如何選擇理想中的另一半 ── 或者至少是小孩一半的基因來源,完全會是能影響下一代表現的起跑點。
日積月來下來,某些特別的擇偶偏好也很有機會造成驚人的結果:看看雄孔雀那精美的尾巴和雄鹿的巨大鹿角,這些讓演化生物學家困擾好久(還讓達爾文跟華萊士吵架)的成果就知道惹。

既然這是如此重要的一件事兒,除了那些頭好壯壯高又帥、一眼就有吸引力的外顯特質之外,內斂的聰明才智本身,有沒有機會能直接吸引到異性呢?
嘛,至少在虎皮鸚鵡眼裡,露露頭腦、懂得解決問題獲得食物的雄鸚鵡可以快速贏得雌鸚鵡的芳心,從魯蛇翻身成心上人喔~[註]
只要會找食物,虎皮鸚鵡魯蛇也能大翻身!
這組研究由中國科學院動物研究所主導,於今年 (2019) 發表。他們將虎皮鸚鵡二公一母三隻為一組,前期的實驗中,會先進行第一次的偏好測試:將雌鳥關在兩隻雄鳥中間的籠子,紀錄她在籠子兩側花的時間。在這個實驗中,科學家假設雌鳥花了更多時間在哪一側,就代表她更偏好其中的哪一位。
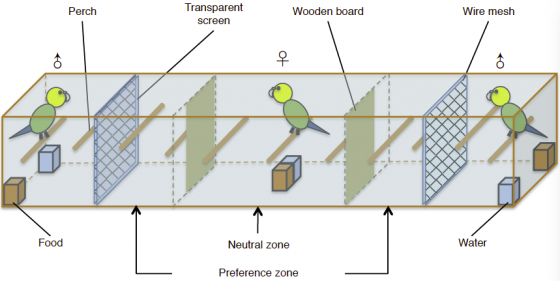
接下來,就是科學家插手幫魯蛇作弊的時間啦!
在實驗組中,一開始不被青睞的雄鳥會進行特訓,訓練他們打開培養皿(一步驟)和箱子(三步驟)獲得食物。雄鳥特訓完畢獲得新技能,就進入展示時間:雌鳥會見到自己原來偏好的雄鳥打不開培養皿束手無策,也會見到一開始不喜歡的那個展現了出乎意料(?)的才智,見招拆招順利獲得食物的畫面。
於是在下一次的偏好測試中,大多數的雌鳥都花了更多的時間在原來不偏好的雄鳥那一側。芳心 Get! (戀愛特訓班大成功)
有吃得不是重點,有腦袋才受青睞?!
且慢且慢,憑什麼這樣就說雌鳥是「移情別戀」?難道不能是「這招不錯我偷要學起來」或是「他吃得不錯我看看是否能蹭點來吃」……之類的想法嗎?
因此在這個實驗中,安排了兩種實驗對照組。
其一同樣是二公一母的組合,但這個對照組中,沒有安排特訓,展示時間只安排雌鳥看到原先不被偏好的雄鳥獲得食物,而原受偏好的雄鳥什麼也沒得吃。但如此一來到了第二次偏好測試階段時,展開仍然是一開始愛誰就是誰;顯然光是吃香喝辣(?)並不足以讓雌鳥移情別戀啊XD
另一個對照組稍微出乎意料一點:步驟與實驗組相同,但三隻虎皮鸚鵡通通是母鳥來著。實驗顯示,即使是一開始不被偏好的雌性虎皮鸚鵡同樣可以打開培養皿和箱子獲得食物,但這並不會影響做選擇的雌鳥的偏好。換言之 ── 閨密能不能解決問題不重要,我喜不喜歡她比較重要(誤)。
因此能發現「移情別戀」只出現在對雄鳥的偏好之中,顯示對虎皮鸚鵡來說,聰明才智帶來的吸引力的確有可能跟選擇配偶比較有關係一點兒。

事實上,野生的虎皮鸚鵡本來就需要適應多變的覓食環境。而且即使在人工飼養環境下,配對之後虎皮鸚鵡也是由雌鳥主要負擔孵育幼鳥的工作,雄鳥負責叼食給雌鳥供應食物。因此伴侶獲得食物的能力,理論上對雌鳥來說非常重要,畢竟一家大小的口糧都要靠老爸掙來啊。
對面的女孩不肯靠過來?露個腦袋給她瞧瞧吧!能解決問題才是真性感啊!── 虎皮鸚鵡不負責任戀愛指南。
- 註:此實驗組和對照組中,受青睞的雄鳥其基本的測量值都和不受青睞者沒有統計差異。換言之(至少在人類眼中)並沒有特別高又帥,就只是一開始比較受偏愛。
參考資料:
- Chen, J., Zou, Y., Sun, Y. H., & ten Cate, C. (2019). Problem-solving males become more attractive to female budgerigars. Science, 363(6423), 166-167.