


當貝爾實驗室與 IBM 挾著龐大資源開發數位計算機時,在美國中西部一所以農業為主的學院裡,一位物理教授竟然單槍匹馬,僅憑拮据的經費就要打造出更先進的電子計算機……。
本文為系列文章,上一篇請見:史上第一部全自動的計算機——艾肯與 IBM 的恩怨情仇│《電腦簡史》數位時代(八)
只有 650 美元,卻想打造第一台電子計算機的原型機?
1939年 5 月,當艾肯與 IBM 啟動哈佛馬克一號的開發案時,愛荷華州立大學教授阿塔納索夫也獲得學校補助,加入打造數位計算機的行列。
IBM 有雄厚財力與商業計算機的基礎,另一邊正在開發複數計算機的貝爾實驗室也有龐大研究經費,反觀阿塔納索夫手上的資源卻少得可憐。學校只給了他 650 美元的補助,其中三分之二還是給研究生貝瑞 (Clifford Berry) 的助理津貼。在如此拮据的情況下,阿塔納索夫卻執意不用 IBM 與貝爾實驗室所用的繼電器,而是選擇速度更快,卻也更昂貴的真空管。

阿塔納索夫早就預料經費有限,因此他在一年多前規劃整體架構時,已經琢磨出克難的方案。他降低成本的策略與楚澤設計 V4 時一樣,都是瞄準記憶單元。楚澤用金屬條取代繼電器,阿塔納索夫則是用電容器取代真空管。也就是說,只有運算單元使用真空管,記憶單元全部使用便宜許多的電容器。
研究助理貝瑞原本就是電機系學生,在他的協助下,只花了半年時間,就於 1939 年底完成精簡版的原型機。雖然只有兩組 25 位元的記憶單元,運算單元也只有 13 個真空管,但運作結果證明了阿塔納索夫的構想可行,學校也同意新的年度再撥給他 700 美元繼續打造。
這筆錢當然仍遠遠不足,因此阿塔納索夫又向 IBM 等商用計算機公司投遞計劃書,卻都石沉大海。後來終於在 1941 年 3 月,有一個基金會願意贊助五千美元,這部計算機才得以在 1941 年底打造完成。
使用真空管與電容器,第一部電子計算機問世
阿塔納索夫一開始就是為了計算線性代數,才設計出這部計算機。它的原理是透過加減運算,逐步消去變數與方程式,最後得出答案,因此運算單元與控制單元相對簡單。完工後的機器尺寸並不大,約莫一張書桌大小,重 320 公斤,只用了 280 個真空管。最多可解 29 個變數的線性方程組。
記憶單元的主體構造是兩個直徑 20 公分的滾筒,各有 1,600 個電容器分布在滾筒表面。橫置的滾筒每秒轉一圈,表面的電容器經過電刷時,完成讀取資料與重新充電。這就是 1937 年底,阿塔納索夫在酒吧靈光一閃,冒出腦海的解決方案。
輸入裝置與艾肯和史提畢茲的設計一樣,利用 IBM 現有的打孔卡片,輸入程式與數據。輸出裝置就相當特殊,真的可以用很「炫」來形容。它是讓特製的卡片經過兩個電極之間,用五千伏特的電弧在卡片上灼燒出許多細小的洞,來記錄計算結果。
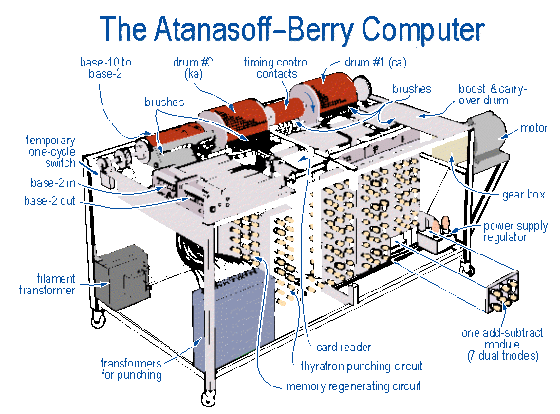
貝爾實驗室與 IBM 在這個時期所開發的計算機仍是用繼電器,雖然傳遞的是電子訊號,但繼電器的開關是機械動作,唯獨阿塔納索夫這部計算機全程用電子訊號進行二進位的運算。所以當它於 1942 年初成功解出有 10 個變數的線性方程組,也立下一個重要的里程碑,成為第一部完成運算的電子計算機。
有些人認為它並不純然是電子式,因為滾筒轉動是機械式的。不過這個說法並不公允,因為現代電腦所用的硬碟,裡面讀取頭的動作也是機械式,但我們並不會因此就說現代電腦不是電子式計算機。
二戰中斷研發,兩人各奔前程,留下的 ABC 電腦成歷史灰燼
當然,滾筒大幅拖慢了運算速度也是事實,不過要再提高滾筒轉速應該沒有太大問題,運算速度也就可以提升了。另外輸出裝置也須要再做改善;在實際運作時,電弧偶而會有偏差,沒有打在卡片上的正確位置,而輸出錯誤的答案。這可以設法增進放電的精確度,或放寬孔洞之間的距離,甚至乾脆放棄電弧,改用別種方式貯存計算結果,來確保記錄正確。
只不過就算阿塔納索夫與貝瑞有任何想法,也都來不及再加以改善了。1942 年中,他們兩人都被徵召入伍,不得不離開校園。阿塔納索夫到海軍的武器實驗室服役,二次大戰結束後,與朋友共同創立一家武器研發公司,直到 1961 年退休,從事青少年的電腦教育工作。
貝瑞則是到一家國防相關的企業研發光譜儀,退役後仍繼續留任,不料卻在 1963 年自殺身亡。為了紀念貝瑞,阿塔納索夫從此將他們研發的計算機稱為「阿塔納索夫–貝瑞電腦」 (Atanasoff – Berry Computer,簡稱 ABC)。

其實阿塔納索夫本來沒有機會將 ABC 這名稱告訴全世界,因為外界從來不知道他們發明出第一部電子計算機。由於愛荷華州是個農業州,工商業並不發達,與科技界原本就沒什麼交集。而愛荷華州立大學當時只是農業與工藝學院,在科學研發方面又不受外界關注。以致於整個 40 年代,只有三篇短短的新聞稿報導過他們開發的電腦。
阿塔納索夫與貝瑞離開後,留在物理館地下室的機器逐漸蒙塵敗壞,後來整個愛荷華州立大學也沒人知曉它的用途,就被拆解丟棄了。最後只留下一個插滿電容器的滾筒,見證它曾經存在。因此除了少數人,世人根本不知道有這麼這一台機器。
阿塔納索夫自己也只把打造 ABC 當成一個有趣的經驗,不值得大肆宣揚。事實上,當年他向基金會申請到補助後,曾經順便將文件複本寄給學校特約的專利律師,但不知是學校並不積極跟催,或是戰爭的影響,專利申請一直沒有送出去。阿塔納索夫自己也覺得無所謂,沒繼續追問,可見他完全沒察覺自己的發明所蘊含的重要性與價值。
第一部通用型電子計算機 ENIAC,研發竟涉嫌剽竊自 ABC?
沒想到原本已在電腦史上石沉大海的 ABC,竟在 1967 年春出現了轉機。阿塔納索夫也才知道自己錯失了什麼。
原來漢威聯合 (Honeywell) 等大型電腦公司都被索討專利授權金,而當初取得專利的莫奇利 (John Mauchly) 所憑藉的,是他所設計出第一部通用型電子計算機 ENIAC。但莫奇利是在拜訪阿塔納索夫,研究過 ABC 之後,才打造出 ENIAC。因此漢威聯合的律師希望阿塔納索夫能出庭作證,他們就能主張對方的專利無效。
阿塔納索夫這才驚覺自己不以為意的專利,竟被他一度推心置腹的莫奇利拔得頭籌。想當初自己熱心地招待莫奇利住在家中,讓他檢視建造中的計算機,還把整份文件攤給他看,結果他竟然獨享利益與光環。忿忿不平的阿塔納索夫當然樂意出庭作證,至少要讓世人知曉他與死去的戰友所打造的 ABC,才是第一部通用型電子計算機。
差點成歷史灰燼的 ABC,終於因為這件官司而受到矚目,得以載於史冊。至於判決結果如何、ENIAC 究竟與 ABC 有無關係、莫奇利又是怎麼踏上這條路的,就待下一章分曉了。






































{kind=link}
{kind=link}
{kind=link}