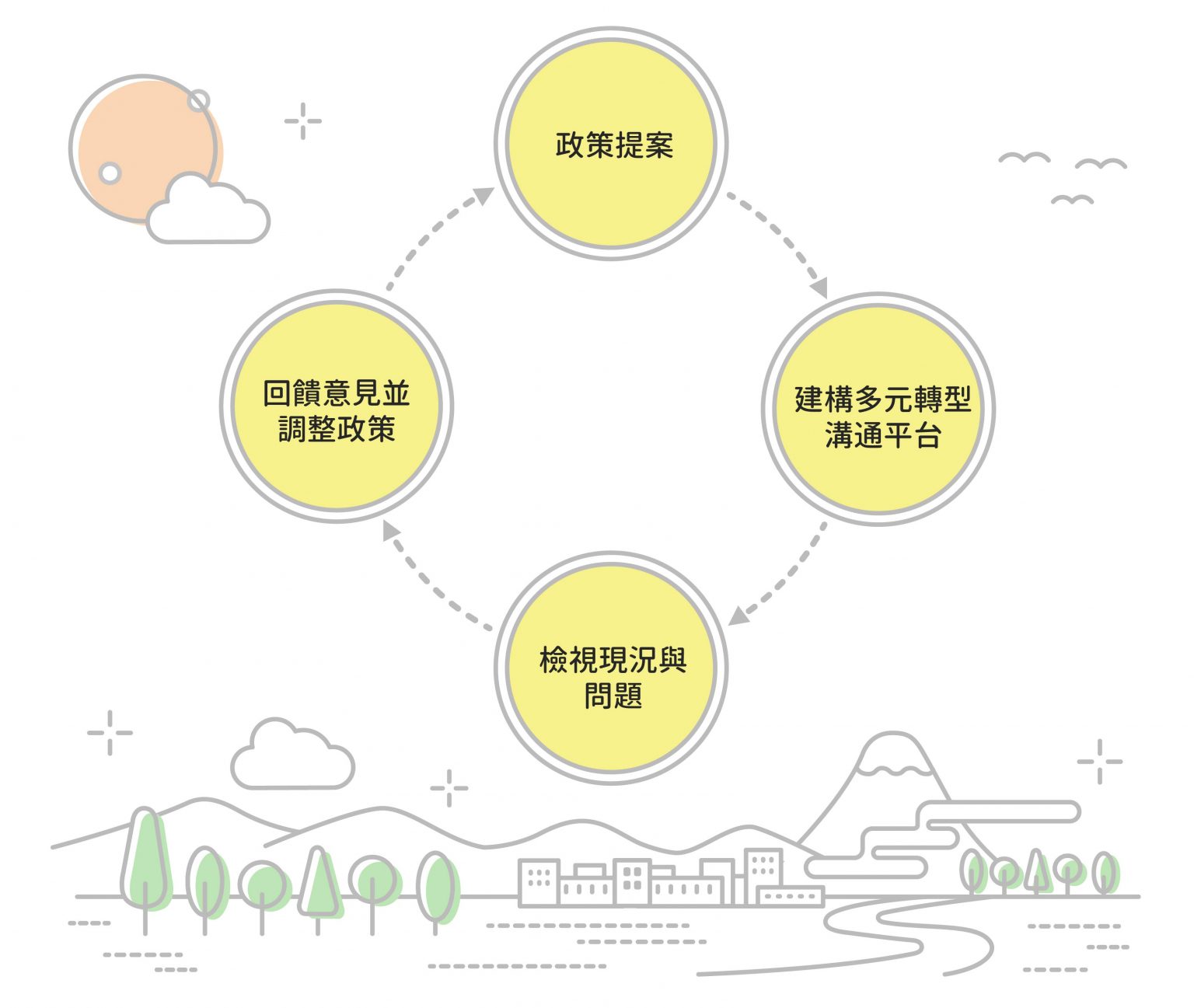
此外,還要建立鼓勵公民參與的「轉型行動溝通平台」,當中包含中央與地方政府、各領域學者、文史工作者、非營利組織等各方人士。先由政府提出政策、廣邀各界參與討論、檢視現況與問題,最後回饋意見並調整政策方向。
轉型行動溝通平台運作程序。圖/研之有物 碳定價政策可能導致減碳成本被納入生產成本,造成民生物價上漲,建議採取什麼配套措施? 2023 年初修法通過的《氣候變遷因應法》有條文提到:「依二氧化碳當量,推動溫室氣體排放之稅費機制,以因應氣候變遷,並落實中立原則,促進社會公益。」
「中立原則」意指,推動新的稅費機制時,為了不增加人民負擔,會從其他地方減稅,或將新增的碳稅費收入還給人民,使得政府總稅收不增不減。
建議還稅於民的措施加上排富條款,將這筆錢集中移轉給低所得者,有助改善所得分配不均的問題,提升民眾對政策的支持。
應執行還稅於民措施的原因在於,碳稅費是有累退性質的間接稅,會讓所得分配惡化。因為高所得者新增的碳稅費稅負佔所得的比例遠小於低所得者,而且低所得者的有限收入大部分用於民生消費,易受碳稅費引發的物價上漲影響。這就是為什麼要將稅收拿來彌補低所得者增加的花費。
適應淨零新生活的方法 如果擔心影響民生物價,民生用電可制定徵收級距、或暫緩調漲,但工業界的電價沒道理不調漲!這樣的整體思維將擱置臺灣的轉型進度。
事實上,臺灣現階段非常緊張,整個能源轉型進度遲滯,跟不上國際要求的 2030 年減碳 55% 進度,也難以因應各國祭出的碳邊境稅、綠色供應鏈等政策。
因此,業界現在多不會反對淨零轉型政策,反而希望政府趕快制訂規則,業界盡快配合調整內部作業。但目前政府考量民眾觀感,不敢大動作調漲能源價格、推動碳定價政策。
制定改變民眾習慣的政策時,應採取「行動取向的制度主義」,循序漸進設計出人民容易遵守的規定。
以限塑政策為例,從量販店、便利商店、飲料店等開始停供免費的塑膠袋與塑膠餐具,如自備環保餐具可享有優惠,逐漸養成民眾自備環保杯、購物袋的習慣。
淨零轉型政策相對來說更敏感,例如很多弱勢家庭為了省電費,晚上讓孩子到便利商店唸書,或只買得起耗電的二手家電,這些都需納入政策考量,可廣邀企業投身公益,和政府一起補貼弱勢家庭更換節能家電。
限塑政策依循「行動取向的制度主義」,制定民眾容易遵守的規定,養成自備環保杯、購物袋的習慣。圖/Unsplash 留給下一代「零碳未來」 你可能覺得淨零轉型議題遙不可及,但淨零排放路徑告訴我們,只剩不到 30 年的時間守住 1.5℃ 溫升防線,而臺灣起步的時間較他國晚了許多,更要急起直追落後的進度,否則我們將錯失產業轉型契機,承受大自然更殘酷的反撲。
根據臺大風險中心 2020 年民調 顯示,臺灣民眾對能源轉型政策的公平性、計畫性、迫切性,平均感受只有 3.83 分,且獲知能源訊息頻率以「一年一次或很少聽到」的 25.5% 最高,顯示政府尚需加強宣導淨零觀念,將零碳理念紮根於教育,提升社會對永續價值的認同。
好消息是,62% 民眾接受因推動能源改革而調漲電價,56.7% 民眾可接受因徵收碳稅而調整油價。整體看來,約一半的民眾願意配合加稅與漲價來節能減碳,雖然多數能接受的幅度不大(約 1-5%),但已是好的開始。
淨零排放路徑的公布只是一個開端,尚需建構完善的治理框架以促成公私協力,許自己與未來世代 一個零碳未來!
延伸閱讀