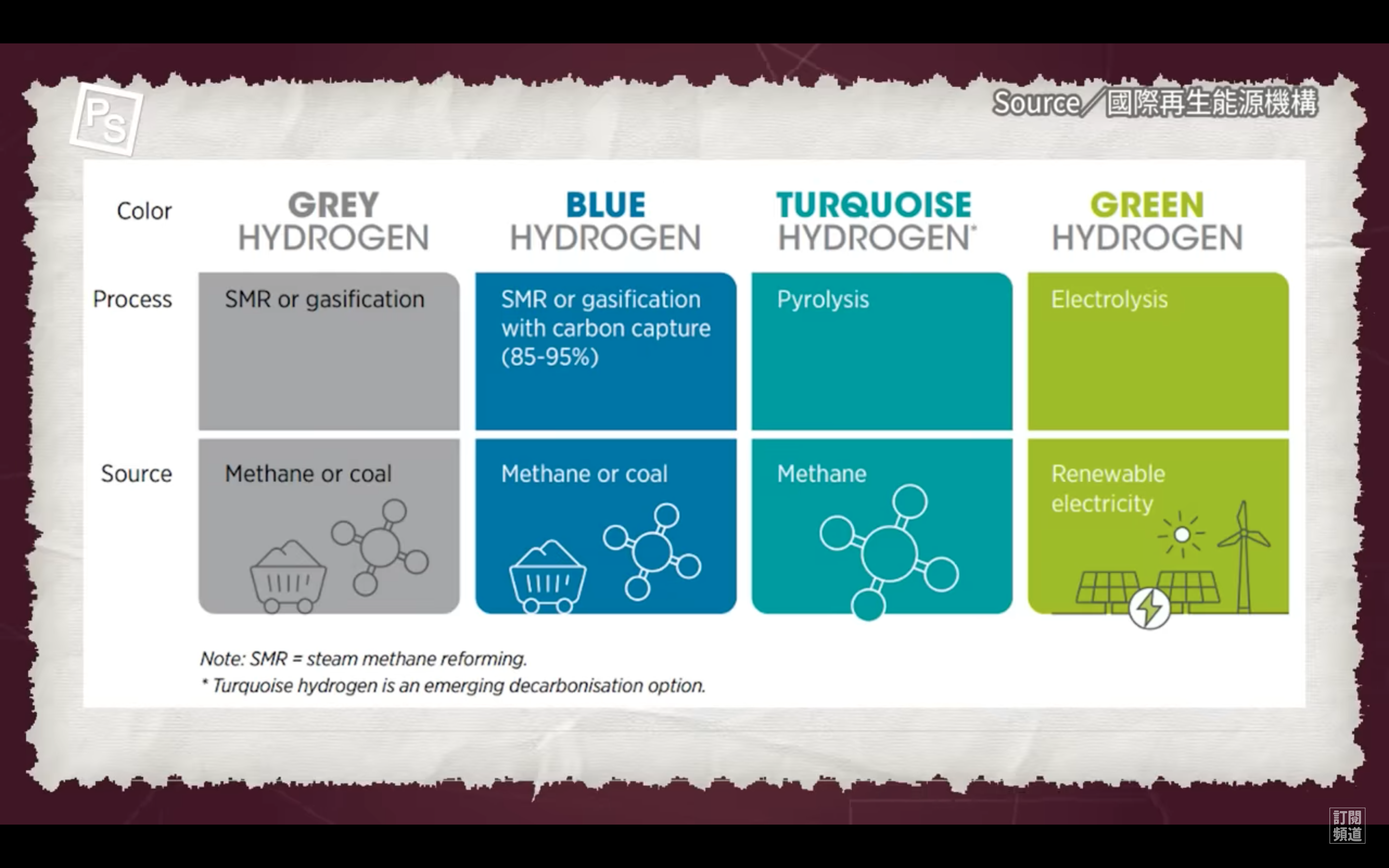
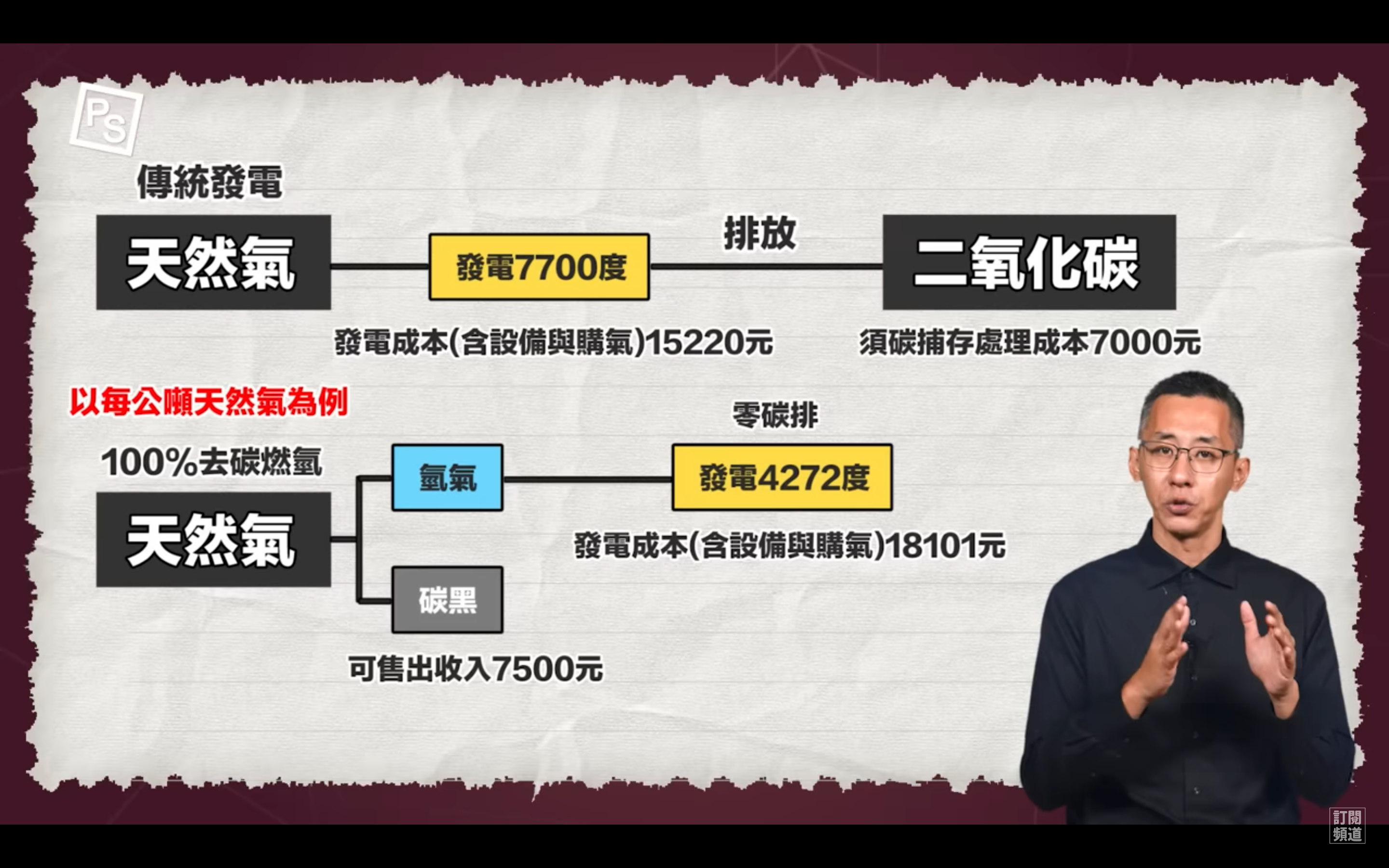
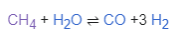1992年的五月,178個國家在巴西的里約熱內盧(Rio de Janeiro)開會討論有關地球環境的問題;雖然在這之前已經有一些成功的例子(例如1987年簽訂的有關臭氧層的保護的協議);但很遺憾的是,1992年在里約熱內盧的地球峰會被不信任的氣氛所籠罩。雖然在前兩年世界各國已經開始在草擬有關保護地球生物多樣性以及減緩氣候變遷的條約,但在接近里約的會議開議前,已開發國家與第三世界國家,對於該由誰來負擔保護環境的費用這件事上,開始出現意見分裂的情況,使得整個會議功敗垂成。最後,所有這些國家決定不要讓大家空手而回。於是他們簽了生物多樣性公約(Convention on Biological Diversity)、氣候變化綱要公約(Convention on Climate Change),以及Agenda 21,也就是後來的防治荒漠化公約(Convention to Combat Desertification)。無論是生物多樣性的保存、氣候變遷的減緩,或是沙漠化現象的防治,仍然是非常複雜的問題。在當時,雖然會議被不信任的氣氛籠罩,但由於簽署了這三個公約,有些人仍然信心滿滿。光陰似箭,歲月如梭,一晃眼20年過去了,究竟這三個公約有沒有認真執行呢?我想大家都很好奇,更或許一點好奇心也沒有,因為這些年來感覺上似乎大乾坤變得越來越不好,四大(地、水、火、風)越來越不調,但是…到底大家作得怎麼樣?有沒有「寸進」?最近(6/20-22)又要在里約熱內盧辦理地球峰會了(Rio+2),《自然》(Nature)雜誌檢視了人類要呈給地球的成績單(1),很遺憾的,20年可以讓一個小孩變成大人,但是世界各國卻浪費了20年而毫無寸進。我們就來看看我們呈給地球的成績單吧!第一頁、 氣候變化綱要公約 :死當
看到這樣的成績單的第一頁,真的讓人無言!當年各國同意讓已開發國家多承擔,同時也要協助開發中國家;但是隨著已開發國家的經濟每下愈況,開發中國家的經濟突飛猛進,已開發國家變得不願意多承擔,並且指出中國(尚未加入京都議定書)已經是世界第一大的碳排放國;但中國則反唇相譏說,他們的每人碳排放量(per-capita emission)並不算高,反而是美國的每人碳排放量高得嚇人,但美國也沒有執行京都議定書,這樣叫中國要如何認同呢?好不容易2009年在哥本哈根的氣候峰會中,中國、巴西跟南非同意了要降碳排放量;而2010年的德班(Durban, South Aferica)更進一步同意要在2015年將已開發與開發中國家的碳排放量都列管。今年的11月,各國會針對這個議題在多哈(Doha, Qatar)開會並起草新的公約。