


本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位。
- 採訪編輯|蕭歆諺;美術編輯|林洵安
每年 7、12 月,中研院都會發佈對台灣總體經濟的預測,12 月公布隔年總展望,7 月發佈當年修正後的預測數據。但未來未來一直來,變數這麼多,經濟學家是怎麼判斷前景大好或大壞?難道是靠投票、擲骰、丟硬幣?「研之有物」專訪中研院經濟預測小組召集人、經濟研究所兼任研究員周雨田,帶你破解經濟預測的幕後步驟,一窺經濟學家如何推估經濟指標,幫助政府和大眾掌握經濟風向。
經濟預測的影響有多大?差 1% 差很大
一般人聽到「經濟總體預測」,可能很難有具體感覺。預測報告中密密麻麻的各項指標,似乎不會直接影響日常生活。但真是如此嗎?我們與經濟指標的距離,或許比想像中還近。

周雨田解釋,經濟預測很大程度會影響政府決策,舉凡編列預算、稅收增減、大型公共建設計畫等,都奠基在對整體經濟的展望評估。
這些政策看似遠在天邊,其實與生活環環相扣:明顯的如三倍券或紓困方案,讓民眾多了一點小確幸;重大政策如前瞻基礎建設、央行貨幣調節、銀行利率,會影響產業發展與企業進出口成本,也帶動大家最關心的股市行情。
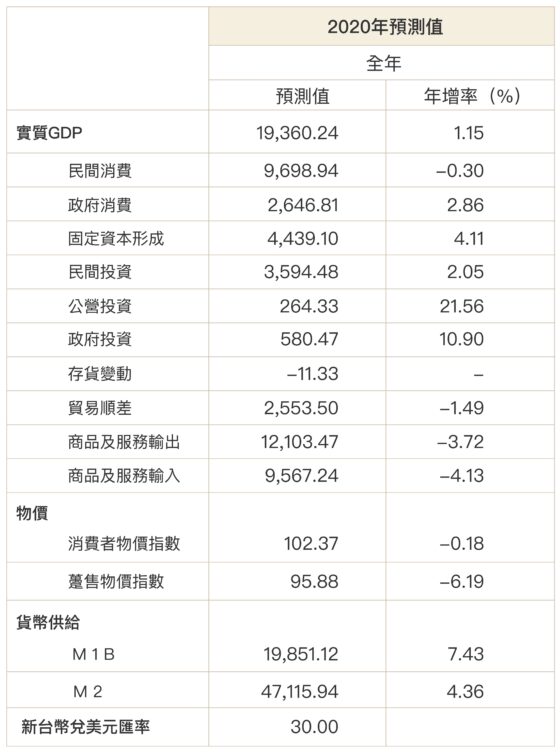
這些數字看似微小,實則影響巨大。經濟成長下修 1%,聽了不容易有感;但台灣一年 GDP 約 19 兆台幣,差 1% 就差了 1900 億元!也難怪每年發布經濟預測時,總會吸引媒體目光。
1.83%?-4%?為何國內外各家預測大不同?
政府主計單位之外,中研院是台灣第一個進行總體經濟預測的機構,早在 60 年代中期由于宗先院士等人首開先河,歷史悠久。
國內其他非官方預測單位還有中華經濟研究院、台灣經濟研究院、台灣綜合研究院和近年加入的中央銀行等;國外重要預測機構則有 IMF、OECD、World Bank、IHS Global Insight 和 Oxford Economics 等機構。此外,一些大型民營金融單位也會提供涵蓋較小範圍的總體經濟預測。
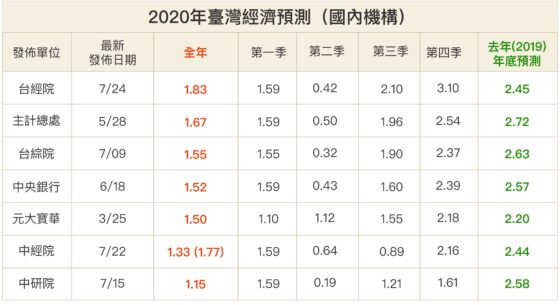
比對各家版本,中研院的預測數字有時較為保守,例如今年各家數據最高達 1.83%,中研院則落在 1.15%。為何同樣是經濟預測,結果卻有不小差距?
周雨田解釋,每個機構有各自的運算模型、方式;作為學術研究機構,中研院相對沒有約束與包袱,比較可以「放得開」,更勇於據實當一隻烏鴉。
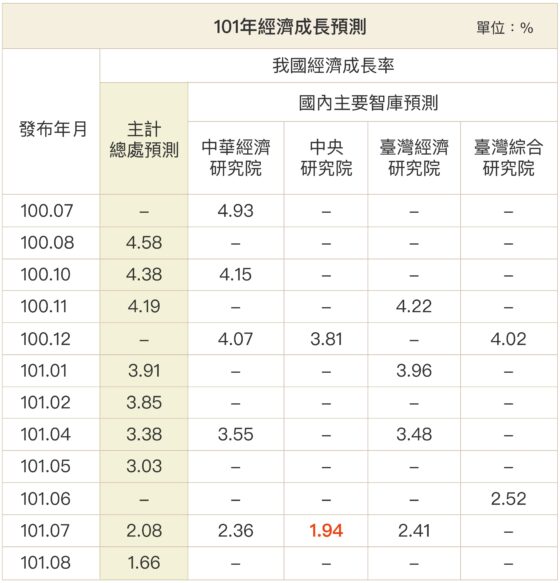
檢視過往紀錄,中研院的預測表現確實平穩,準確度很高。比如 2012 年主計總處曾「連九降」經濟成長率,從 4.58% 一路調至 1.66%;當年 7 月中研院發布的數據為 1.94%,是預測最精準的版本。
儘管有學術上的優勢,他也坦承,相較於其他機構,學術單位對個別產業的細部發展掌握較少。
拆解「經濟預測」四大步驟
整個經濟預測流程,主要包含四大部分:蒐集資料、模型運算、預測討論和對外發佈。
蒐集資料是常態性隨時進行的程序,密集準備期則約需一到兩個月的時間。研究模型使用的是季度資料,大部分來自主計總處,其他還包含中央銀行、財政部、中央氣象局與 IMF 等國內外單位。除了數據,也需要關注重要新聞事件,例如政策施行成效、國際地緣政治發展,進一步評估對各變項的影響。
在模型運算的階段,團隊使用統計分析軟體 EViews 和 GAUSS 進行計量經濟分析,每季都會重新運算數據,反應最新一季資料的影響。
目前使用的預算模型是一個中型規模,共有將近 30 條方程式,涵蓋商品與勞務市場(民間消費、民間投資、出口、進口)、勞動市場(失業率、工資)、價格函數(進口物價、出口物價、國產內銷品物價、消費者物價、核心物價、8 項物價平減指數)、金融市場(股價、匯率、利率、M1B、M2)、及政府財政(稅收)等變項。
台灣經濟結構並非一成不變,運算模型自然也要不斷修正。經年累月的優化下,照理說,預測模型應該愈趨精準。但周雨田解釋,除了經濟結構不斷改變之外,許多影響經濟的因素、程度都難以被具體量化,因此每季得到初步運算結果後,就有賴團隊進一步開會討論與修正。
三個經濟學家有四個看法,我們有七個成員,你就知道會有多少看法!
周雨田笑著說,意見分歧是常態,從不同變數的影響時間長短,到不同政經事件衝擊的程度,不一而足。研究團隊得透過一次次的開會討論、辯證、說服彼此,取得共識,萬不得已才會投票表決。
今年最大的歧見是什麼?周雨田透露,「先前比較大的歧異點是疫情影響。」新冠肺炎剛爆發時,有些人認為疫情仍侷限對岸,不會有過大、過長的影響;另一派則認為兩岸交流頻密,絕不可小覷嚴重性。光是簡單描述,就能想像彼時討論有多熱烈!
但無論共識有多難,經濟指標總是要發佈。7、12 月中研院固定召開兩次記者會,發佈對台灣總體經濟的預測,內容包含經濟成長率、民間消費成長率、進出口成長率、消費者物價指數和失業率等重要指標。
黑天鵝頻頻出現 經濟預測挑戰大
上述每個指標都相互牽動,其中集大成者是「實質經濟成長率」,受到消費、投資、政府購買及淨出口等影響。包括疫情對外貿動能的衝擊,政府紓困與前瞻計畫,都會反映在該指數上。
相比之下,「美金和人民幣匯率會有什麼漲跌?」「央行利率可能調降嗎?」「股市什麼時候跌?現在能不能進場?」這些記者會經常出現的敏感問題,學術上很難有一致的答案,運算模型則不做預測。這在文獻中有個名稱叫隨機漫步模型(Random Walk),增加跟降低的機率基本上一樣,意思就是沒辦法預測。
整體來看,經濟預測中最大的挑戰是什麼?
周雨田認為特別難預測的是「進出口成長率」。他解釋,評估進出口成長率要考量匯率、國內產業發展、國外需求和其他國際情勢等因素,牽涉變數廣。除了變數之間的相互影響,還要考慮影響時間,例如:假設去年貿易變數延續至今,這個影響會長達一季或兩季?
另外,「民間投資成長率」也是一大難題。因為投資牽涉景氣循環起伏,但任何經濟預測中,最難掌握的就是轉折點!景氣何時到谷底?是不是要開始反轉了?都是經濟學家的頭痛挑戰。
相較之下,較好預測的有民間消費、政府支出。前者大概佔 GDP 的五到六成,畢竟無論現實情勢如何都會有基本消費;後者則因為政府前一年就需訂下預算編列,相對容易掌握。
不過,只要遇上黑天鵝,各項指標皆顯得變幻莫測。
回首過往,911 事件、金融海嘯都曾劇烈衝擊景氣,讓預測誤差明顯擴大。今年,黑天鵝同樣頻頻出沒!周雨田表示,疫情大流行、中美衝突、美國大選等,增加了經濟預測的難度。
所幸,面對黑天鵝,經濟學家並非束手無策。對應之策是參考歷史,像是參照 SARS 來推估新冠疫情對經濟的衝擊程度。
面對高度不確定的狀況,中研院除了發佈「點預測」,也從 2011 年起率先提出「區間預測」。不確定性愈高則區間愈大,彈性應對,預測數據更具參考價值。
今年飛來這麼多隻黑天鵝,預測時會不會特別有壓力?「會也不會,會是因為很難下定論,不會是反正大家都不準,」周雨田露出頑皮的笑容。
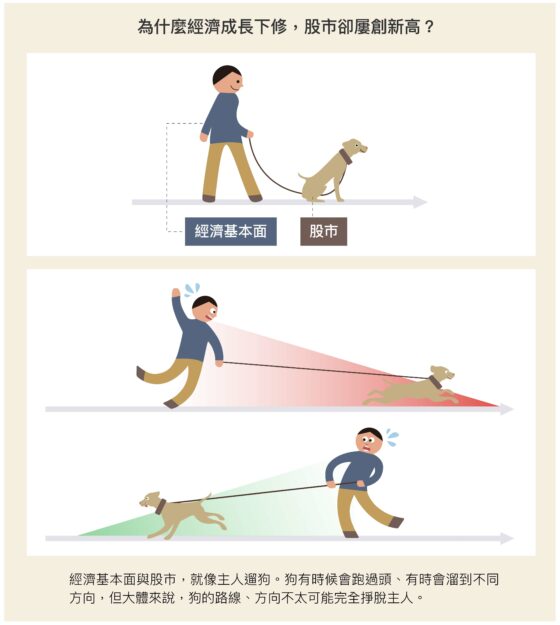
後疫情時代,台灣的經濟前景樂觀嗎?
劇烈震盪的 2020 年,全世界史無前例大規模封城、鎖國,國際貨幣基金組織(IMF)更預測全球衰退將擴大到 4.9%。面對外在嚴峻挑戰,台灣是否能刺激景氣復甦?未來經濟走勢又是如何呢?
談起備受討論的「三倍券」,周雨田表示,目前只能從過往數據推估新政策的效果,主要根據中研院王平院士、彭信坤與簡錦漢對 2009 年消費券成效進行的研究,預測三倍券的邊際消費傾向(Marginal Propensity to Consume, MPC)、替代效果、乘數效果與 GDP 貢獻度。
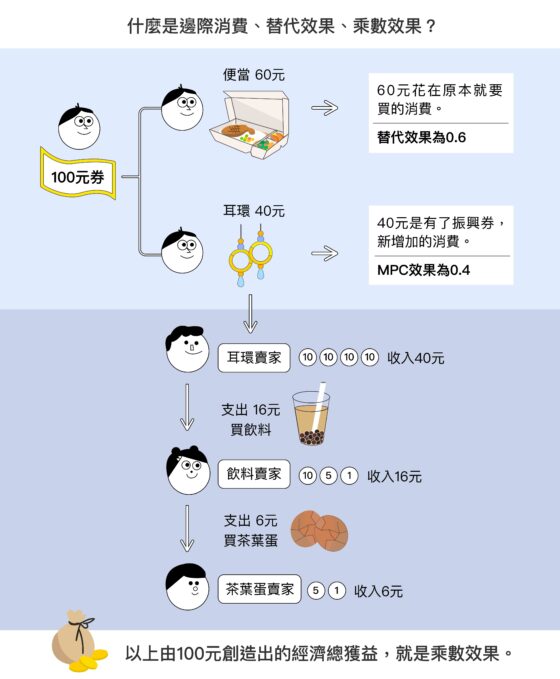
理想的狀況下,替代效果愈低、邊際消費愈高,三倍券的乘數效果愈大。相較於消費券,現在多了數位選擇,消費方式更多樣化,另外民眾若綁信用卡直接折抵,不能衍生第一層後續的消費,就不會有大的乘數效果。
綜合上述因素,周雨田推估三倍券可貢獻 GDP 約 0.2%~0.3%。單從數字看來,刺激經濟效果似乎並不太大?他解釋,部分原因與預算規模有關,三倍券預算約僅占 GDP 的 0.27%,遠小於 2009 年消費券的占比 0.62%,振興方案的效果自然較低。
綜合來說,後疫情時代,台灣的經濟前景將是如何?
「我們並不悲觀!你看全世界,GDP 有 1% 的很少。」周雨田總結,台灣整體經濟、消費者信心逐步回溫中,2020 年的總體經濟成長率預估能破 1%,來到 1.15%。
但不可否認的是,未來仍充滿變數,中美衝突加劇地緣政治風險、下一波疫情、疫苗研發時程,都將牽動景氣。因此周雨田認為,經濟復甦的曲線可能不會是 V 或 U,而是上上下下呈 W 型,這也是今年經濟學界的熱議話題,包括研究團隊內部至今都充滿分歧爭論。
不靠通靈占卜,經濟預測靠的是硬到不行的模型演算,以及經濟學家對現實景況的熱烈論理。下回看到經濟預測,你就知道眼前一條條經濟指標背後,究竟仰賴多少厚實的研究過程與基礎功。

延伸閱讀
本文轉載自中央研究院研之有物,原文為《景氣好、景氣壞,未來經濟怎麼預測?破解經濟學家的「天眼通」!》,泛科學為宣傳推廣執行單位


































