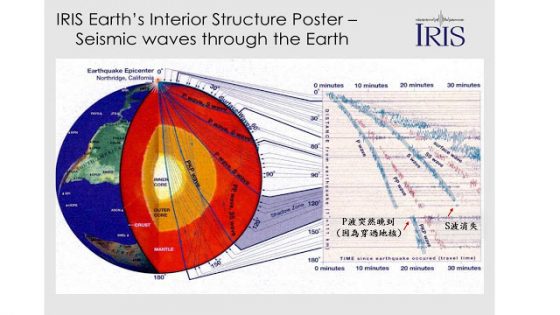
如果我們將地震儀繞著地球一圈擺放,便可發現,在震央距(註 1) 某些範圍沒有 S 波訊號,僅有微弱的 P 波通過,而且震波抵達的時間比預期慢(圖ㄧ)。這便引起地震學家的注意了,畢竟如果地球內部若是均勻一致,S 波又怎麼會消失?到時(波傳到的時間)又怎麼會變慢?
-----廣告,請繼續往下閱讀-----
對科學家而言,往往最感興趣的就是調查「不合理」的事物。1914 年,古騰堡(Beno Gutenberg)從這樣的觀測結果,推測地球內部應該有個「地核」(就如同蛋的蛋黃般)存在,使震波紀錄在地函-地核交界處出現不連續(命名為古氏不連續面,以紀念古騰堡,註 2)。從下方圖一右邊的震波走時曲線(詳見上篇介紹)可以清楚看到這個不連續的位置,筆者以紅色箭頭標示出這個異常位置,可以發現在震央距 143˚~180 ˚ 位置抵達的 P 波到時比預期晚,而且 S 波消失了,這意味著震波通過了另一個構造(事實上就是穿過了地核,當時古騰堡用 P’ 來表示)。遲到的 P 波,代表的是通過地核時「波速變慢」嗎?從觀測結果來說似乎是對的,但也不完全正確,因為介質的變化太大了,事情其實頗為複雜。
圖一、若將地震儀繞地球一圈放,在各地的震波紀錄,可以清楚看到P波及S波傳遞的情形,其中在103˚~143˚(圖中灰色範圍)直達的 P 波和 S 波都消失(綠色波)。圖/作者修改自IRIS
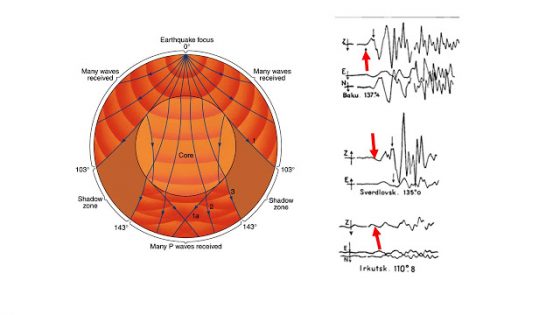
至於「S 波消失」這件事,很明顯的外核(當時認為是地核)是種「S 波無法穿透的物質」。從震央距 103˚ 開始,P 波和 S 波就會打到地核,S 波無法穿過地核而無法被接收;此外根據物理定律,P 波也因為入射角/出射角的偏離而無法被清楚記錄。直到143˚ 出現穿越地球而過的 P 波,我們稱這段範圍為陰影帶(沒有直接傳遞的 P 和 S 波),只會有些許的繞射波(註 2)被記錄到(圖三)。根據古騰堡當時的估算,這個核的深度大概是 2,900 公里,這與現代認為的 2,889 公里,僅有些微的差距。
An explanation o f the P 3 ‘ wave is required, since now it can hardly be considered probable that it is due to diffraction. A hypothesis will be here suggested which seems to hold some probability, although it cannot be proved from the data at hand. We take it . . . that inside the core there is an inner core in which the velocity is larger than the outer core.