儘管郊狼 (Canis latrans)的蹤影難得一見,但牠們的聲音倒是讓人聽來十分熟悉。
晚上的嚎叫完全不會讓人認為牠們身處邊緣地帶,相反地,狼嚎傳遍大地,頓時之間吞噬整個夜空,充填整個空間。我們住的地方離地方上的消防隊大約有一、兩公里遠,當火災警報響起時,不可避免地會聽到高亢的警報聲。在緊急警報所發出刺耳的機械聲裡,牠們似乎能從中辨認出什麼,激發喊叫的本能。
幾年前,一個冬日的下午,我丈夫穿著他的雪鞋,走上我們屋後山上的草地。才穿過一條古老鹿徑的松林,這個寂靜的下午就足以讓他幻想自己是一人獨立於天地間。但是,在他穿過田野之際,消防隊的警笛響起,片刻之後郊狼也開始放聲大叫,聲音似乎就從他所在位置不遠的地方傳來。

我不知道郊狼到底在回應什麼,是否牠們有某些本能,讓其意識到,在這樣聽來悲傷而且毫無意義的訊息交換中,牠們正在回應的是另外一個物種。又或者,牠們只是在回應這個牠們聽來熟悉的聲音。最有可能的解釋是,警笛的鳴聲提醒牠們劃設自己的領地,廣播自己的狀態,宣布自己和其所佔領的一方土地。
兩種完全不同的警報系統,以一種陰森恐怖的語調來相互呼應,這就是一種交流,扣問著為何我們意圖向未知回應,無論是在探尋熟悉的,還是只是出於好奇心。這兩者之間以其特有的方式呼應,突然而自發的互動。
用「狼嚎」追蹤和研究狼群
生物學家有時會使用這種警報器的聲音來追蹤郊狼族群。
在愛達荷州和蒙大拿州的偏遠地區,科學家用一種稱做「嚎箱」(Howlbox)的設備來尋覓郊狼族群。這套配備有一個揚聲錄音系統,能夠編排並播放出電子狼嚎聲,引起這區域的郊狼回應。分析聲音頻率的頻譜技術讓科學家得以區分各種反應,幫助他們計算狼群數量,最終有助於狼群的長期管理。

郊狼不會和狼一樣進行和聲;牠們的音調較高,而且小家庭的組合讓音波的範圍更為多樣。牠們的發聲可分成十一種基本的聲音,從叫喊、狂吠、咆哮、哀鳴、嗚咽到低鳴都有。但是這些詞彙加總起來也不足以形容實際上從夜晚的樹林中傳出來的聲音。
我想,這應當是一種賦格,甚或是詠嘆調。但是,這些說法還是不夠正確。而且這些聲音的功能也充滿多樣性,有呼喊伴侶、呼喚小狼、宣告領土、建立支配權、歡迎以及警告。
聆聽動物發出的聲音時,我試著要更為警覺,更加注意在聲音的層次上。聲音可以顯露出發聲位置的狀況,四月上午的春雨樹蟾,十一月風吹落葉刮在草地上的颼颼聲,一月時河面上冰裂時所傳出的那份震耳欲聾的崩裂聲。大地上的一切動靜,正如任何一個認真的觀鳥者都知道的,全都可以透過聲音顯露出來。

梭羅沒有蓄養動物,只聽到「屋頂和地板下有松鼠,屋頂脊樑上有隻三聲夜鷹,冠藍鴉在窗外尖叫,屋子下方可能有隻野兔或旱獺,屋後可能有隻鳴角鴞或長耳鴞,池塘裡有一群野雁或是大肆鳴唱的潛鳥,以及夜間有隻狐狸在嚎叫。」
聲音之所以能讓我們定位自己的所在,也許是因為聽覺有其獨特之處,比起視覺,這和記憶的關係更為密切。聲音匯集在大腦的一些感官區中,比起視覺,聽覺的聯結更為原始,結合起來會迅速產生意像。這就是為什麼你可以記住幾個月或幾年前所聽到的話語,回憶起當時的腔調和節奏,發出一樣的音頻和音準,乃至於從中找到新的意義;或者是,聽一首長久以來遭到遺忘的一段音樂,可以在眼前瞬間展開你過去的生命。
當然,自然界的聲音會觸發古老的恐懼和樂趣。即使是到今天,傾聽與大地景觀之間的連結之所以仍然很重要的原因,可能只是因為我們最原始的爬蟲腦區依舊保留著祖先在大草原上學會的保命知識,知道要如何趨吉避兇,而這些經常是透過聲音來理解的。鳥類驟然靜止,安靜下來,正是遭受威脅和混亂的信號,而鳥鳴之所以能取悅我們,也是因為這帶來一份安心的感覺。

伯尼.克勞斯是位音景專家,他著有《偉大的動物交響樂團》一書,當中提到透過聲音可建構出風景,他還提出「區位假說」(niche hypothesis),推測在一特定棲地中,其聲音多樣性可代表此處生態的健康狀態。克勞斯認為,長時間下來,鳥類和動物界的發聲方式不斷演化,每個棲地的聽覺信號在整個更大的音景之中自有其居所,而這些生物體所組成的大型交響樂團,全都經過精確的校正,能夠保證當中每個樂手的福祉。
無論是交配鳴叫、預警信號、宣示領土或是因為痛苦和不適而發出的叫喊,生物的聲音都有助於確保其生存。雖然這一切仍然還是謎團,不過郊狼喊叫的細微差別,讓我覺得這樣的假設有可能是真的。
我不太能清楚區別何時狂吠轉變成叫喊,或是咆哮轉為低鳴,我只能確定,某聲音是恐懼和慾望的聚合,或是在歡迎聲中又參雜有警告的意味。狂叫之中帶有哀鳴,這些聲音的差異相互混雜後,進入我的耳中,牠們的對談從輕輕的問候轉換到主權的宣示,而這其中,只有幾個音符的差別而已。當我向凱斯提出這些問題時,他只是說:「在野外是很難判斷聲音的。」
我想他的話很有道理。也許,想要瞭解、理解、破解乃至於建立一套這些聲音的目錄,以及建立這些聲音和其所表達的意圖之間的連結,對人來說是件再自然不過的事情。
人類想要確切的答案,這驅使每當我們的好奇心被觸發時,我們就會求助於iPhone和Android。但解釋郊狼的喊聲並不是一個不確定性的問題,而是一個毫無頭緒的問題。這些聲音出現在莫名地帶,凱斯直言不諱的回答,只是讓我明白,在我們的生活中,也有無法回答的事情。
此外,這些喊叫聲的頻率,會讓人產生錯覺,誤以為郊狼在遙遠的地方。聽牠們的喊聲,很容易專注在聲音和意圖之間那些令人難以捉摸的關聯,反而錯過某個轉音,錯失整段聲音的意思。
在牠們的重複和迴聲之中,兩、三隻郊狼在喊叫時,聽起來像是有二十來隻,以某種遙遠聲音的持續推進,來宣示牠們的存在。這是牠們發聲的另一個招數,一旦開始叫喊,就會產生一種數量不斷加倍的效應,從兩倍、三倍乃至於四倍。然而,儘管喊叫是集體的行為,但這依舊是一曲孤獨的配樂,而這種模糊曖昧的狀態,似乎就是牠們所傳達的基本訊息:
你是單獨的,但不是完全孤單的。

這支郊狼合唱團,不知是動用什麼技巧,竟能夠同時傳達出這兩種訊息。
害怕或是共生?狼與人之間的關係
在二十一世紀的今天,我們很少在動物領域中尋找祖先過去經常看到的那些圖騰。引起我們興趣的,往往是關於動物的科學,而不是這些動物的精神世界。

但我想郊狼也許是例外;在神話和傳說裡,郊狼和人類有悠久的交會傳統,將人與牠們相提並論的衝動也許還沒有完全消失,總是想要在牠們的狡詐、詭計、獨立性、孤獨的野性或是任何其他我們賦予給牠們的特點中尋找什麼。

二○○八年一項針對郊狼和人類在農村地區互動的研究,就在我家的正南方進行,這項研究發現,儘管大多數居民都曾感受到郊狼的存在(不是在院子裡看到,就是聽到牠們的喊叫),他們多半認為自己是獨自一人與郊狼照面,並判定鄰居對郊狼一無所知,或是沒有意識到牠們的存在。看來,人似乎想要將我們自己與這種動物的交會想像成是一私密、獨特的發生。基於某種莫名的原因,郊狼的孤獨性似乎融入在我們對牠的經驗與理解中。
這個區域的郊狼偏好在山上建立自己的領地,但是這裡的南邊已經少有農村,牠們開始適應人群。來去無蹤已不再是牠們特有的標記,三不五時就有人看到牠們跳進郊區的高爾夫球場,甚至進入曼哈頓市區,直抵中央公園閒逛,不然就是在翠貝卡(Tribeca)那裡疾跑而過。雖然這有部分原因是來自於棲地喪失,以及對人類的熟悉度與日俱增,也有人猜測,美東郊狼與家犬雜交有助於促進牠們發展出與人類親近的習性。
每年春夏,常常都會聽到牠們攻擊居家寵物,牠們突如其來的身影也嚇壞不少在庭院裡玩耍的孩子。郊狼在人類周遭建立起的舒適圈,對人來說卻構成了一種威脅,專家建議要讓牠們對人類養成恐懼的習慣,若是牠們進入庭院,可以敲打鍋子來嚇唬牠們,或是扔石頭或棍棒之類的,再不然就是以其他方式驅離。這樣的論點發展到極端,則是主張狩獵和捕捉,這樣可以保持牠們對人類天生的恐懼感,說到底,這可能是保護牠們最有效的手段。
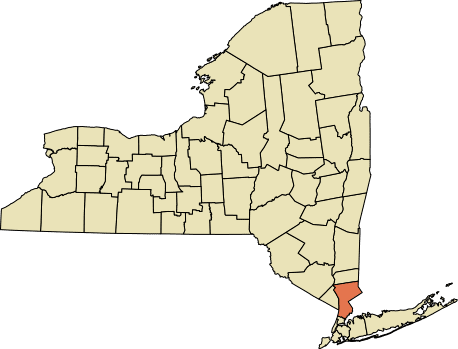
二○○六年一項對威斯切斯特郡郊狼的研究,以公民科學的方式來繪製牠們的棲地地圖,並記錄牠們與周圍的人類互動。這項以自發性的形式來進行的調查,請學童記錄是否有看到或聽到郊狼,以及其地點。不出所料,居住在林地與草地附近的人家表示聽到與看到牠們的比例遠高於都會化程度較高的區域。
負責協調管理這項研究計畫的是紐約貝德福德的米亞納斯河峽谷保護區的生物學家馬克.偉克爾,當我打電話問他關於參與這項調查的家庭的情況時,他告訴我,在這個郡的北邊,農村較多,農戶的面積較大,當地人比較習慣看到野生動物,那裡的居民通常不會把郊狼看成是一個問題。反觀在郡的南方,主要是都會區和郊區,那裡的人對郊狼比較不熟悉,通常還是會一直抱持戒慎恐懼的心態,而郊狼也會不斷打擾當地居民。
偉克爾希望透過這類研究,比如說他目前手上的這項計畫,讓野生動物專家妥善管理郊狼族群,同時也幫助在地居民學習如何適應這個逐漸在郊區浮現的新景觀。正如在報告中他所下的結論:
在威斯切斯特郡這類郊區,郊狼的未來不僅取決於我們對城市郊狼生態學的理解,也要看地主是否願意與這群頂級掠食者分享其後院。我們採用公民收集的數據,以此來詳加描繪這批在社區中的新興捕食者的輪廓,這是管理人類與野生動物潛在衝突的先決條件,也讓屋主得以衡量自身的風險。
長久以來,科學研究常遭到不夠透明的批評,藉此讓公眾充分利用,其目的本就是在服務大眾……公民科學試圖讓利益相關者加入知識建構的過程,希望藉由這一步,讓利益相關者對身邊的環境問題更為積極地參與。

本文摘自泛科學 2018 年 6 月選書《意外的守護者:公民科學的反思》,左岸文化出版。