通常有名的哈柏太空望遠鏡(Hubble Space Telescope)星系影像,要不是壯觀的螺旋星系,就是邊緣和緩變化的橢圓星系,不過這些通常都是大型星系才有的模樣,瞧瞧右方影像中的星系,有沒有覺得與眾不同呢?因為影像中的主角—洪伯II(Holmberg II,UGC 4305)是不規則矮星系(dwarf irregular galaxy);這類矮星系的外型和型態差異頗大,很難歸類,故直接歸類為不規則星系。而哈柏先進巡天相機(Advanced Camera for Surveys)影像中可見模糊不清的洪伯II星系裡,有著數個巨大且發光的氣體泡泡呢!(譯者註:這個星系幾乎佔滿整個畫面,其中的紅色氣泡結構只是星系中的一部份而已喔!點選此處觀看這個星系的整體外觀影像。)
雖然以規模來論,洪伯II星系是不起眼的矮星系,不過這個星系還是有某些吸引人的特徵。例如它是1950年代洪伯(Erik Holmberg)在M81星系團中發現的9個低表面亮度星系(low-surface-luminosity galaxies)之一,它不尋常的外表為它在赫頓‧阿普(Halton Arp)的特殊星系表(Atlas of Peculiar Galaxies)中贏得一席之地。此外,這個星系還有個極明亮的X射線源,就在影像右上角3個氣體泡泡的中間那個裡;目前有許多種理論解釋這個強力輻射的來源,其中一種理論還提到可能是其中有個正在拉扯周邊物質的中型黑洞(intermediate-mass black hole)哩!不過這些理論有些甚至相互矛盾,讓這個強X射線源的起源仍是個未解之謎。
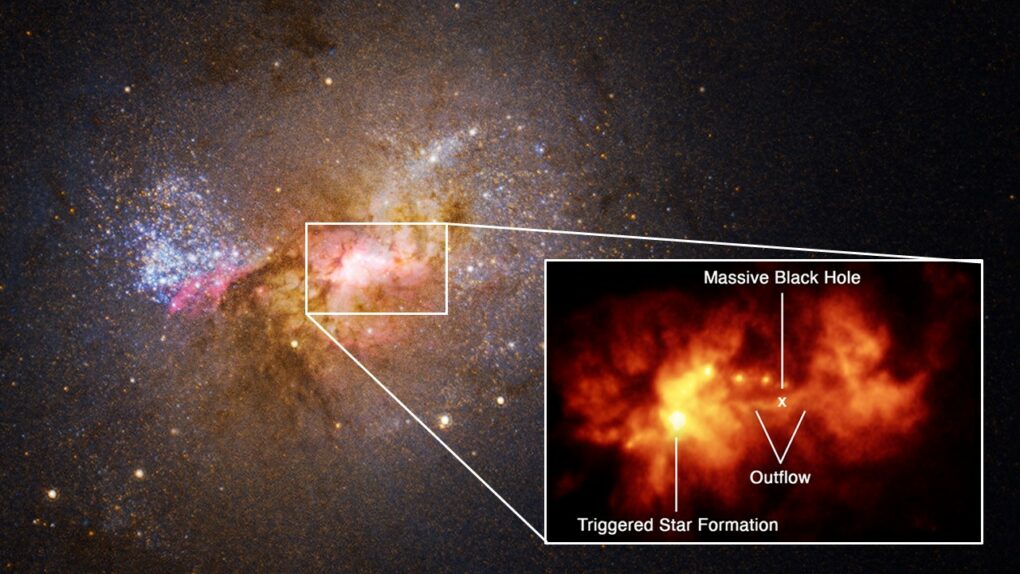
天文學家常用星系的「恆星形成率 SFR」來衡量一個星系的狀態。如果一個星系正在產生許多新恆星(即恆星形成率高),這就是個「生機勃勃」的星系(如左圖的 NGC 4038 / NGC 4039);反之,如果一個星系都只有年邁的恆星,那這就是個「死氣沉沉」的星系(如右圖的 IC 2006)。 圖/Wikipedia|ESO半人馬座 A 星系是經典的活躍星系之一。由星系中心射出的筆直藍色區域,就是超大質量黑洞的噴流。圖/ESA_Multimedia
通常有名的哈柏太空望遠鏡(Hubble Space Telescope)星系影像,要不是壯觀的螺旋星系,就是邊緣和緩變化的橢圓星系,不過這些通常都是大型星系才有的模樣,瞧瞧右方影像中的星系,有沒有覺得與眾不同呢?因為影像中的主角—洪伯II(Holmberg II,UGC 4305)是不規則矮星系(dwarf irregular galaxy);這類矮星系的外型和型態差異頗大,很難歸類,故直接歸類為不規則星系。而哈柏先進巡天相機(Advanced Camera for Surveys)影像中可見模糊不清的洪伯II星系裡,有著數個巨大且發光的氣體泡泡呢!(譯者註:這個星系幾乎佔滿整個畫面,其中的紅色氣泡結構只是星系中的一部份而已喔!點選此處觀看這個星系的整體外觀影像。)
雖然以規模來論,洪伯II星系是不起眼的矮星系,不過這個星系還是有某些吸引人的特徵。例如它是1950年代洪伯(Erik Holmberg)在M81星系團中發現的9個低表面亮度星系(low-surface-luminosity galaxies)之一,它不尋常的外表為它在赫頓‧阿普(Halton Arp)的特殊星系表(Atlas of Peculiar Galaxies)中贏得一席之地。此外,這個星系還有個極明亮的X射線源,就在影像右上角3個氣體泡泡的中間那個裡;目前有許多種理論解釋這個強力輻射的來源,其中一種理論還提到可能是其中有個正在拉扯周邊物質的中型黑洞(intermediate-mass black hole)哩!不過這些理論有些甚至相互矛盾,讓這個強X射線源的起源仍是個未解之謎。



 通常有名的哈柏太空望遠鏡(Hubble Space Telescope)星系影像,要不是壯觀的螺旋星系,就是邊緣和緩變化的橢圓星系,不過這些通常都是大型星系才有的模樣,瞧瞧右方影像中的星系,有沒有覺得與眾不同呢?因為影像中的主角—洪伯II(Holmberg II,UGC 4305)是不規則矮星系(dwarf irregular galaxy);這類矮星系的外型和型態差異頗大,很難歸類,故直接歸類為不規則星系。而哈柏先進巡天相機(Advanced Camera for Surveys)影像中可見模糊不清的洪伯II星系裡,有著數個巨大且發光的氣體泡泡呢!(譯者註:這個星系幾乎佔滿整個畫面,其中的紅色氣泡結構只是星系中的一部份而已喔!點選此處觀看這個星系的整體外觀影像。)
通常有名的哈柏太空望遠鏡(Hubble Space Telescope)星系影像,要不是壯觀的螺旋星系,就是邊緣和緩變化的橢圓星系,不過這些通常都是大型星系才有的模樣,瞧瞧右方影像中的星系,有沒有覺得與眾不同呢?因為影像中的主角—洪伯II(Holmberg II,UGC 4305)是不規則矮星系(dwarf irregular galaxy);這類矮星系的外型和型態差異頗大,很難歸類,故直接歸類為不規則星系。而哈柏先進巡天相機(Advanced Camera for Surveys)影像中可見模糊不清的洪伯II星系裡,有著數個巨大且發光的氣體泡泡呢!(譯者註:這個星系幾乎佔滿整個畫面,其中的紅色氣泡結構只是星系中的一部份而已喔!點選此處觀看這個星系的整體外觀影像。)








































{kind=link}