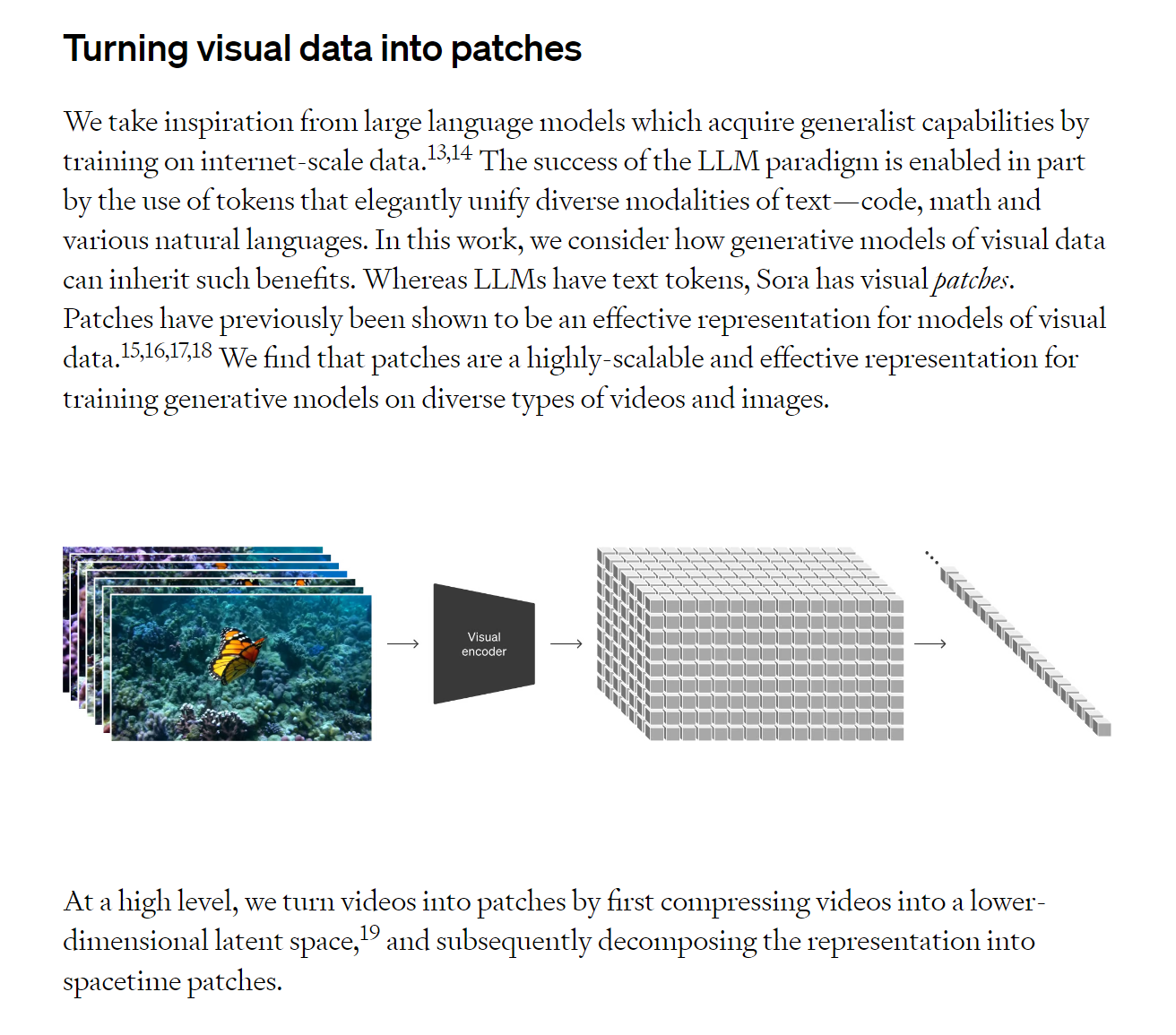
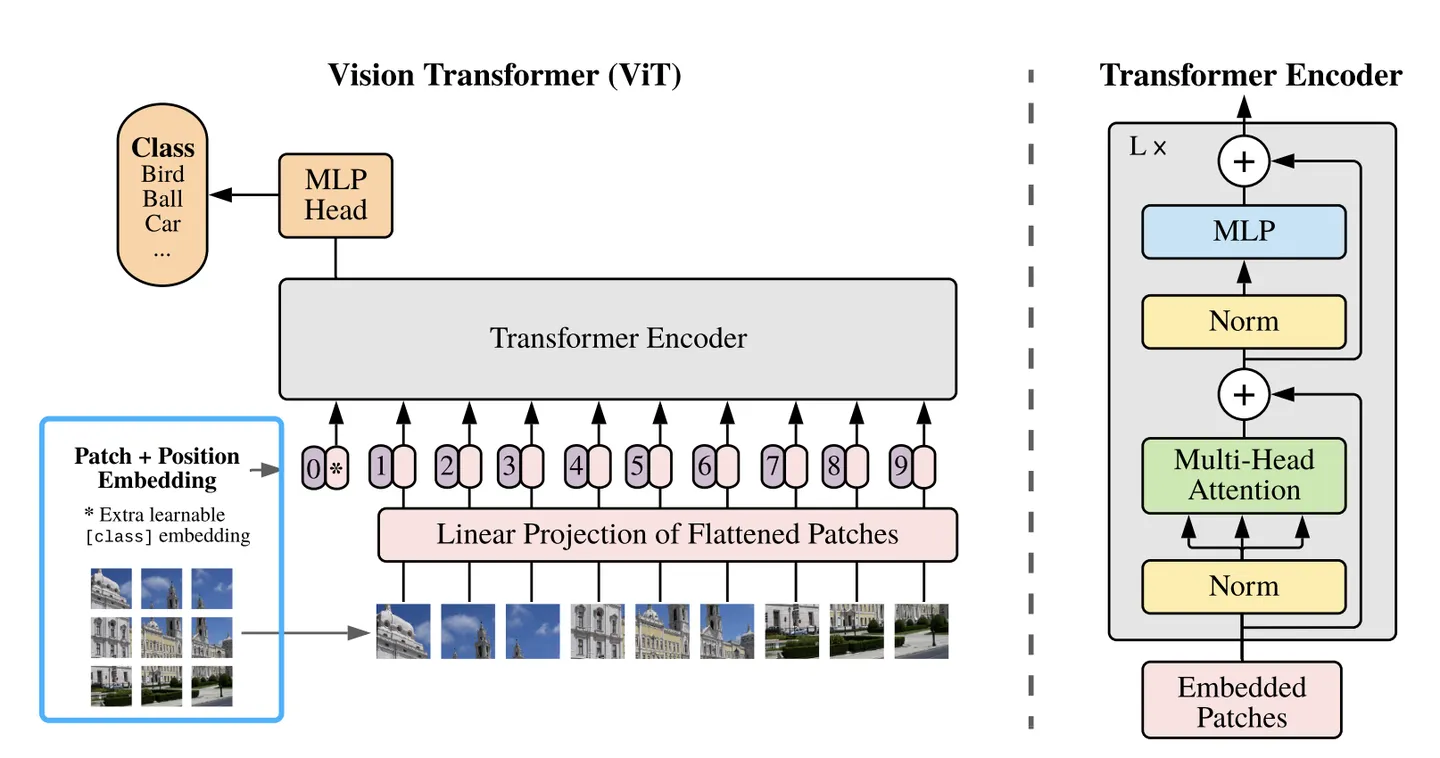
這邊是我的推測,影片中那些逼真的物理效果,不是有特定的物理模型或遊戲引擎在輔助,而是在 patch 的訓練與序列推理中,就讓 Sora 理解到要讓物體這樣動,看起來才會是真實的,這跟 GPT-4 並不需要文法引擎是一樣的,只要玩文字接龍,就能生成流暢又有邏輯的文字跟代碼。但這也是為什麼,GPT 依舊很會胡說八道,產生幻覺。如果不是這樣,我很難想像 Sora 會算出這種影片。
Sora 能理解並產生人類眼睛能接收的視覺影片,同樣的技術若能做出聽覺、觸覺等其他人類感官,這樣我們被 AI 豢養的時刻是不是就越來越近了呢?
後 Sora 時代到底會發生什麼事,老實講我不知道,上面提到的 diffusion transformer 或 patch,都是近一年,甚至是幾個月前才有研究成果的東西。
臉書母公司 Meta 的首席人工智慧科學家 Yann Lecun 也在他自己的臉書公開抨擊 Sora 這種基於像素預測的技術註定失敗,但這篇感覺比較像是對自己的老闆 Zuckerberg 喊話:「欸這沒戲,不要叫我學 Sora,拿寶貴的運算資源去搞你的元宇宙。」是說今年初就有新聞說祖老闆 2024 年預計買超過 35 萬顆 H100 處理器,這明顯就是要搞一波大的吧,這就是我想要的血流成河。
-----廣告,請繼續往下閱讀-----
而且,從去年 ChatGPT 出來開始,我感覺就已經不是討論 AI 會怎麼發展,而是要接受 AI 必定會發展得越來越快,我們要怎麼面對 AI 帶來的機會與衝擊。
我們去年成立泛科學院,就是希望跟大家一起,透過簡單易懂的教學影片,把對 AI 的陌生跟恐慌,變成好奇與駕馭自如。Sora 或類似的模型應該可以協助我把這件事做得更好,可惜的的是目前 OpenAI 僅開放 Sora 給內部的 AI 安全團隊評估工具可能帶來的危害與風險,另外就是與少數外部特定的藝術家、設計師跟電影製片人確保模型用於創意專業領域的實際應用,若有新消息,我會再即時更新。