- 【科科愛看書】小時候老師常常要我們成為一位有德之人,可是可是……《道德可以建立嗎?》如果道德可以建立的話,那我們又該怎麼做?總而言之,快快拋開那些讓人暈頭轉向的道德教科書,來面對有趣的難題,一起來燃燒大腦、喚醒你的哲學小宇宙吧!
我們怎麼會傾向於用好與壞、正當與不正當這樣的字眼,來評論別人的行為,而這些行為往往和我們沒有直接的關係?我們這個物種,假設是由本質上很自私、最關心自身物質幸福的個體所組成,那麼要怎樣解釋,我們所表現出的利他、好心或慷慨的行動並不屬於特例?
人類的道德,到底從哪裡來?
對於這些問題,有些傳統的回答指向社會學習中獎懲的力量,有些則指向「與生俱來的道德感」或「道德本能」的存在1。
一、學來的道德
如果我們以道德用語評論他人,並且能在行動上合乎道德,完全是因為我們從很小的時候開始,就受到訓練要這麼做,而且是因為有些制度安排了一些方法,強迫我們一直這麼做2。
二、與生俱來的道德
如果我們以道德用語評論他人,並且能在行動上合乎道德,那是因為我們天生具有某些道德能力,它在我們出生後很快就會表現出來。我們可以說是經過設定,要用道德的字眼評論他人,並時常表現出利他或好心的行為,這麼做也許是由於這些行為對我們這個物種有種種好處3。
上述第二個假設屬於「自然主義」(與「文化主義」形成對比),是目前引起最多討論的假設。
通過獎懲的社會制約理論,又稱「行為主義」。我必須指出,它在人文科學的所有領域中都有點被打入冷宮。針對這類理論的反擊,在語言學的領域最見成效。很多語言學家承認,在母語學習上有許多難以解釋的問題。確實,兒童沒有經過旁人有系統地教導,最後也能掌握母語的使用,有能力說出無數自己從來沒聽過的語句,也不會有文法上的錯誤。
對這個現象所能找到最好的解釋,似乎是說所有人類都天生具備了語言能力,能讓他們從接收到的少量資訊中,重新組建出整個語言。
在道德的領域中,相同類型的假設看來也占有一席之地。
我們具有天生的語言能力,能夠說出從來沒有經過有系統地學習的語言;同樣地,我們也具有天生的道德能力,即使沒有經過旁人有系統地教導,也能知道什麼是好的或壞的、正當或不正當的4。就算是嬰兒,在看到他人受苦的場景時,也會表現出不舒服的反應,或是兒童,不論他們接受的是哪種教育,面對不公正的行為,也會有類似的反應。這些事實支持了這個假設5。

這種所謂「道德感」〔譯注:或稱「道德情操」〕的理論(早在十八世紀便獲得蘇格蘭哲學家的支持),並沒有指出人類天生就很「善良」。該理論也完全接受,除了好心或「親社會」的傾向與生俱來之外,其他破壞性與「反社會」的傾向也是與生俱來6。它只明確表示人類不用經過學習,生性就傾向於以道德的眼光評論他人的行為,而且他們「親社會」或「合乎道德」的行為(利他、慷慨等等),不是什麼特殊的表現。這只能代表人類「天生有道德」。
有些學者認為所謂「人類心智模組」的理論,也許可以讓天然道德觀的想法,擁有穩固的科學基礎。
然而佛德(Jerry Fodor)並不這麼想。他為了使模組的觀念有足夠明確的內容,付出很多心力7。在他看來,道德模組的觀念不過是個隱喻,很有吸引力,但沒有任何科學意義。
為什麼?
特殊化的心理機制,「模組」真有這麼神奇?
佛德表示,模組是高度特殊化的心理機制,組織起來用最有效率的方式處理某些特定的問題:辨識形狀、聲音、氣味、顏色、物體的質地或滋味,將聲流切割成單字與句子等等8。
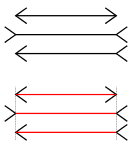
模組的運作如同反射作用:無意識、快速,獨立於我們的意識與意志之外。我們可以清楚識別它的生理基礎,當這個基礎被摧毀時,模組就停止運作(想一想視覺是怎麼回事)。它不會受到信念或知識的滲透。至少這是我們從某些知覺層面的錯覺之所以存在所得出的結論。即使我們知道兩條線的長度相等,但要是它們的末端各具有方向相反的箭頭,我們還是會看見某一條線比另一條長(稱為「慕勒——萊爾錯覺」〔Mller-Lyer illusion〕)。
對佛德來說,真正的、唯一能符合所有標準的模組部署(dispositif),是感官知覺的部署。大體而言,它涉及我們的五個感官與語言的自動解碼系統。
思想不是、也不能形成模組,因為在思考的活動中,必須納入我們的信念,而不是把信念隔離在外。這個過程不見得很迅速,完全算不上是無意識,在大腦中也沒有清楚的負責部位。佛德認為這就是為什麼沒有嚴格意義上的認知模組。思考的活動是某種全面的智力活動,遍及所有的領域,並不是來自具有特定目標的笨模組,呆板地完成早就被設定好的任務9。
總的來說,佛德絕不同意「模組巨集」的理論,尤其是斯波伯(Dan Sperber)支持的有關人類心靈的構想,後者接受人類有無限數量模組存在的理論,各種形式都有,並具有各種功能,感覺的、認知的、道德的或其他種類10。
佛德還嘲笑所謂「騙徒偵測模組」11,同時明確排除了道德模組的存在可能。
我們的腦袋裡是否真有「騙徒偵測」的道德模組12?
心理學家科斯米德絲(Leda Cosmides)與人類學家托比(John Tooby)從某些實驗研究得出結論,表示我們的心靈中自然配備了某個系統,它可以讓我們快速、自然而然、幾乎是無意識地,偵測出哪個人在人際合作中不值得信賴。這就是他們所說的「騙徒偵測模組」13。
他們的出發點是著名心理實驗「選卡片」,華生(Peter Wason)在 1966 年提出實驗14。
這個實驗的目的其實不是很清楚,但大家已經習慣說它是要檢驗我們對「若 P 則 Q」這種條件推理的掌握能力,或是檢驗我們能否選出最佳假設的「波普爾」能力〔譯注:哲學家波普爾(Karl Popper)提出否證論(falsificationism),認為一切從經驗得來的假說、命題和理論必須邏輯上容許反例的存在才是科學的〕15。
接受實驗的對象假定都很「聰明」(例如大學一、二年級的學生)。他們必須面對四張卡片,每張卡有一面是數字,另一面是字母,如下圖:
主持者會宣布:
「你的面前有四張卡片,它們一面是數字,另一面是字母。若卡的一面是 D,則另一面是 3。你必須翻開哪幾張卡片才能驗證這個規則正不正確?」
愛好邏輯學的人士可以指出,只要知道條件連接詞「如果……則」的真值表就能得到正確答案。是的,這裡的任務在於考慮:「如果 D 則 3」對所有這些卡片來說是不是都正確?一般的運用方式是思考每一條推理是不是遵守條件連接詞「如果……則」的真值表。這個表顯示該條件句只有在一個情況下是假的:當前件為真,而後件為假(也就是說真值表上的 P 為真而 Q 為假)。
下面是條件連接詞「如果……則」(它的象徵符號為「→」)的真值表:
為了讓你對這個表的正確性有具體的想法,請看這個例子。我朋友說:「如果你經過賣菸的店,幫我買包菸。」我答應了。
(1)如果我經過賣菸的店(P 為真),而且我買了菸(Q 為真),好得很。
(2)如果我沒經過賣菸的店(P 為假),而且我也沒買菸(Q 為假),沒問題。
(3)如果我沒經過賣菸的店(P 為假),但我還是買了菸(Q 為真),我朋友不會怪我!
(4)不過現在假設我經過賣菸的店(P 為真),而且我沒有買菸(Q 為假)。我朋友就會怪我說話不算話。「你經過賣菸的店,可是你沒有買菸。為什麼?」
事實上,那是四個情形中,唯一他能理直氣壯責備我的處境,讓我非得解釋一番不可。
讓我們回到選卡片的遊戲吧。
愛好邏輯學的人士應該會這麼想:「為了知道有沒有遵守『若 P 則 Q』的規定,只要檢查沒有任何狀況是 P 為真(有 D)而 Q 為假(沒有 3)就行了。所以不用翻開有 3 的卡片(Q 為真),不用翻開有 F 的卡片(P 為假)。只要翻開有 D 和有 7 的卡即可。如果 D 的背面不是 3,或 7 的背面是 D,那麼這些卡片就不能證實『如果 D 則 3』。」
看起來好簡單!

可是實驗結果奇慘無比。失敗的比率很可觀16!
接受實驗的對象,儘管在學校修過邏輯課程,但幾乎全都選了 D 卡,或是 D 卡與 3 卡,而應該選擇的卻是 D 和 7。大家可能會想,要是能表達得更具體,使用一般人比較熟悉的例子,結果應該會比較好。可是具體的表達方式也改變不了結果。當實驗敘述換成「去國家體育場」和「坐郊區快車」時,失敗的比率還是一樣高。
對於規範,我們好像比較敏感
然而,當任務的表達方式使用允許或禁止的字眼,結果有明顯的改善。例如:「我們想知道在這家咖啡店,大家有沒有遵守十八歲以下禁止喝啤酒的規定。」

第一張卡是「二十五歲」,第二張「可口可樂」,第三張「十六歲」,第四張「啤酒」。
近百分之七十五的實驗對象選出了正確的卡片:「十六歲」(為了檢查背面是不是「啤酒」),以及「啤酒」(為了檢查背面是不是「十六歲」)17。
另一方面,當我們用承諾或社會交換的字眼,結果也很好:「我那篇關於模組巨集的論文,如果你能給我一個好點子,我就請你吃大麥克。」18
總之,當任務以描述的字眼表達時,實驗對象的表現很差;要是以義務性的字眼表達,表現就很棒。
怎麼解釋這種結果?科斯米德絲認為答案很明顯,是演化心理學掌握了關鍵:我們有偵測「騙徒」的模組,意思是指那些想要從人際合作中享受好處,又不奉獻一己心力的人(想一想大家去野餐都會避免邀請的那些人,他們來時兩手空空,還把三明治一掃而光)19。正因為我們有這樣的模組,所以選卡片的遊戲內容與義務有關時,我們才會表現得又好又迅速。該理論還說,今天我們之所以具有這個模組,是由於它對我們的祖先而言非常實用,他們需要迅速辨認誰是人際合作中不應該信賴的人。
這個解釋至少招來了兩點批評:
- 假定我們對義務性條件句的掌握能力,足以證明我們有叫做「騙徒偵測」的模組,那麼依此類推,我們對描述條件句的掌握能力,代表我們不具有古典邏輯的模組。這表示我們的心智運作並沒有完全模組化。或許會有佛德式的「中央」系統。這正是模組巨集之友想否認的一點。
- 根據佛德的說法,外圍系統要能迅速、自動地運作,唯一的條件是,它只對特定類別的刺激(stimuli)有感覺(例如語言的聲音,可以將聲流切割成句子的模組)。至於騙徒偵測模組,刺激它的是什麼?應該會涉及某種社會交換,但似乎必須具有篩選的濾網,從所有可以觀察到的人類行為中,篩選出具社會交換性質的行為。這樣的濾網是否也是模組?如果它不是模組,偵測騙徒的過程就不是完全的模組化,或者說不是從頭到尾整個過程都是模組化。然而這張濾網不能藉由定義來讓它模組化,因為它的任務是一般性的:從整體論的取向去篩選原始訊息,而不是產生這些訊息20。 玩遊戲和y8,放鬆,玩得開心。 玩馬里奧的 Y8 最受歡迎的網絡遊戲集合y8
圍繞模組所進行的爭論,是否只屬於用字上的爭辯?
據我所知,沒有任何心理學家給模組巨集做出嚴格的定義。捍衛它的權威人士認為,只要具備一定程度的功能特殊性就足以合理討論「模組」21。他們通常會建議削弱佛德對模組的辨認標準,因為他們認為這些標準過於嚴苛。
不過,如果成為模組不用滿足佛德所有的標準,如果具有某種程度的功能特殊性就足以合理稱為「模組」,那麼,當然,什麼事都可以看成是模組,那是佛德絕對不會接受的說法!
由於對模組並沒有共同認可的辨認標準,我看不出模組巨集的擁護者與反對者兩造之間的衝突要怎樣才能化解。基本上,模組問題引起的爭吵,不少是因為反對佛德的人士在面對這些模組的判定標準時,表現出擺盪不定的矛盾態度。有時他們承認佛德的標準有理,認為中央系統以這些標準來看,只有某些部分是模組化的。有時他們質疑這些標準,說中央系統是模組化的,但「模組化」的定義比較寬鬆。
道德本能難道並不存在?
有些學者希望藉由道德模組的存在,為道德感理論辯護,目的是重建這個理論;其中,海特屬於鬥志最高昂的學者之一22。他不同意給予模組嚴格的定義。他不認為任何心理運作都必須表現出佛德給出的所有模組標準,才能稱為模組。
不需要對模組提出嚴格要求的這一點,我個人並不反對,但我覺得,如果按照海特的構想,很難在道德反應的兩個部分之間做出精確的區別,一邊可以稱作「自發性」的部分,另一邊是學來的或經過思考的部分。確實,對於比較不嚴格的模組構想,我們完全可以構思出一些部署,它們不像感官部署那麼難以讓信念或知識滲入,但在功能上又足夠特殊化,可以被視為模組。
然而一個不怎麼嚴格的模組構想,是否還可以在我們的道德反應中,區別出什麼是來自道德直覺的反應,什麼是有條理的道德思考結果?如果道德模組的運作和感官模組不一樣,也就是說它不是自主發生,而且不是完全獨立於信念與理性之外,那麼在面對假定為道德反應時,我們要怎麼區別直覺的部分,以及來自學習與思考的部分?
而且,如果不可能區別道德判斷的這兩個面向,又怎麼證明我們的某些道德反應是自然的、與生俱來的和本能的?
注釋:
- Nurock, Sommes-nous naturellement moraux ?, op. cit.
- Jesse J. Prinz, « Is Morality Innate ? », dans Walter Sinnott-Armstrong, dir., Moral Psychology, vol. 1, The Evolution of Morality : Adaptations and Innateness, Cambridge, Mass., The MIT Press, 2008, p. 367-406.
- Bjorklund, « Social Intuitionists Answer Six Questions about Moral Psychology », op. cit.
- Jesse J. Prinz, « Resisting the Linguistic Analogy : A Commentary on Hauser, Young and Cushman », dans Walter Sinnott-Armstrong, dir., Moral Psychology, vol. 2, op. cit., p. 157-179.
- Nurock, Sommes-nous naturellement moraux ?, op. cit.
- Doris, Lack of Character. Personality and Moral Behavior, op. cit.
- Jerry Fodor, La modularité de l’esprit (1983), trad. Abel Gerschenfeld, Paris, Minuit, 1986.
- Ibid.
- Jay Garfield, « Modularity », dans Samuel Guttenplan, dir., A Companion to the Philosophy of Mind, Oxford, Basil Blackwell, 1994, p. 441-448.
- Dan Sperber, « Défense de la modularité massive », dans E. Dupoux, dir., Les langages du cerveau, Paris, Odile Jacob, 2002, p. 55-64.
- Jerry Fodor, « Pourquoi nous sommes si doués dans la détection des tricheurs », appendice à L’esprit, ça ne marche pas comme ça (2000), trad. Claudine Tiercelin, Paris, Odile Jacob, 2003.
- 以下分析出自我的論文:« Ils voient des modules partout », dans Le rasoir de Kant et autres essais de philosophie pratique, Paris – Tel-Aviv, Éditions de l’Éclat, 2003, p. 161-187。
- Leda Cosmides, dans « The Logic of Social Exchange », Cognition, 31, 1989, p. 187-276 ; Leda Cosmides et John Tooby, « Cognitive Adaptation for Social Exchange », dans J. Barkow, L. Cosmides et J. Tooby, dir., The Adapted Mind, Oxford, Oxford University Press, 1992, p. 163-228.
- George Botterill et Peter Carruthers, The Philosophy of Psychology, Cambridge, Cambridge University Press, 1999, p. 109-111.
- Ibid., p. 110.
- 根據平克(Steven Pinker)的說法,介於百分之九十至百分之九十五之間,Comment fonctionne l’esprit humain ? (1997), trad. Marie-France Desjeux, Paris, Odile Jacob, 2000, p. 358;根據波特里(George Botterill)和卡魯瑟斯(Peter Carruthers)的說法,介於百分之七十五至百分之九十之間,The Philosophy of Psychology, op. cit., p. 109。
- R. A. Griggs et J. R. Cox, « The Elusive Thematic-Materials Effect in Wason’s Selection Task », British Journal of Psychology, 73, 1982, p. 407-420.
- Cosmides, « The Logic of Social Exchange », op. cit.
- Ibid. ; Cosmides et Tooby, « Cognitive Adaptation for Social Exchange », op. cit.
- Fodor, « Pourquoi nous sommes si doués dans la détection des tricheurs », op. cit.
- Lawrence A. Hirschfeld, introduction à L. A. Hirschfeld et Susan A. Gelman, dir., Mapping the Mind : Domain Specificity in Culture and Cognition, Cambridge, Cambridge University Press, 1994.
- Haidt et Joseph, « The Moral Mind : How Five Sets of Innate Intuitions Guide the Development of Many Culture-specific Virtues and Perhaps Even Modules », op. cit.

本文摘自《道德可以建立嗎?:在麵包香裡學哲學,法國最受歡迎的 19 堂道德實驗哲學練習課》,臉譜出版。