科學家讓木乃伊發出聲音啦!
木乃伊真是神秘又令人著迷的存在,研究者三不五時把他們抓來玩(誤)好像也就不太奇怪 ,比如說採採他們的 DNA 啦、重建個臉啦、讓他發出個聲音啦(大驚)
沒錯,就是讓他發出聲音!今年初,來自倫敦大學皇家霍洛威學院 (Royal Holloway, University of London) 的研究團隊運用 3D 列印的方式,為一具 3,000 多歲的木乃伊 Nesyamun 重建了聲道,還讓他成功發出了聲音!
什麼?三千年前的屍體還能發聲!?
還請大家莫急莫慌莫害怕,木乃伊並不是本人爬起來發出聲音了,研究者用的方式稍微迂迴了一些,請容我為各位解釋解釋。

想要重建木乃伊的聲音,首先,你需要非常精準的電腦斷層掃描技術(Computed Tomography,以下簡稱 CT),以掃瞄出完整的聲道結構。每個人的聲道都不盡相同,而這些不同,也造就了每個人獨特的嗓音。
經由 CT,科學家確認了這個木乃伊的聲道結構,雖然他的舌頭早已乾燥萎縮,軟顎也已經消失了,但喉嚨等部位都完整地保留了下來,因此提供了足夠的資訊進行接下來的模擬。
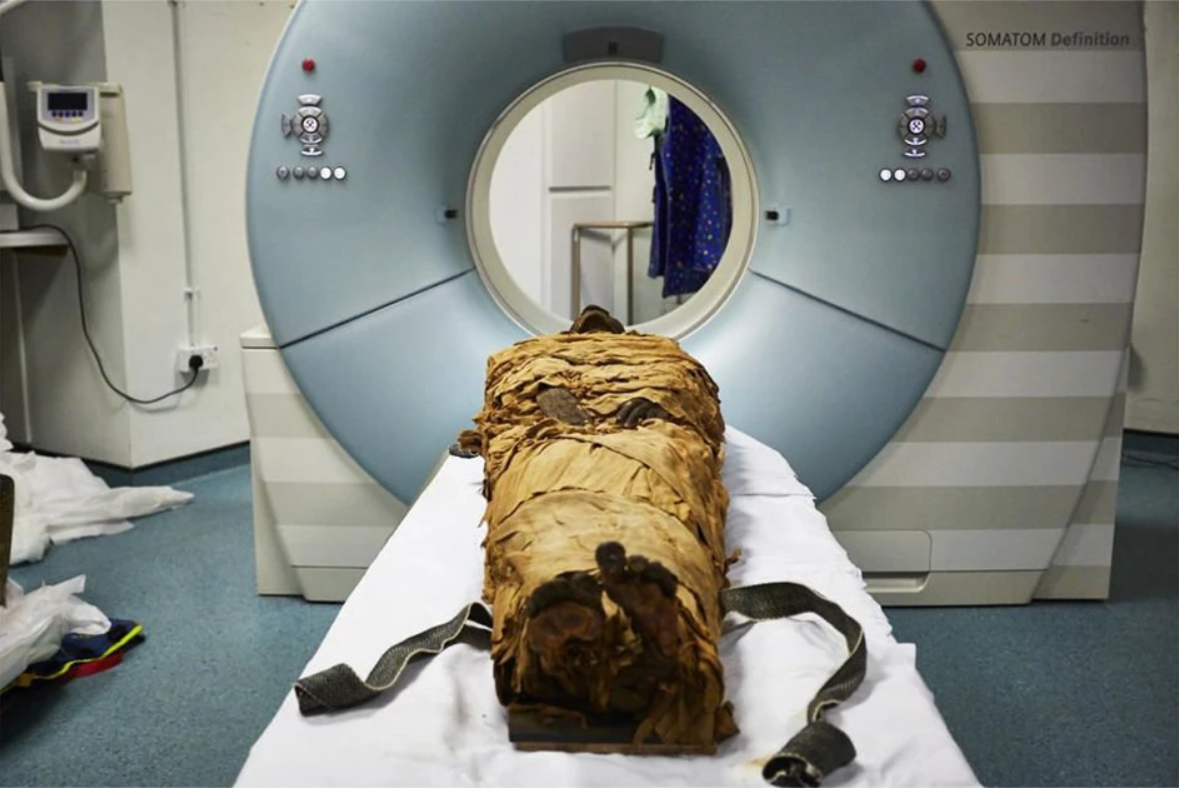
用 3D 列印開啟木乃伊的發聲練習!
掃描之後,科學家們利用 3D 列印的技術將木乃伊的聲道給印了出來,而後運用語音合成樂器「Vocal Tract Organ」去模擬出語音。這個樂器有兩種使用方法,第一種是將它當作和弦樂器使用,並利用數位介面音樂鍵盤彈奏;第二種方式呢,則是將它變成可以透過 Arduino 處理的嵌入式系統,而後以兩根操縱桿進行演奏。
那這個樂器跟 3D 列印出的聲道是如何結合的呢?第一步,先拿出喇叭,喇叭的一端連結 3D 聲道的喉嚨端,另一端則連結電腦。接著,研究團隊用「Vocal Tract Organ」模擬出聲音,並讓聲音透過喇叭進入 3D 聲道,進而讓木乃伊發出聲音。

不過,雖然將整個聲道都給印出來了,研究者們目前卻只能讓他發出一個短促母音,這聲音介於英文的「bed」、「bad」兩個音之間。(作者表示:我覺得聽起來好像也介於「呃」跟「恩」之間)
歷經各種科學實驗,身經百戰的古埃及祭司
說到這裡,就不得不談談這次實驗的主角──Nesyamun,他可真是走在科研最前端的木乃伊之一。他最早是在西元 1824 年被解開,並由外科醫生和化學家進行了相關研究。等到 X 光發明之後呢,他從 1931 年開始陸續經過數次 X 光檢測。1990 年更經歷了一次完整「健檢」,包含內視鏡檢查法、組織檢查、X 光檢測、早期 CT 檢測等等。
這種種的檢查,讓我們知道 Nesyamun 是在 50 多歲死亡的。他的棺木上刻著名字,不過在破譯的過程中輾轉有了各式各樣的名字(破解的時候總是要多方嘗試的,你知道),直到最後才確定了他真正的名字應該是 Nesyamun。
Nesyamun 生在法老拉美西斯十一世 (Ramses XI) 在位期間,當時的政治情勢十分動盪不安。他生前是一位祭司與抄寫員,某個程度上來說,稱得上是半個靠聲音吃飯的人,需要不斷地使用聲音來進行禱告和吟唱等日常祭祀活動。
他的死亡原因可能是嚴重的過敏反應,他的身上也有其他病痛的痕跡,包含牙周炎和嚴重磨損的牙齒,而他目前的安歇之處則是英國的里兹城市博物館 (Leeds City Museum)。

用看的還不夠,期待聖地巡遊能有視聽雙重享受
認識了 Nesyamun 後,你可能會對實驗產生一些疑慮:這木乃伊躺在那兒幾千年了,把人家挖出來還讓人家發出聲音是不是不太好啊?
對此,科學家們煞費苦心地解釋了一番,在整個研究的過程中,所使用的方法都是非侵入式的,所以並沒有損及木乃伊本身。而在古埃及人的信仰中,深信「說出死者之名能讓他們重新活過來」,Nesyamun 更是在陪葬物中表明了,他希望自己的聲音在死後也能被聽見,好獲得永生。可以說研究團隊採用了最新的技術,間接地為他完成了遺願。
另一方面,光讓木乃伊發出單音還不夠,研究團隊更希望可以完整重建出一段語音,像是古埃及禱文等內容,以便在卡納克神廟 (Karnak temple) 等觀光勝地播放,如此一來,遊客們參觀時不僅可以看見過去的文物,更能聆聽來自古老時代的聲音,想必能讓體驗更加完整。
你想要聽見木乃伊為你朗誦什麼內容呢?

本篇文章是《法科地史 Focus This》的合作企劃文章!
由【法律白話文運動】X 【PanSci 泛科學】X【地球圖輯隊】X【故事StoryStudio】共同協力!
如果想看我們家的文章在地球圖輯隊網站的樣子,點這裡!
也快去看看地球圖輯隊超級精彩的七月關鍵字《埃及》!
參考資料
- Howard, D.M., Schofield, J., Fletcher, J. et al. Synthesis of a Vocal Sound from the 3,000 year old Mummy, Nesyamun ‘True of Voice’. Sci Rep 10, 45000 (2020). https://doi.org/10.1038/s41598-019-56316-y
- Howard DM. The Vocal Tract Organ: A New Musical Instrument Using 3-D Printed Vocal Tracts. J Voice. 2018;32(6):660-667. doi:10.1016/j.jvoice.2017.09.014
- The Mummy Speaks! Hear Sounds From the Voice of an Ancient Egyptian Priest The New York Times