

大多數美洲原住民的祖先本來住在西伯利亞,在冰河時期海平面較低,白令海峽還是白令陸橋時,從東北亞前進美洲,隨後分佈到整個美洲大陸,成為美洲最早的居民。早期美洲人的遺骸很少,其中8500年前的肯納威克人(Kennewick Man)相當特殊。
古今美洲居民,腦袋不一樣
肯納威克人是成年男生,1996年在美國華盛頓州被發現。風景優美的華盛頓州也是《暮光之城》主角貝拉的家,是個有吸血鬼又有狼人的鬼地方。

從時間與地點看來,肯納威克人怎樣都該是美洲原住民。型態分析卻顯示,他的頭骨不像現在的美洲原住民,反而更接近日本的阿伊努人,或是大洋洲的玻里尼西亞人。但比起型態,要知道肯納威克人的血緣來歷,DNA分析會是更可靠的工具。
8500年前的古印第安人
肯納威克人整個基因組在2015年獲得[1],是繼2014年「Anzick-1」以來[2],第二個成功取得的美洲古代基因組,這個研究也成為去年《Science》雜誌的「年度科學突破」之一[3]。他的粒線體單倍群(haplogroup)是X2a,Y染色體單倍群是Q-M3,兩者在美洲原住民中都算常見。
比較整個基因組,世界上與肯納威克人在遺傳上最接近的,是古代與現代北、中,南美洲的原住民,儘管他們頭骨型態不太一樣;相對的,阿伊努人及玻里尼西亞人雖然頭骨形態類似,遺傳上卻差異較大。這表示血緣上肯納威克人的確是美洲原住民。
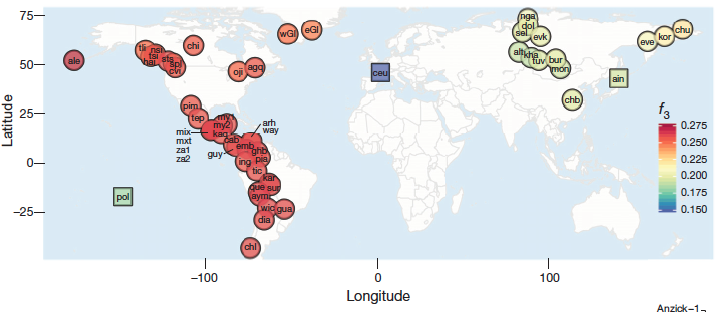
為什麼形態與遺傳不一致?論文推論,也許是因為族群內個體形態差異太大所致。美洲原住民族群非常大,單一個體有機會落在多數人的範圍外頭,例如北達科他州的Arikara族,頭骨形態也更接近波里尼西亞人,然而他們是貨真價實的印第安人,由此觀之,肯納威克人所屬族群的頭骨形態,實際上未必真的處於現代的美洲原住民之外。
美洲原住民的大西部遷徙史
肯納威克人提供的遺傳資訊,對釐清美洲原住民的遷徙與遺傳史很有幫助。當初美洲原住民的祖先,應該是先沿著太平洋側的海岸前進,一批人一路往前走進中、南美洲,形成後來的馬雅人等族群;另一批人改道內陸,散居北美洲,還有些人留在太平洋側這邊,成為後來的北美印第安人。
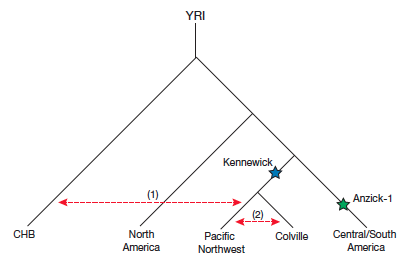
親緣關係上,跟世界其他族群相比,整個美洲的原住民自成一群,這一群又可再細分成三大群:北美、太平洋西北地區(Pacific Northwest)、中與南美洲。太平洋西北地區這群雖然位於北美,遺傳卻比較接近中與南美洲的族群,跟東邊的北美族群差異較多。
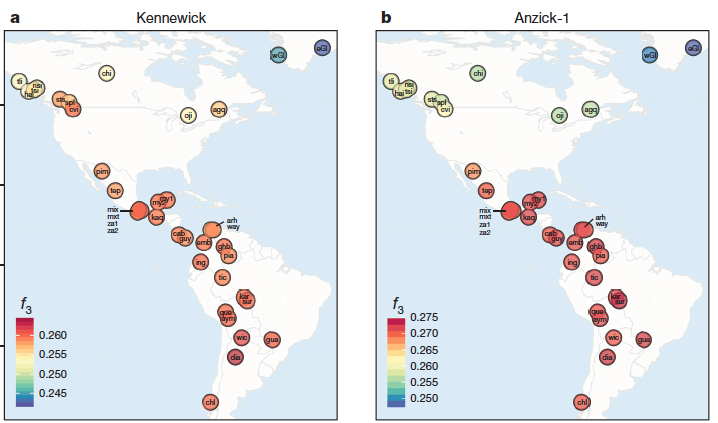
有意思的是,地理位於北美蒙大拿州的Anzick-1,遺傳卻更接近今天中、南美的原住民,可見12600年前時,人群的位置跟現在還不同,或許仍在大風吹。肯納威克人位於北美西北方,遺傳也跟現在附近的族群最接近,例如宣稱擁有肯納威克人主權,並提供遺傳樣本參與本次研究的科爾維爾(Colville)部落。這似乎意謂,8500年前美洲原住民的分佈與現在已大致吻合。
主權爭議,再見法院
等等,「宣稱擁有肯納威克人主權」是怎麼回事?宣稱擁有釣魚台或是南沙的主權很好理解,但死人骨頭怎麼會有人想要,莫非有什麼神奇魔力,例如隱藏了古老的狼人變身奧秘嗎?
好幾個部落主張,肯納威克人是在美國陸軍工兵隊(US Army Corps of Engineers)的土地上發現,根據「美國原住民族墓穴保護及歸返法案(Native American Graves Protection and Repatriation Act)」,印第安人有權要求歸還相關的遺物或遺骸[4]。對印第安人血淚史稍有接觸的人,必能體會這法案對他們的意義,然而對科學家來講,肯納威克人的學術價值又何其重要!
雙方對簿公堂多年,爭奪肯納威克人所有權。之前原住民方由於無法證實,與肯納威克人間確有關係而敗訴,新的遺傳學證據,無疑將提供他們繼續在法院奮鬥時,更有力的支援。
全都來自西伯利亞!
新研究發表,往往幾家歡樂幾家愁。肯納威克人DNA揭曉後,印第安人開心了,但梭魯特(Solutrean)假說卻喪失一大有力證據。這假說主張距今13000年的北美克洛維斯(Clovis)文化,跟歐洲約2萬年前的梭魯特文化有關,因此部分美洲原住民的祖先並非來自西伯利亞,而是源於歐洲,跨越大西洋而來[5]。
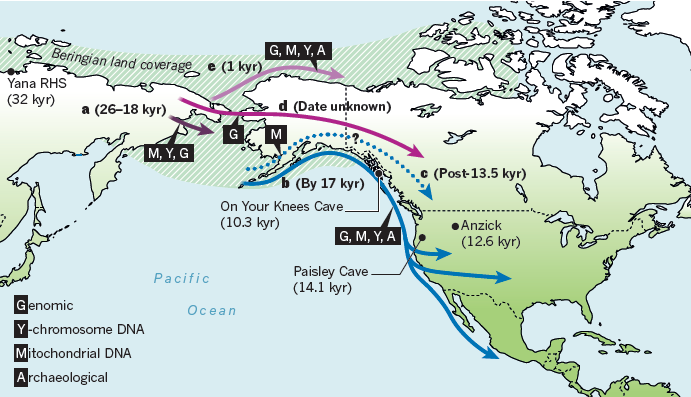
梭魯特假說本來就沒多少學者支持,而且在克洛維斯文化中,唯一的人類遺骸Anzick-1基因組定序出爐後,幾乎已宣告淘汰,畢竟Anzick-1完全看不出源自歐洲的成分。但仍有一個疑點難以解惑,就是粒線體單倍群X2a的來歷[6]。
每個人都有由母系代代傳承的粒線體,裡頭DNA自成一格,不與細胞核DNA互換,因此可以依粒線體DNA變異位置不同,定義為各種單倍群(與更細的單倍型),追蹤親戚關係。美洲原住民有五大單倍群A、B、C、D、X,前四者也出現在西伯利亞族群,然而X卻不存在西伯利亞與東亞。
X衍生出的單倍群,幾乎全出現在中東、北非、歐洲,只有X2a位於美洲;多數X2a分佈於北美東方、靠近大西洋側的五大湖區,北美西方相對少見,中、南美洲則完全沒有。在梭魯特假說的支持者看來,這簡直是歐洲與美洲在史前時代,有過跨大西洋直接交流的完美證據。
可惜肯納威克人的粒線體單倍群,正是X2a,而且還是改變最少,X2a最初始的型號。那個時間、那個地點,那個遺傳特徵,都漂亮地補上「美洲X2a從何而來」的缺口。
目前看來狀況像是,單倍群X最早在中東出現,然後少少的人帶著它移居北亞,他們的後代跨越白令到了美洲西北。這群人累積的DNA突變,產生X2a這個支系,最後終於在北美東方繁榮昌盛;然而由於一直人數不多,沿路都沒留下多少後裔,或是某時不幸失傳,所以我們今天在北亞、東北亞、西北美這些地方,都見不太到X2a。
原住民研究的倫理議題
獲取肯納威克人的DNA後,數個學術上的謎團順利解開,歸屬官司卻也將因此重啟。與人相關的研究,永遠不可能擺脫人的羈絆,牽涉原住民時更是如此,目前許多研究美洲原住民的學者已經意識到這點,更加重視與原住民的關係,希望能創造學術研究與原住民權益上的雙贏[7]。
台灣沒有美國原住民族墓穴保護及歸返法案,卻不代表不存在跟美國類似的問題,相關議題值得我們深思。
參考文獻:
- Rasmussen, M., Sikora, M., Albrechtsen, A., Korneliussen, T. S., Moreno-Mayar, J. V., Poznik, G. D., … & Jónsson, H. (2015). The ancestry and affiliations of Kennewick Man. Nature.
- Rasmussen, M., Anzick, S. L., Waters, M. R., Skoglund, P., DeGiorgio, M., Stafford Jr, T. W., … & Poznik, G. D. (2014). The genome of a Late Pleistocene human from a Clovis burial site in western Montana. Nature, 506(7487), 225-229.
- Science 選出2015 年度科學突破,得獎的是…
- Ancient American genome rekindles legal row
- Oppenheimer, S., Bradley, B., & Stanford, D. (2014). Solutrean hypothesis: genetics, the mammoth in the room. World Archaeology, 46(5), 752-774.
- Raff, J. A., & Bolnick, D. A. (2015). Does Mitochondrial Haplogroup X Indicate Ancient Trans-Atlantic Migration to the Americas? A Critical Re-Evaluation. PaleoAmerica, 1(4), 297-304.
- Ancient genome stirs ethics debate
本文亦刊載於作者部落格《盲眼的尼安德塔石匠》暨其 facebook 同名專頁。































-200x200.jpg)





_(20413495092).jpg){kind=link}