- 文/大家的語言學│在科技業闖蕩的語言學人,有感於社會大眾對於語言學的誤解,因此致力於將語言學知識科普化,帶領你發掘生活中無所不在的語言學大小事。
為什麼有那麼多的語言,都要叫母親為 mama、父親為 papa? 這一切都只是巧合嗎? 或是其中有什麼樣的語言秘密呢? 今天我們要為各位解開,mama/papa 這兩個詞產生的謎題。
到底有多少語言稱母親為 mama、父親為 papa? 語言學家 George P. Murdoch 曾經調查了 470 個語言,發現這些語言中稱呼母親的詞,有 52% 都含有 ma、me、或是 mo 的音,稱呼父親的詞則只有 15% 含有 ma、me、或是 mo。他進一步發現,這些語言中用來稱呼父親的詞,有 55% 是含有 pa、po 或 ta、to 的音,但稱呼母親的詞僅有 7% 含有 pa、po 或 ta、to 的音。下方這張圖列出部分語言為例,我們確實發現,稱母親的詞,幾乎都含有 ma 的音,稱父親則多半有 pa 或 ta 的音。

假設 mama/papa 存在於原始語言中
語言學家首先假設,人類在很久很久之前,曾經有一個共通語,之後所有的語言都是從這個共通語發展而來。至於這個共通語到底是多久以前的語言,目前沒有人知道,只能假設或許在 10 萬年前的智人時代(Homo sapiens)就已存在 。截至目前為止,因為印歐語系(Indo-European)是語言學家研究最廣泛、深入的語系,於是,語言學家根據比較語言學的方式,建構了假想的原始印歐語(Proto-Indo-European),這也是目前語言學家所建構出印歐語系各個語言的共同祖先。
那麼,我們就假設 mama/papa 在原始印歐語就已經存在,並且流傳至今吧!這個假設看起來很完美:「很久很久以前,人類有一個最早的語言,這個語言叫母親為 mama,父親為 papa,並且流傳至今」。
但實際上語言學有個的重要概念,會推翻這個假設。在這之前,我們先來看看一個和 mama 的語意類似的詞──代表女性的 「woman」。以下我們列出在七個不同印歐語系中,代表 woman 的詞:

上方這些語料都是屬於印歐語系的語言。當我們試著找出這些詞的源頭, 我們發現各個印歐語言代表 「woman」的詞彙都不一樣,有些甚至差異甚大,已經很難推論在原始印歐語中,「woman」這個詞究竟是長什麼樣子。
然而,還是有語言學家很努力的用比較語言學的方法,推斷 「woman」在原始印歐語的形式是: ∗gwena。看到這裡,我們發現在上表這七個印歐語系中,已經很難找出和 ∗gwena 共同的語言特徵了。因為語言經過幾千年的演變,字型、語意、讀音可能都已經改變了。
這裡帶出來的語言學重要概念是:語言會不停地改變。假設在 mama/papa 這兩個詞在原始語言就已經存在,那麼,我們現在看到代表母親/父親的詞,就絕對不會是 mama/papa,因為,語言是一直在變的,不可能經過幾千年都沒有任何變化。
不斷演變的語言,不停轉換的語音

以日文為例,現代日語稱母親為 haha,但根據歷史語言學家的研究,現代日語 /h/ 這個音,是從古日語(Old Japanese)的 */p/ 轉換而來。也就是說,母親在古日語的念法是 ∗papa;值得注意的是,這樣的演變才經過幾個世紀而已。也就是說,短短幾個世紀就有這樣顯著的音變,如果我們假設 mama/papa 存在數千了前的原始語,那麼字型、語義、讀音不可能維持和現在完全一樣。
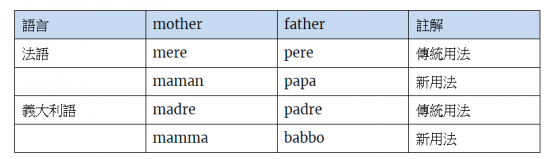
更有趣的是,有些語言開始出現 mama/papa 的用法,但這些語言中傳統稱呼母親/父親的詞也仍存在著。也就是說這些語言有傳統代表母親/父親的詞,卻也新產生 mama/papa,使得傳統用法和新用法共存(如下表法語和義大利語為例)。這樣一來,我們假設 mama/papa 是存在於原始語言的說法,就無法成立了。
 說到法文的 papa,筆者想到了一段有趣的影片,提供給各位觀賞:
說到法文的 papa,筆者想到了一段有趣的影片,提供給各位觀賞:
在前面,我們假設 mama/papa 這兩個詞是從古老的原始語就存在了,因此,許多語言至今都還保留這樣的用法。這個假設看似完美,但實際上語言是會改變的,我們舉了古日語和現代日語的例子,才經過幾個世紀的時間,就有讀音從 /p/ 變成 /h/ 的音變現象,更何況是假想中幾千年前的原始語呢? 很可能拼法和讀音都會變化得完全不一樣了。
來自小孩的第一個發音:mama/papa

那麼,mama/papa 究竟是從何而來?我們將根據語言學家 Jakobson 的分析,提供一個大多數人都同意的答案。Jakobson 可說是研究兒童語言習得的先驅,根據他的論述,mama/papa 這兩個詞很有可能是小孩的父母親創造的。
首先,我們先簡單介紹兩個兒童語言習得的階段:咕咕時期 (cooing)和 呀語時期 (babbling)。
- 兒童在大約一個月大時,進入所謂的「咕咕時期(cooing)」,這個階段的嬰兒會開始發出一些聲音,但這些聲音是無法判別語意的,因此父母親不會認為他們的小孩是在說話。
- 從三到四個月開始,進入了「呀語時期 (babbling)」,到了這個階段的兒童,開始發出成人可以辨識的音,包含一些母音和子音,且會慢慢出現重複音節的音。
我們假設有個小女孩名叫艾瑪,當她進入了呀語時期,開始發出他的父母熟悉且可以辨識的音。奇妙的事情在「呀語時期 (babbling)」這個階段發生了,她的父母親會認為,艾瑪開始在跟他們說話。但實際上,呀語時期這個階段對於艾瑪來說,主要是在練習發音器官,而不是在和大人對話;不過欣喜若狂的父母可不是這麼想,他們會很自然地認為,艾瑪是在跟他們對話。
那麼,艾瑪最有可能發出的第一個可辨識的音是什麼?這就與發音的困難度有關了,分成子音和母音來看,最容易發的母音是 [a],因為你只要張開嘴巴、震動聲帶、送出氣流,音就發出來了,舌頭和嘴唇幾乎都不用動;子音則是 [m]、[b]、 [p]。
因此,[ma]、[pa]、[ba] 可說是最容易產生的發音組合。

當小孩發出 mama 的音時,母親會很興奮的認為小孩在與他互動,並且認為小孩是在叫她,而不是在叫家裡的狗、桌上的食物等。接著,母親就會開始認為,這是他的小孩所說的第一個字,「叫 mama、叫 papa」就是常見的父母親和小孩的 baby talk。
接下來, mama/papa 這兩個詞會開始擴展,艾瑪的父母會向他的親戚好友說:「我的艾瑪會開始叫 mama/papa 囉」,於是 mama/papa 開始代表著父親和母親的意思,而不是特定指艾瑪的父親和母親。這是一個重要的轉折點,代表詞彙開始進入這個語言的系統裡,社會上越來越多人這樣使用。當艾瑪長大後,她也會知道 mama/papa 代表所有的父親和母親。
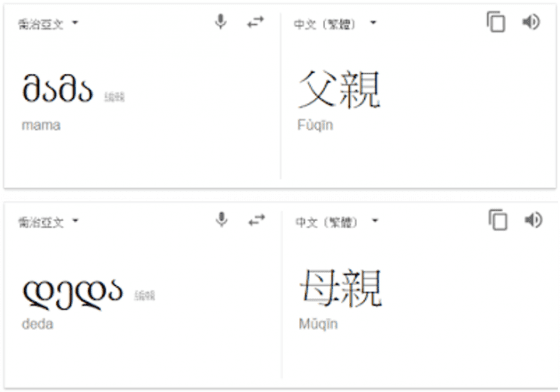
Jakobson 所提出來的這個解釋,還能夠幫助我們釐清為什麼有些語言中,父親叫 mama、母親叫 papa?
喬治語 (Georgian)就是一個例子, 叫母親為 deda、父親為 mama,和大多數的語言正好相反。若用語言習得的角度來解釋,子音 [d] 也是屬於容易發出的音,所以有可能是因為喬治亞語在一開始有小孩在「呀語時期 」所發出的第一個音是 deda,於是他的母親認定 deda 就是她的寶貝在叫她;無獨有偶,恰好也有不少的喬治亞孩童的第一個發音也是 deda,慢慢地詞彙經過無數次的使用後,從此 deda 就進入了喬治亞語的系統,代表母親。
行文到此,我們對這個主題做個總結:
- 語言是會改變的。原始語的文字拼法、發音,經過了幾千年的時間,可能都改變了好幾次,因此,要從目前的 mama/papa 去推判其原始語,非常不容易(且前提是假設真的有原始語)。
- 此外,有些語言的父親叫 mama,母親叫 papa,假設我們真的找到了原始語中的 mama/papa,該怎麼解釋這些用法剛好相反的例子?
- 若從兒童語言習得的角度來探討,兒童第一個發出的可辨識音節,通常是比較容易發出來的音;再加上父母親賦予 mama/papa 的語意,透過語言擴張、約定俗成後,就慢慢地進入語言系統。這就是為何有那麼多的語言都有 mama/papa 這兩個詞彙。
下回當你聽見有小孩在叫 mama/papa 時,相信也能會心一笑,體驗語言發展的魅力。
備註:依歷史語言學的慣例,未證實的形式會以星號標記岀來,例如本文的 ∗gwena “woman” 或 */p/ 是經語言學家推測,但目前仍無法證實的形式。
參考資料:
- Jakobson, R. (1962) “Why ‘mama’ and ‘papa’?” In Jakobson, R. Selected Writings, Vol. I: Phonological Studies, pp. 538–545. The Hague: Mouton
Where do mama/papa words come from?
本文轉載自大家的語言學,原文為《為什麼有那麼多的語言都叫母親為mama, 父親為papa?(上)》、《為什麼有那麼多的語言都叫母親為mama, 父親為papa?(下)》