為什麼要研究「電腦視覺」?
「電腦視覺(computer vision)」是研究怎麼讓機器「看」這個世界。在相機、手機、監視器、行車紀錄器等設備無所不在的今天,人類社會中的視訊資料量,前所未有地巨大。中研院資訊所特聘研究員廖弘源與團隊,教電腦懂得偵測、識別、分析這些影像訊息,進而做出判斷或行動,如此可衍生各種重要的應用,如人臉辨識、物件偵測、車輛追蹤、街景分析等。
輕按快門,相機可以快速找到人臉對焦;機場快速通關窗口,機器能在幾秒鐘之內認出你是誰;裝一台攝影機,就可以計算某段時間內有多少人車經過……「電腦視覺」加上「機器學習」技術的進步,讓我們的生活更加安全及便利。
不過,電腦可不是一開始就這麼聰明的。

教電腦看世界 特徵辨認第一課
電腦「看」世界的方式,和你我很不一樣。在我們眼中,一張圖畫裡可能有人物有風景。但在電腦「眼」中,卻只是幾萬幾億個不同顏色的小點(其實就是像素,pixel),以某個順序排列起來而已。


中央研究院資訊所特聘研究員廖弘源,窮畢生之力,都在教電腦怎麼「看」世界:從 0 與 1 組合成的數位世界中,找出各種「特徵」、並據此識別出特定的物件,進而判斷視訊資料的意義。
比方說,媽媽今天燙了個捲捲頭回家,爸爸可能會一時之間認不出來,但電腦依然能辨認這位捲髮女士是媽媽,因為五官並沒有改變。廖弘源和研究團隊在 2001 年發表的論文,探討此一問題,證明「五官特徵」才是電腦辨識人臉的依據,而非五官之外的髮型、衣著、首飾等,此知識讓業界的臉部辨識系統發展地更精準,也成為這領域近廿年來必讀的文獻之一。
以「識別」與「比對」為核心,電腦視覺延伸出很多用途。廖弘源和研究團隊廿多年來開發出了多項創新技術,像是人臉和車牌的辨識系統,現在已是治安保全的重要利器;而數位檔案加上「雞尾酒浮水印」,則可以防範辛苦的智慧結晶被盜用。
妙手回春 老相片老電影重獲新生
2006 年起,廖弘源接手另一項艱難任務:「數位典藏與數位學習國家型科技計畫」。面對龐大的數位典藏檔案,首要工作就是快速有效地判讀、註解、並擷取多媒體內容。多媒體資料不只圖片,還包括影片。影片等於是一秒鐘 30 張圖片串接在一起,再加上聲音,資訊量非常龐大,因此分析難度,跟簡單的圖片不可同日而語。
另外一個大難題是,許多珍貴的老膠捲,有的被蟲蛀、有的甚至發霉了,眼看就要損毀。還好,廖弘源研究團隊成功打出一記「還我漂亮拳」!一連串視訊篡改(video inpainting)的研究,應用在數位修補技術上,成功幫受損的照片或影片「回春」。
先要能「篡改」,才有能力「修復」。
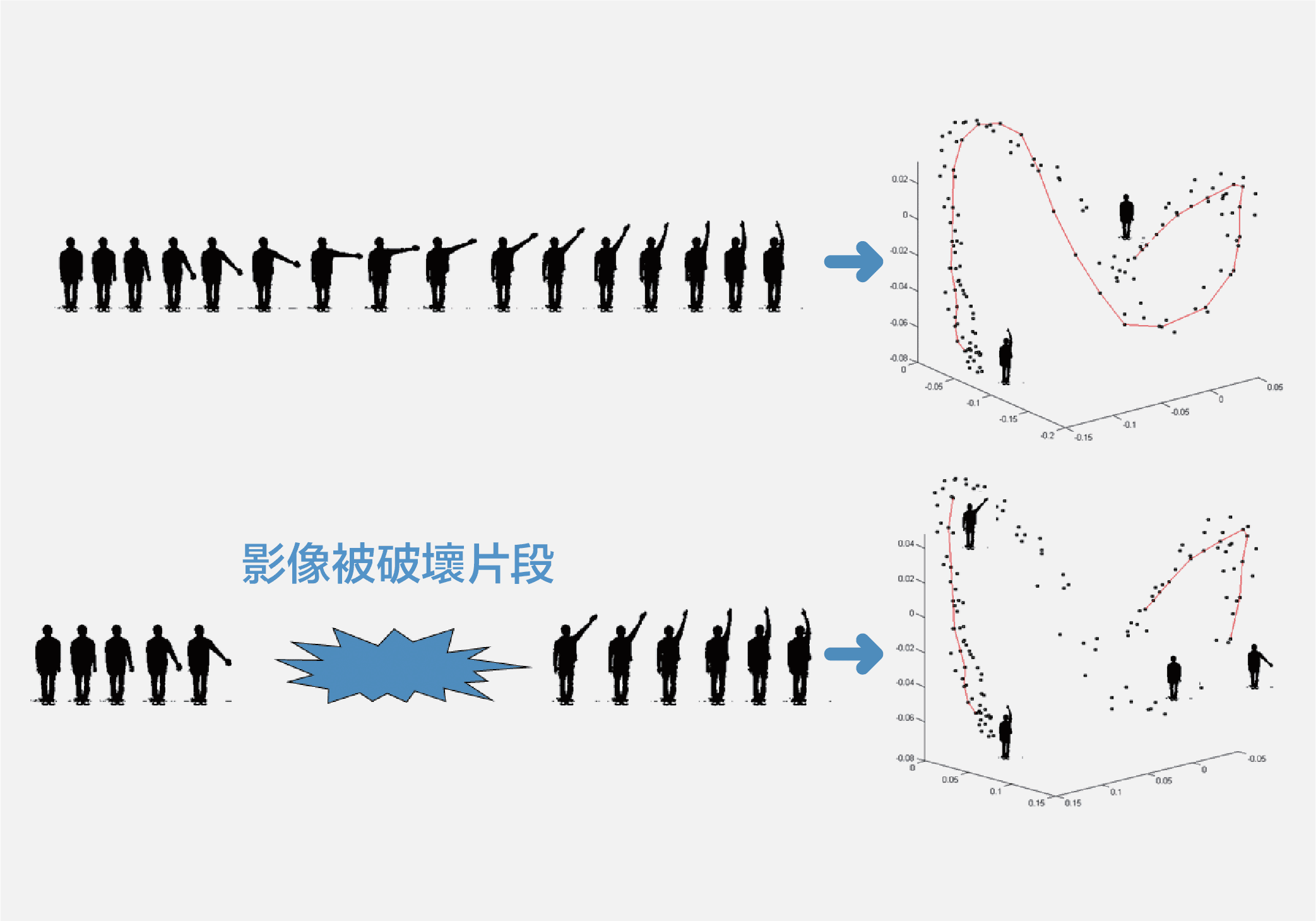
什麼是視訊篡改?目的不是要捏造不存在的歷史、或是製造虛構的畫面,但透過「無中生有」的原理,卻可以還原已經被破壞的元素。像下圖照片所示,原本斑駁陳舊,但電腦程式可以自動擷取摺痕周邊的影像資訊,用類似「模擬」的方式,產生出原本不存在於照片上的元素,把缺損給填補起來。

要修補動態的影片更加困難,廖弘源團隊做出了領先世界的創新研究,採用一種 ISOMAP 技術,以非線性的方式降低維度,不但減少了影片資料運算所需的記憶容量,還能用空間的轉換,填補上被破壞的片段,讓動作看起來自然而連續。許多發霉的老膠捲、經典電影或相片,在這項技術之下,重獲新生。
人工智慧當道 電腦視覺技術突飛猛進
以上所有研究與技術,在 2012 年遇到了一個重大分水嶺,那就是「深度學習(deep learning)」技術的應用。這是一種類神經網絡研究,也就是用數學模型去模擬生物中樞神經的結構和功能。
早期,這樣的研究受限於電腦運算速度,隨著電腦效能大幅提升,深度學習的成熟也一日千里。日前喧騰一時的 Google Alpha Go ,就是藉由輸入了無數的棋譜讓電腦進行深度學習,選出最可能獲勝的落子位置,逐一擊敗各國頂尖職業圍棋選手。
而在電腦視覺領域的國際盛會──大規模視覺辨識競賽(Large Scale Visual Recognition Challenge, ILSVRC),主辦單位提供 1000 類超過 120 萬張的影像,讓參賽團隊設計的程式去判斷類別。 2010 年首次舉辦時,表現最佳的系統錯誤率仍高達 28% 。但來到分水嶺的 2012 年,透過深度學習技術,錯誤率大幅降低到 16% 。 2015 年更是一舉突破人類極限,錯誤率達到 3.7%(人眼辨識的極限是 5%),正式宣告,電腦視覺比人類更精準的時代來臨。
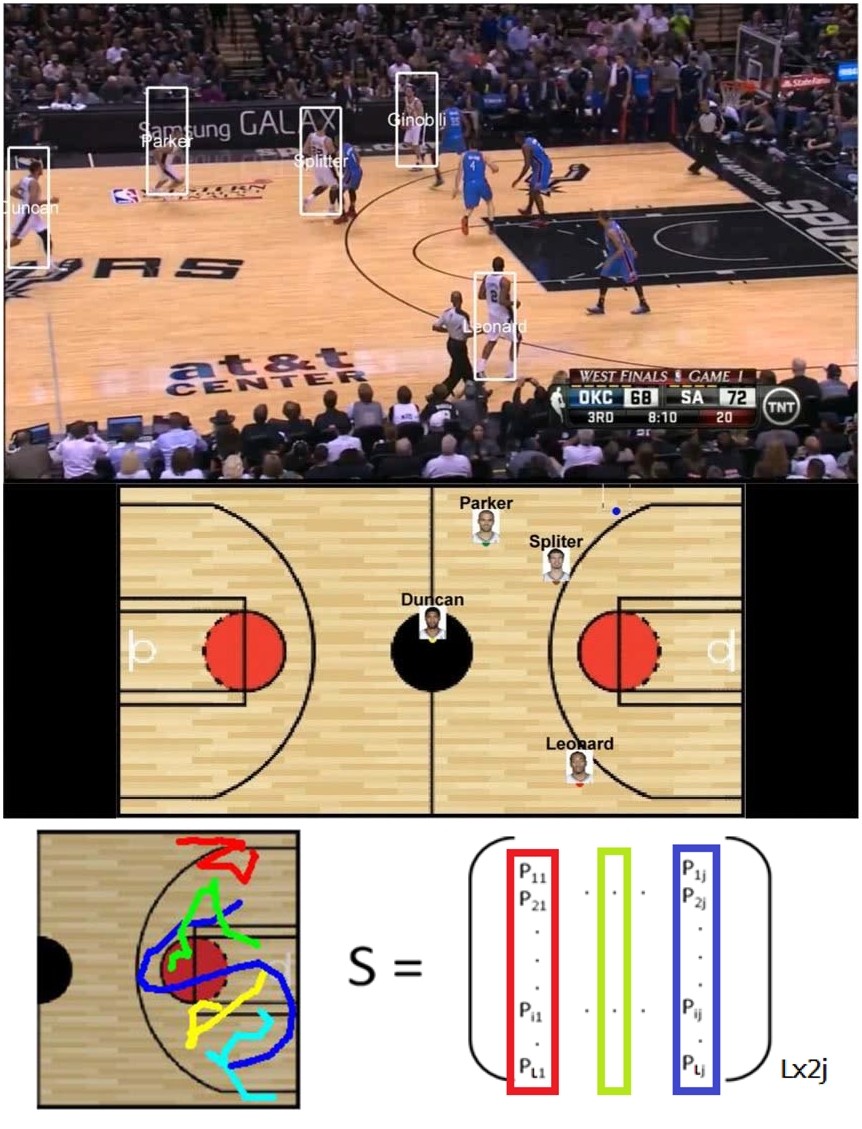
廖弘源的研究團隊,也著力於此,開展了兩項創新的研究。第一個,是「籃球進攻戰術分析」。電視轉播的球賽,常聽球評或教練,戰術分析得頭頭是道,未來,透過深度學習,可以讓電腦直接從比賽的影片中,球員跑動的軌跡,就判讀出這一波進攻是打什麼戰術。
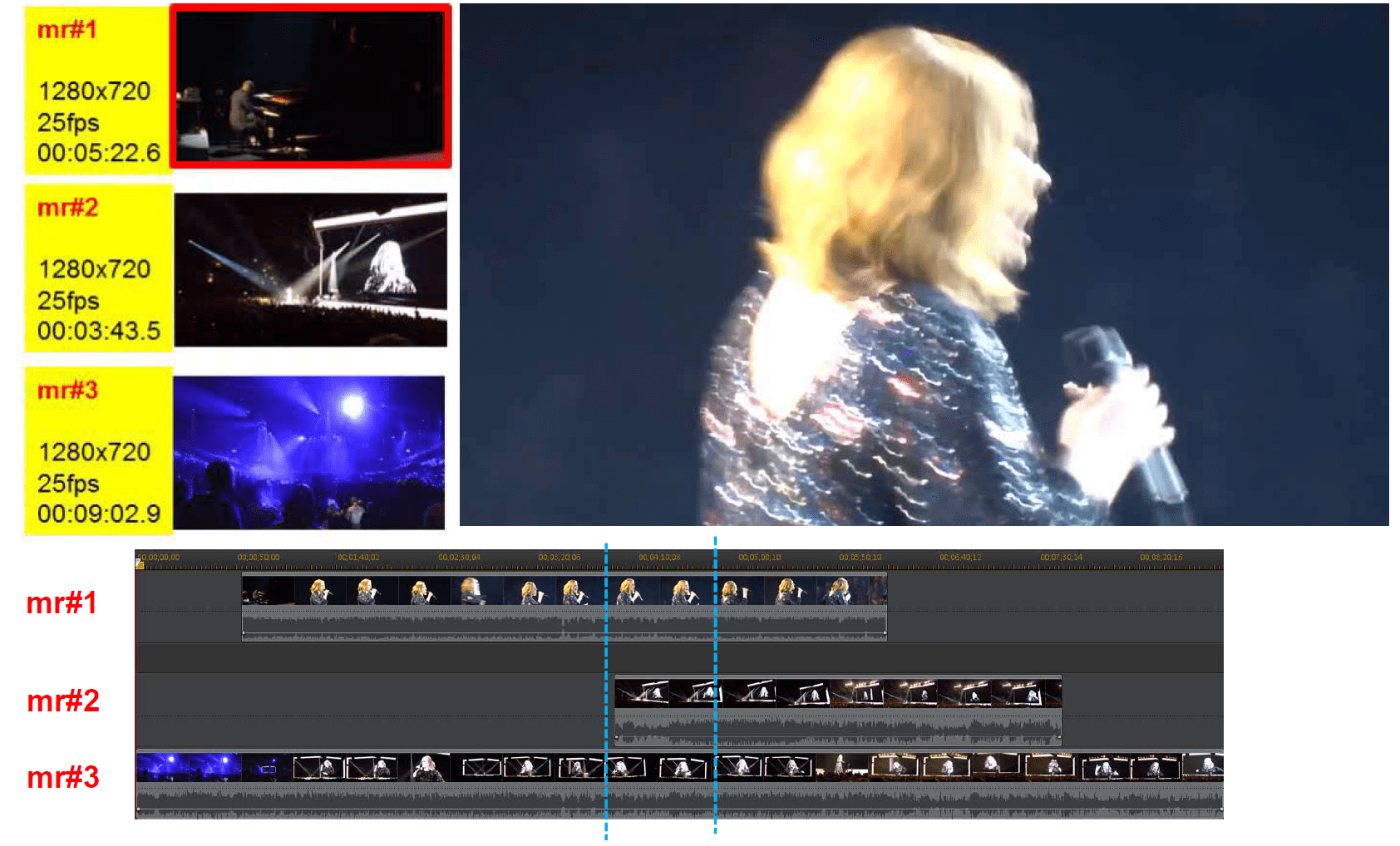
另一個研究則是「演唱會片段自動拼貼(mashup)」。一場演唱會,可能有數百個粉絲,從不同角度、不同距離,拍下了不同片段,上傳到 YouTube 上。那麼,有沒有可能,讓電腦自動挑出這些片段,然後重新剪輯成高品質的完整演唱會影像呢?這項大工程有許多問題,等著廖弘源研究團隊一一克服。
他們先用深度學習技術,讓電腦分辨影像中的不同物件(歌手、舞台、樂器、觀眾等),接著再用另一套模式(Error-Weighted Deep Cross-Correlation Model, EW-Deep-CCM)對影片的每一個鏡頭進行分類,辨認出是遠景、中景、近景、或是特寫。然後還要比對音訊,整理出影片的正確時間順序。最後,才依照順序、分鏡邏輯、和情緒鋪陳,組合出最佳的影片。
為了「教」電腦分析這些資訊,廖弘源笑稱,自己看了無數的籃球影片,從不會打球變成了戰術大師;看了幾百場演唱會,也讓他從音痴化身成音樂總監。受訪時,廖弘源神采奕奕地談著這些研究,言談中除了自豪,更多的是一種身為「科學家」的使命感,強調無論做什麼研究,要當具有開創性的「科學家」,而不只是依循既定方法的「工程師」。
人類持續進步,電腦也是。我們過去總認為,電腦是工具,只能幫我們處理機械化的工作。但廖弘源博士兩個最新研究之中,都包含著非常複雜的深度學習運算技術,若研發成熟後,人工智慧在影片處理上的技巧,將會突飛猛進。或許,「電腦藝術家」誕生的一天,指日可待!
延伸閱讀:
- 廖弘源的個人網頁
- 〈虛實世界的串聯者與守護者〉第二十三屆東元獎科技類,廖弘源受訪報導
- 〈我在中研院的第二個十年:多媒體研究與數位典藏〉演講
- L. F. Chen, H. Y. Mark Liao, (2001) Pattern Recognition, 34, 1393-1403.
- C. W. Su, H. Y. Mark Liao, H. R. Tyan, K. C. Fan, and L.-H Chen, (2005), IEEE Trans. Multimedia, 7, 1106-1113.
- C. S. Lu, S. K. Huang, C. J. Sze, and H. Y. Mark Liao, (2000), IEEE Trans. Multimedia, 2, 209-224.
- H. Y. Sean Lin, H. Y. Mark Liao, and J. C. Lin, (2007), IEEE Trans. Multimedia, 9, 46-57.
- C.J. Sze, H.Y. Mark Liao, and K.C. Fan, (2001), IEEE Trans. on Image Processing, 10, 296-306.
- 執行編輯|黃楷元;美術編輯|張語辰
![]()
本著作由研之有物製作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位
































-200x200.jpg)